
 Одной из самых трудоемких и неприятных задач при работе с текстом в Excel является парсинг — разбор буквенно-цифровой «каши» на составляющие и извлечение из нее нужных нам фрагментов. Например:
Одной из самых трудоемких и неприятных задач при работе с текстом в Excel является парсинг — разбор буквенно-цифровой «каши» на составляющие и извлечение из нее нужных нам фрагментов. Например:
- извлечение почтового индекса из адреса (хорошо, если индекс всегда в начале, а если нет?)
- нахождение номера и даты счета из описания платежа в банковской выписке
- извлечение ИНН из разношерстных описаний компаний в списке контрагентов
- поиск номера автомобиля или артикула товара в описании и т.д.
Обычно во подобных случаях, после получасового муторного ковыряния в тексте вручную, в голову начинают приходить мысли как-то автоматизировать этот процесс (особенно если данных много). Решений тут несколько и с разной степенью сложности-эффективности:
- Использовать встроенные текстовые функции Excel для поиска-нарезки-склейки текста: ЛЕВСИМВ (LEFT), ПРАВСИМВ (RIGHT), ПСТР (MID), СЦЕПИТЬ (CONCATENATE) и ее аналоги, ОБЪЕДИНИТЬ (JOINTEXT), СОВПАД (EXACT) и т.д. Этот способ хорош, если в тексте есть четкая логика (например, индекс всегда в начале адреса). В противном случае формулы существенно усложняются и, порой, дело доходит даже до формул массива, что сильно тормозит на больших таблицах.
- Использование оператора проверки текстового подобия Like из Visual Basic, обернутого в пользовательскую макро-функцию. Это позволяет реализовать более гибкий поиск с использованием символов подстановки (*,#,? и т.д.) К сожалению, этот инструмент не умеет извлекать нужную подстроку из текста — только проверять, содержится ли она в нем.
Кроме вышеперечисленного, есть еще один подход, очень известный в узких кругах профессиональных программистов, веб-разработчиков и прочих технарей — это регулярные выражения (Regular Expressions = RegExp = «регэкспы» = «регулярки»). Упрощенно говоря, RegExp — это язык, где с помощью специальных символов и правил производится поиск нужных подстрок в тексте, их извлечение или замена на другой текст. Регулярные выражения — это очень мощный и красивый инструмент, на порядок превосходящий по возможностям все остальные способы работы с текстом. Многие языки программирования (C#, PHP, Perl, JavaScript…) и текстовые редакторы (Word, Notepad++…) поддерживают регулярные выражения.
Microsoft Excel, к сожалению, не имеет поддержки RegExp по-умолчанию «из коробки», но это легко исправить с помощью VBA. Откройте редактор Visual Basic с вкладки Разработчик (Developer) или сочетанием клавиш Alt+F11. Затем вставьте новый модуль через меню Insert — Module и скопируйте туда текст вот такой макрофункции:
Public Function RegExpExtract(Text As String, Pattern As String, Optional Item As Integer = 1) As String
On Error GoTo ErrHandl
Set regex = CreateObject("VBScript.RegExp")
regex.Pattern = Pattern
regex.Global = True
If regex.Test(Text) Then
Set matches = regex.Execute(Text)
RegExpExtract = matches.Item(Item - 1)
Exit Function
End If
ErrHandl:
RegExpExtract = CVErr(xlErrValue)
End Function
Теперь можно закрыть редактор Visual Basic и, вернувшись в Excel, опробовать нашу новую функцию. Синтаксис у нее следующий:
=RegExpExtract( Txt ; Pattern ; Item )
где
- Txt — ячейка с текстом, который мы проверяем и из которого хотим извлечь нужную нам подстроку
- Pattern — маска (шаблон) для поиска подстроки
- Item — порядковый номер подстроки, которую надо извлечь, если их несколько (если не указан, то выводится первое вхождение)
Самое интересное тут, конечно, это Pattern — строка-шаблон из спецсимволов «на языке» RegExp, которая и задает, что именно и где мы хотим найти. Вот самые основные из них — для начала:
| Паттерн | Описание |
| . | Самое простое — это точка. Она обозначает любой символ в шаблоне на указанной позиции. |
| s | Любой символ, выглядящий как пробел (пробел, табуляция или перенос строки). |
| S | Анти-вариант предыдущего шаблона, т.е. любой НЕпробельный символ. |
| d | Любая цифра |
| D | Анти-вариант предыдущего, т.е. любая НЕ цифра |
| w | Любой символ латиницы (A-Z), цифра или знак подчеркивания |
| W | Анти-вариант предыдущего, т.е. не латиница, не цифра и не подчеркивание. |
| [символы] |
В квадратных скобках можно указать один или несколько символов, разрешенных на указанной позиции в тексте. Например ст[уо]л будет соответствовать любому из слов: стол или стул. Также можно не перечислять символы, а задать их диапазоном через дефис, т.е. вместо [ABDCDEF] написать [A-F]. или вместо [4567] ввести [4-7]. Например, для обозначения всех символов кириллицы можно использовать шаблон [а-яА-ЯёЁ]. |
| [^символы] | Если после открывающей квадратной скобки добавить символ «крышки» ^, то набор приобретет обратный смысл — на указанной позиции в тексте будут разрешены все символы, кроме перечисленных. Так, шаблон [^ЖМ]уть найдет Путь или Суть или Забудь, но не Жуть или Муть, например. |
| | | Логический оператор ИЛИ (OR) для проверки по любому из указанных критериев. Например (счет|счёт|invoice) будет искать в тексте любое из указанных слов. Обычно набор вариантов заключается в скобки. |
| ^ | Начало строки |
| $ | Конец строки |
| b | Край слова |
Если мы ищем определенное количество символов, например, шестизначный почтовый индекс или все трехбуквенные коды товаров, то на помощь нам приходят квантификаторы или кванторы — специальные выражения, задающие количество искомых знаков. Квантификаторы применяются к тому символу, что стоит перед ним:
| Квантор | Описание |
| ? | Ноль или одно вхождение. Например .? будет означать один любой символ или его отсутствие. |
| + | Одно или более вхождений. Например d+ означает любое количество цифр (т.е. любое число от 0 до бесконечности). |
| * | Ноль или более вхождений, т.е. любое количество. Так s* означает любое количество пробелов или их отсутствие. |
|
{число} или {число1,число2} |
Если нужно задать строго определенное количество вхождений, то оно задается в фигурных скобках. Например d{6} означает строго шесть цифр, а шаблон s{2,5} — от двух до пяти пробелов |
Теперь давайте перейдем к самому интересному — разбору применения созданной функции и того, что узнали о паттернах на практических примерах из жизни.
Извлекаем числа из текста
Для начала разберем простой случай — нужно извлечь из буквенно-цифровой каши первое число, например мощность источников бесперебойного питания из прайс-листа:

Логика работы регулярного выражения тут простая: d — означает любую цифру, а квантор + говорит о том, что их количество должно быть одна или больше. Двойной минус перед функцией нужен, чтобы «на лету» преобразовать извлеченные символы в полноценное число из числа-как-текст.
Почтовый индекс
На первый взгляд, тут все просто — ищем ровно шесть цифр подряд. Используем спецсимвол d для цифры и квантор {6} для количества знаков:

Однако, возможна ситуация, когда левее индекса в строке стоит еще один большой набор цифр подряд (номер телефона, ИНН, банковский счет и т.д.) Тогда наша регулярка выдернет из нее первых 6 цифр, т.е. сработает некорректно:

Чтобы этого не происходило, необходимо добавить в наше регулярное выражение по краям модификатор b означающий конец слова. Это даст понять Excel, что нужный нам фрагмент (индекс) должен быть отдельным словом, а не частью другого фрагмента (номера телефона):

Телефон
Проблема с нахождением телефонного номера среди текста состоит в том, что существует очень много вариантов записи номеров — с дефисами и без, через пробелы, с кодом региона в скобках или без и т.д. Поэтому, на мой взгляд, проще сначала вычистить из исходного текста все эти символы с помощью нескольких вложенных друг в друга функций ПОДСТАВИТЬ (SUBSTITUTE), чтобы он склеился в единое целое, а потом уже примитивной регуляркой d{11} вытаскивать 11 цифр подряд:

ИНН
Тут чуть сложнее, т.к. ИНН (в России) бывает 10-значный (у юрлиц) или 12-значный (у физлиц). Если не придираться особо, то вполне можно удовлетвориться регуляркой d{10,12}, но она, строго говоря, будет вытаскивать все числа от 10 до 12 знаков, т.е. и ошибочно введенные 11-значные. Правильнее будет использовать два шаблона, связанных логическим ИЛИ оператором | (вертикальная черта):

Обратите внимание, что в запросе мы сначала ищем 12-разрядные, и только потом 10-разрядные числа. Если же записать нашу регулярку наоборот, то она будет вытаскивать для всех, даже длинных 12-разрядных ИНН, только первые 10 символов. То есть после срабатывания первого условия дальнейшая проверка уже не производится:

Это принципиальное отличие оператора | от стандартной экселевской логической функции ИЛИ (OR), где от перестановки аргументов результат не меняется.
Артикулы товаров
Во многих компаниях товарам и услугам присваиваются уникальные идентификаторы — артикулы, SAP-коды, SKU и т.д. Если в их обозначениях есть логика, то их можно легко вытаскивать из любого текста с помощью регулярных выражений. Например, если мы знаем, что наши артикулы всегда состоят из трех заглавных английских букв, дефиса и последующего трехразрядного числа, то:

Логика работы шаблона тут проста. [A-Z] — означает любые заглавные буквы латиницы. Следующий за ним квантор {3} говорит о том, что нам важно, чтобы таких букв было именно три. После дефиса мы ждем три цифровых разряда, поэтому добавляем на конце d{3}
Денежные суммы
Похожим на предыдущий пункт образом, можно вытаскивать и цены (стоимости, НДС…) из описания товаров. Если денежные суммы, например, указываются через дефис, то:
 из текста")
Паттерн d с квантором + ищет любое число до дефиса, а d{2} будет искать копейки (два разряда) после.
Если нужно вытащить не цены, а НДС, то можно воспользоваться третьим необязательным аргументом нашей функции RegExpExtract, задающим порядковый номер извлекаемого элемента. И, само-собой, можно заменить функцией ПОДСТАВИТЬ (SUBSTITUTE) в результатах дефис на стандартный десятичный разделитель и добавить двойной минус в начале, чтобы Excel интерпретировал найденный НДС как нормальное число:

Автомобильные номера
Если не брать спецтранспорт, прицепы и прочие мотоциклы, то стандартный российский автомобильный номер разбирается по принципу «буква — три цифры — две буквы — код региона». Причем код региона может быть 2- или 3-значным, а в качестве букв применяются только те, что похожи внешне на латиницу. Таким образом, для извлечения номеров из текста нам поможет следующая регулярка:

Время
Для извлечения времени в формате ЧЧ:ММ подойдет такое регулярное выражение:

После двоеточия фрагмент [0-5]d, как легко сообразить, задает любое число в интервале 00-59. Перед двоеточием в скобках работают два шаблона, разделенных логическим ИЛИ (вертикальной чертой):
- [0-1]d — любое число в интервале 00-19
- 2[0-3] — любое число в интервале 20-23
К полученному результату можно применить дополнительно еще и стандартную Excel’евскую функцию ВРЕМЯ (TIME), чтобы преобразовать его в понятный программе и пригодный для дальнейших расчетов формат времени.
Проверка пароля
Предположим, что нам надо проверить список придуманных пользователями паролей на корректность. По нашим правилам, в паролях могут быть только английские буквы (строчные или прописные) и цифры. Пробелы, подчеркивания и другие знаки препинания не допускаются.
Проверку можно организовать с помощью вот такой несложной регулярки:

По сути, таким шаблоном мы требуем, чтобы между началом (^) и концом ($) в нашем тексте находились только символы из заданного в квадратных скобках набора. Если нужно проверить еще и длину пароля (например, не меньше 6 символов), то квантор + можно заменить на интервал «шесть и более» в виде {6,}:

Город из адреса
Допустим, нам нужно вытащить город из строки адреса. Поможет регулярка, извлекающая текст от «г.» до следующей запятой:

Давайте разберем этот шаблон поподробнее.
Если вы прочитали текст выше, то уже поняли, что некоторые символы в регулярных выражениях (точки, звездочки, знаки доллара и т.д.) несут особый смысл. Если же нужно искать сами эти символы, то перед ними ставится обратная косая черта (иногда это называют экранированием). Поэтому при поиске фрагмента «г.» мы должны написать в регулярке г. если ищем плюсик, то + и т.д.
Следующих два символа в нашем шаблоне — точка и звездочка-квантор — обозначают любое количество любых символов, т.е. любое название города.
На конце шаблона стоит запятая, т.к. мы ищем текст от «г.» до запятой. Но ведь в тексте может быть несколько запятых, правда? Не только после города, но и после улицы, дома и т.д. На какой из них будет останавливаться наш запрос? Вот за это отвечает вопросительный знак. Без него наша регулярка вытаскивала бы максимально длинную строку из всех возможных:

В терминах регулярных выражений, такой шаблон является «жадным». Чтобы исправить ситуацию и нужен вопросительный знак — он делает квантор, после которого стоит, «скупым» — и наш запрос берет текст только до первой встречной запятой после «г.»:

Имя файла из полного пути
Еще одна весьма распространенная ситуация — вытащить имя файла из полного пути. Тут поможет простая регулярка вида:

Тут фишка в том, что поиск, по сути, происходит в обратном направлении — от конца к началу, т.к. в конце нашего шаблона стоит $, и мы ищем все, что перед ним до первого справа обратного слэша. Бэкслэш заэкранирован, как и точка в предыдущем примере.
P.S.
«Под занавес» хочу уточнить, что все вышеописанное — это малая часть из всех возможностей, которые предоставляют регулярные выражения. Спецсимволов и правил их использования очень много и на эту тему написаны целые книги (рекомендую для начала хотя бы эту). В некотором смысле, написание регулярных выражений — это почти искусство. Почти всегда придуманную регулярку можно улучшить или дополнить, сделав ее более изящной или способным работать с более широким диапазоном вариантов входных данных.
Для анализа и разбора чужих регулярок или отладки своих собственных есть несколько удобных онлайн-сервисов: RegEx101, RegExr и др.
К сожалению, не все возможности классических регулярных выражений поддерживаются в VBA (например, обратный поиск или POSIX-классы) и умеют работать с кириллицей, но и того, что есть, думаю, хватит на первое время, чтобы вас порадовать.
Если же вы не новичок в теме, и вам есть чем поделиться — оставляйте полезные при работе в Excel регулярки в комментариях ниже. Один ум хорошо, а два сапога — пара!
Ссылки по теме
- Замена и зачистка текста функцией ПОДСТАВИТЬ (SUBSTITUTE)
- Поиск и подсветка символов латиницы в русском тексте
- Поиск ближайшего похожего текста (Иванов = Ивонов = Иваноф и т.д.)
Для удобства работы с текстом в Excel существуют текстовые функции. Они облегчают обработку сразу сотен строк. Рассмотрим некоторые из них на примерах.
Примеры функции ТЕКСТ в Excel
Преобразует числа в текст. Синтаксис: значение (числовое или ссылка на ячейку с формулой, дающей в результате число); формат (для отображения числа в виде текста).
Самая полезная возможность функции ТЕКСТ – форматирование числовых данных для объединения с текстовыми данными. Без использования функции Excel «не понимает», как показывать числа, и преобразует их в базовый формат.
Покажем на примере. Допустим, нужно объединить текст в строках и числовые значения:

Использование амперсанда без функции ТЕКСТ дает «неадекватный» результат:
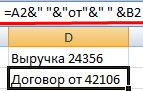
Excel вернул порядковый номер для даты и общий формат вместо денежного. Чтобы избежать подобного результата, применяется функция ТЕКСТ. Она форматирует значения по заданию пользователя.
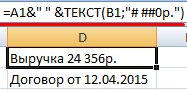
Формула «для даты» теперь выглядит так:
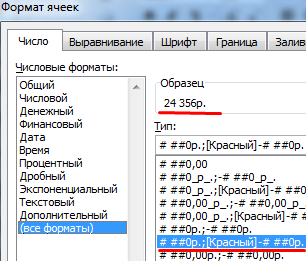
Второй аргумент функции – формат. Где брать строку формата? Щелкаем правой кнопкой мыши по ячейке со значением. Нажимаем «Формат ячеек». В открывшемся окне выбираем «все форматы». Копируем нужный в строке «Тип». Вставляем скопированное значение в формулу.
Приведем еще пример, где может быть полезна данная функция. Добавим нули в начале числа. Если ввести вручную, Excel их удалит. Поэтому введем формулу:
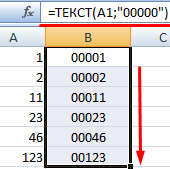
Если нужно вернуть прежние числовые значения (без нулей), то используем оператор «—»:
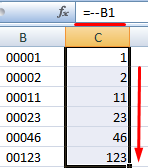
Обратите внимание, что значения теперь отображаются в числовом формате.
Функция разделения текста в Excel
Отдельные текстовые функции и их комбинации позволяют распределить слова из одной ячейки в отдельные ячейки:
- ЛЕВСИМВ (текст; кол-во знаков) – отображает заданное число знаков с начала ячейки;
- ПРАВСИМВ (текст; кол-во знаков) – возвращает заданное количество знаков с конца ячейки;
- ПОИСК (искомый текст; диапазон для поиска; начальная позиция) – показывает позицию первого появления искомого знака или строки при просмотре слева направо
При разделении текста в строке учитывается положение каждого знака. Пробелы показывают начало или конец искомого имени.
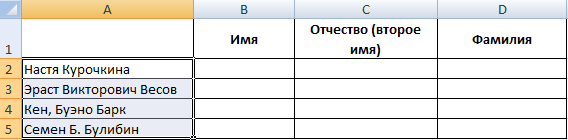
Распределим с помощью функций имя, фамилию и отчество в разные столбцы.
В первой строке есть только имя и фамилия, разделенные пробелом. Формула для извлечения имени: =ЛЕВСИМВ(A2;ПОИСК(» «;A2;1)). Для определения второго аргумента функции ЛЕВСИМВ – количества знаков – используется функция ПОИСК. Она находит пробел в ячейке А2, начиная слева.
Формула для извлечения фамилии:

С помощью функции ПОИСК Excel определяет количество знаков для функции ПРАВСИМВ. Функция ДЛСТР «считает» общую длину текста. Затем отнимается количество знаков до первого пробела (найденное ПОИСКом).
Вторая строка содержит имя, отчество и фамилию. Для имени используем такую же формулу:
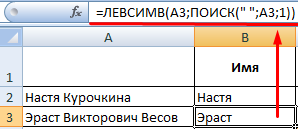
Формула для извлечения фамилии несколько иная: Это пять знаков справа. Вложенные функции ПОИСК ищут второй и третий пробелы в строке. ПОИСК(» «;A3;1) находит первый пробел слева (перед отчеством). К найденному результату добавляем единицу (+1). Получаем ту позицию, с которой будем искать второй пробел.
Часть формулы – ПОИСК(» «;A3;ПОИСК(» «;A3;1)+1) – находит второй пробел. Это будет конечная позиция отчества.
Далее из общей длины строки отнимается количество знаков с начала строки до второго пробела. Результат – число символов справа, которые нужно вернуть.
Формула «для отчества» строится по тем же принципам:

Функция объединения текста в Excel
Для объединения значений из нескольких ячеек в одну строку используется оператор амперсанд (&) или функция СЦЕПИТЬ.
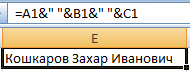
Например, значения расположены в разных столбцах (ячейках):

Ставим курсор в ячейку, где будут находиться объединенные три значения. Вводим равно. Выбираем первую ячейку с текстом и нажимаем на клавиатуре &. Затем – знак пробела, заключенный в кавычки (“ “). Снова — &. И так последовательно соединяем ячейки с текстом и пробелы.
Получаем в одной ячейке объединенные значения:
Использование функции СЦЕПИТЬ:
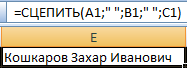
С помощью кавычек в формуле можно добавить в конечное выражение любой знак или текст.
Функция ПОИСК текста в Excel
Функция ПОИСК возвращает начальную позицию искомого текста (без учета регистра). Например:
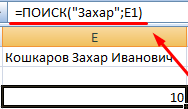
Функция ПОИСК вернула позицию 10, т.к. слово «Захар» начинается с десятого символа в строке. Где это может пригодиться?
Функция ПОИСК определяет положение знака в текстовой строке. А функция ПСТР возвращает текстовые значения (см. пример выше). Либо можно заменить найденный текст посредством функции ЗАМЕНИТЬ.
Скачать пример функции для работы с текстом в Excel
Читайте так же: как перевести число и сумму прописью.
Синтаксис функции ПОИСК:
- «искомый текст» — что нужно найти;
- «просматриваемый текст» — где искать;
- «начальная позиция» — с какой позиции начинать искать (по умолчанию – 1).
Если нужно учитывать регистр, используется функция НАЙТИ.
Skip to content
Рассмотрим использование функции ЕСЛИ в Excel в том случае, если в ячейке находится текст.
- Проверяем условие для полного совпадения текста.
- ЕСЛИ + СОВПАД
- Использование функции ЕСЛИ с частичным совпадением текста.
- ЕСЛИ + ПОИСК
- ЕСЛИ + НАЙТИ
Будьте особо внимательны в том случае, если для вас важен регистр, в котором записаны ваши текстовые значения. Функция ЕСЛИ не проверяет регистр – это делают функции, которые вы в ней используете. Поясним на примере.
Проверяем условие для полного совпадения текста.
Проверку выполнения
доставки организуем при помощи обычного оператора сравнения «=».
=ЕСЛИ(G2=»выполнено»,ИСТИНА,ЛОЖЬ)
При этом будет не важно,
в каком регистре записаны значения в вашей таблице.

Если же вас интересует
именно точное совпадение текстовых значений с учетом регистра, то можно
рекомендовать вместо оператора «=» использовать функцию СОВПАД(). Она проверяет
идентичность двух текстовых значений с учетом регистра отдельных букв.
Вот как это может
выглядеть на примере.

Обратите внимание, что
если в качестве аргумента мы используем текст, то он обязательно должен быть
заключён в кавычки.
ЕСЛИ + СОВПАД
В случае, если нас интересует полное совпадение текста с заданным условием, включая и регистр его символов, то оператор «=» нам не сможет помочь.
Но мы можем использовать функцию СОВПАД (английский аналог — EXACT).
Функция СОВПАД сравнивает два текста и возвращает ИСТИНА в случае их полного совпадения, и ЛОЖЬ — если есть хотя бы одно отличие, включая регистр букв. Поясним возможность ее использования на примере.
Формула проверки выполнения заказа в столбце Н может выглядеть следующим образом:
=ЕСЛИ(СОВПАД(G2,»Выполнено»),»Да»,»Нет»)

Как видите, варианты «ВЫПОЛНЕНО» и «выполнено» не засчитываются как правильные. Засчитываются только полные совпадения. Будет полезно, если важно точное написание текста — например, в артикулах товаров.
Использование функции ЕСЛИ с частичным совпадением текста.
Выше мы с вами
рассмотрели, как использовать текстовые значения в функции ЕСЛИ. Но часто случается,
что необходимо определить не полное, а частичное совпадение текста с каким-то
эталоном. К примеру, нас интересует город, но при этом совершенно не важно его
название.
Первое, что приходит на
ум – использовать подстановочные знаки «?» и «*» (вопросительный знак и
звездочку). Однако, к сожалению, этот простой способ здесь не проходит.
ЕСЛИ + ПОИСК
Нам поможет функция ПОИСК (в английском варианте – SEARCH). Она позволяет определить позицию, начиная с которой искомые символы встречаются в тексте. Синтаксис ее таков:
=ПОИСК(что_ищем, где_ищем, начиная_с_какого_символа_ищем)
Если третий аргумент не
указан, то поиск начинаем с самого начала – с первого символа.
Функция ПОИСК возвращает либо номер позиции, начиная с которой искомые символы встречаются в тексте, либо ошибку.
Но нам для использования в функции ЕСЛИ нужны логические значения.
Здесь нам на помощь приходит еще одна функция EXCEL – ЕЧИСЛО. Если ее аргументом является число, она возвратит логическое значение ИСТИНА. Во всех остальных случаях, в том числе и в случае, если ее аргумент возвращает ошибку, ЕЧИСЛО возвратит ЛОЖЬ.
В итоге наше выражение в
ячейке G2
будет выглядеть следующим образом:
=ЕСЛИ(ЕЧИСЛО(ПОИСК(«город»,B2)),»Город»,»»)
Еще одно важное уточнение. Функция ПОИСК не различает регистр символов.

ЕСЛИ + НАЙТИ
В том случае, если для нас важны строчные и прописные буквы, то придется использовать вместо нее функцию НАЙТИ (в английском варианте – FIND).
Синтаксис ее совершенно аналогичен функции ПОИСК: что ищем, где ищем, начиная с какой позиции.
Изменим нашу формулу в
ячейке G2
=ЕСЛИ(ЕЧИСЛО(НАЙТИ(«город»,B2)),»Да»,»Нет»)

То есть, если регистр символов для вас важен, просто замените ПОИСК на НАЙТИ.
Итак, мы с вами убедились, что простая на первый взгляд функция ЕСЛИ дает нам на самом деле много возможностей для операций с текстом.
[the_ad_group id=»48″]
Примеры использования функции ЕСЛИ:
 Функция ЕСЛИОШИБКА – примеры формул — В статье описано, как использовать функцию ЕСЛИОШИБКА в Excel для обнаружения ошибок и замены их пустой ячейкой, другим значением или определённым сообщением. Покажем примеры, как использовать функцию ЕСЛИОШИБКА с функциями визуального…
Функция ЕСЛИОШИБКА – примеры формул — В статье описано, как использовать функцию ЕСЛИОШИБКА в Excel для обнаружения ошибок и замены их пустой ячейкой, другим значением или определённым сообщением. Покажем примеры, как использовать функцию ЕСЛИОШИБКА с функциями визуального…  Сравнение ячеек в Excel — Вы узнаете, как сравнивать значения в ячейках Excel на предмет точного совпадения или без учета регистра. Мы предложим вам несколько формул для сопоставления двух ячеек по их значениям, длине или количеству…
Сравнение ячеек в Excel — Вы узнаете, как сравнивать значения в ячейках Excel на предмет точного совпадения или без учета регистра. Мы предложим вам несколько формул для сопоставления двух ячеек по их значениям, длине или количеству…  Вычисление номера столбца для извлечения данных в ВПР — Задача: Наиболее простым способом научиться указывать тот столбец, из которого функция ВПР будет извлекать данные. При этом мы не будем изменять саму формулу, поскольку это может привести в случайным ошибкам.…
Вычисление номера столбца для извлечения данных в ВПР — Задача: Наиболее простым способом научиться указывать тот столбец, из которого функция ВПР будет извлекать данные. При этом мы не будем изменять саму формулу, поскольку это может привести в случайным ошибкам.… 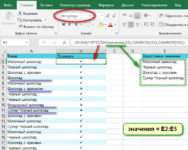 Как проверить правильность ввода данных в Excel? — Подтверждаем правильность ввода галочкой. Задача: При ручном вводе данных в ячейки таблицы проверять правильность ввода в соответствии с имеющимся списком допустимых значений. В случае правильного ввода в отдельном столбце ставить…
Как проверить правильность ввода данных в Excel? — Подтверждаем правильность ввода галочкой. Задача: При ручном вводе данных в ячейки таблицы проверять правильность ввода в соответствии с имеющимся списком допустимых значений. В случае правильного ввода в отдельном столбце ставить… 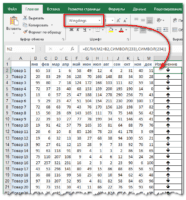 Визуализация данных при помощи функции ЕСЛИ — Функцию ЕСЛИ можно использовать для вставки в таблицу символов, которые наглядно показывают происходящие с данными изменения. К примеру, мы хотим показать в отдельной колонке таблицы, происходит рост или снижение продаж.…
Визуализация данных при помощи функции ЕСЛИ — Функцию ЕСЛИ можно использовать для вставки в таблицу символов, которые наглядно показывают происходящие с данными изменения. К примеру, мы хотим показать в отдельной колонке таблицы, происходит рост или снижение продаж.… 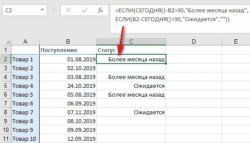 3 примера, как функция ЕСЛИ работает с датами. — На первый взгляд может показаться, что функцию ЕСЛИ для работы с датами можно применять так же, как для числовых и текстовых значений, которые мы только что обсудили. К сожалению, это…
3 примера, как функция ЕСЛИ работает с датами. — На первый взгляд может показаться, что функцию ЕСЛИ для работы с датами можно применять так же, как для числовых и текстовых значений, которые мы только что обсудили. К сожалению, это…
Excel содержит огромное количество самых разнообразных функций, однако не все они нужны при анализе данных. В этой статье вы узнаете о 10 наиболее популярных функций, которые будут нужны при работе с информацией. Эти функции позволяют выполнить большинство задач, которые появляются при анализе данных.
1. ВПР
Эта функция является одной из самых популярных и часто используемых в Excel. Если вам необходимо найти данные в одном столбце в таблице и получить значение из другого столбца таблицы, то эта функция вам поможет. Ее синтаксис:
ВПР (искомое значение; таблица; номер столбца; интервальный просмотр)
— Искомое значение — это то значение, которое мы будем искать в таблице с данными
— Таблица — диапазон данных, в первом столбце которого мы будем искать искомое значение
—
Номер столбца — этот параметр обозначает, на какое количество столбцов
надо сдвинуться вправо в таблице для получения результата
—
Интервальный просмотр — Может принимать параметр 0 или ЛОЖЬ, что
обозначает что совпадение между искомым значением и значением в первом
столбце таблицы должен быть точным; либо 1 или ИСТИНА, соответственно
совпадение должно быть неточным. Настоятельно рекомендую использовать
только параметр ЛОЖЬ, иначе можно получать непредсказуемые результаты.

В примере выше мы ищем по фамилии Петров имя в таблице с базой данных по ФИО. В функции ВПР(E2;A1:C6;2;0) первый параметр (E2) — ссылка на ячейку с фамилией, по которой мы будем искать имя; второй параметр A1:C6 — ссылка на таблицу, в первом столбце которой мы ищем указанное в первом параметре значение; третий параметр «2» — из какого столбца справа извлекать значение; четвертый параметр «0» — точный поиск.
Если хотите изучить более подробно, как работает функция ВПР, прочитайте нашу статью «Функция ВПР в Excel».
2. ГПР
Функция ГПР выполняет туже задачу, что и ВПР, только она просматривает первую строку в поиске искомого значения и для получения результата сдвигается на указанное количество строк вниз.

Синтаксис функции следующий:
ГПР(искомое значение;таблица;номер строки;интервальный просмотр)
— Искомое значение — значение, которое мы ищем в строке.
— Таблица- диапазон данных на листе, где в первой строке мы ищем искомое значение и сдвигаемся на необходимое количество строк.
— Номер строки- числовое значение, указывающее на сколько строк вниз надо сместиться.
— Интервальный просмотр — ставьте всегда 0, тогда Эксель будет искать точное совпадение, что нам и нужно в большинстве случаев.
В примере выше мы ищем выручку за сентябрь в помесячном отчете по выручке. В формуле ГПР(A5;B1:M2;2;0) первый параметр (А5) — ссылка на месяц, по которому мы хотим получить выручку; второй параметр (B1:M2) — ссылка на таблицу, где в первой строке указаны месяцы, среди которых нам нужно найти выбранный; третий параметр «2» — из какой строки ниже мы будем получать данные; четвертый параметр «0» — ищем точное совпадение.
Если вы хотите более подробно изучить, как пользоваться функцией ГПР — прочитайте статью на нашем сайте «Функция ГПР в Excel».
3. ЕСЛИ
Функция ЕСЛИ является очень популярной в Excel. Она позволяет автоматически выполнять какое-либо действие, в зависимости от поставленного условия.

Функция ЕСЛИ выполняет проверку логического выражения и если выражение истинно, то поставляется одно значение и альтернативное, если ложь. Синтаксис следующий:
ЕСЛИ(логическое выражение; значение если истина; значение если ложь)
— Логическое выражение — выражение, которое по итогу своего вычисления должно вырнуться значение ИСТИНА или ЛОЖЬ.
— Значение, если истина — устанавливаем указанное значение, если логическое выражение вернуло ИСТИНА
— Значение, если ложь — устанавливает указанное значение, если логическое выражение вернуло ЛОЖЬ.
В примере выше мы хотим определить, получили ли мы за месяц выручку больше 500 рублей или нет. В формуле ЕСЛИ(B2>500;»Да»;»Нет») первый параметр (B2>500) проверяет, выручка за месяц больше 500 рублей или нет; второй параметр («Да») — функция вернет Да, если выручка больше 500 рублей и соответственно Нет (третий параметр), если выручка меньше.
Обратите внимание, что значения при истине или лжи могут быть не только текстовые, числовые, но также и функции(в том числе и ЕСЛИ), что позволяет реализовать достаточно сложные логические конструкции.
4. ЕСЛИОШИБКА
При работе с формулами в Excel, можно время от времени сталкиваться с различными ошибками. Так в примере ниже функция ВПР вернула ошибку #Н/Д из-за того, что в базе данных по ФИО нет искомой нами фамилии (более подробно об ошибке #Н/Д вы можете прочитать в этой статье: «Как исправить ошибку #Н/Д в Excel»)
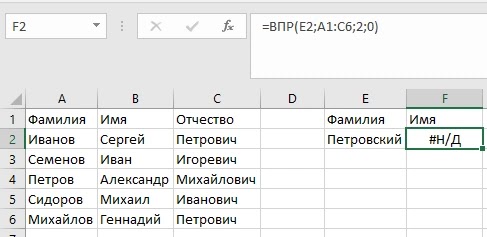
Для обработки таких ситуаций отлично подойдет функция ЕСЛИОШИБКА. Ее синтаксис следующий:
ЕСЛИОШИБКА(значение; значение если ошибка)
— Значение, результат которого проверяется на ошибку.
— Значение, если ошибка — В случае, если в результате работы функции получаем ошибку, то выводится не ошибка, а данное значение.
В случае с нашим примером выше, мы можем предположить, что фамилия может быть некорректной, соответственно ЕСЛИОШИБКА вернет нам предупреждение, что бы мы проверили написание фамилии.
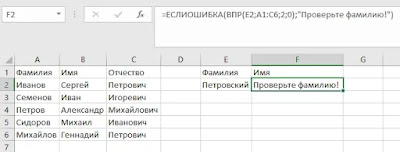
В примере выше, мы проверяем результат работы функции ВПР(E2;A1:C6;2;0) и в случае, если вернется ошибка, то выдаем сообщение «Проверьте фамилию!».
5. СУММЕСЛИМН
Функция СУММЕСЛИМН позволяет суммировать значения по определенным условиям. Условий может быть несколько. В Excel также есть функция СУММЕСЛИ, которая позволяет суммировать по одному критерию. Призываю вас использовать более универсальную формулу.

У функции СУММЕСЛИМН следующий синтаксис:
СУММЕСЛИМН(Диапазон суммирования; Диапазон условия 1; Условие 1;…)
— Диапазон суммирования — область листа Эксель, из которой мы суммируем данные
— Диапазон условия 1 — Диапазон ячеек, которые мы проверяем на соответствие условию
— Условие 1 — Условие, которое проверяется на соответствие в Диапазоне 1.
Обратите внимание, что диапазонов условий и соответственно условий может быть столько, сколько вам нужно.
Для примера выше мы хотим получит выручку, которую принес нам Петров в городе Москва. Формула имеет вид СУММЕСЛИМН(C2:C13;A2:A13;E2;B2:B13;F2), где C2:C13 — диапазон со значениями выручки, которые необходимо просуммировать; А2:А13 — диапазон с фамилиями, которые мы будем проверять; Е2 — ссылка на конкретную фамилию; B2:B13 — ссылка на диапазон с городами; F2 — ссылка на конкретный город.
Более подробно о функциях СУММЕСЛИМН и СУММЕСЛИ рассказано в статье «СУММЕСЛИ и СУММЕСЛИМН в Excel».
6. СЧЁТЕСЛИМН
СЧЁТЕСЛИМН очень похожа на функцию СУММЕСЛИМН, только в отличии от нее, она не суммируется значения, а только считает количество ячеек, которые соответствуют определенным условиям. Как и в случае с СУММЕСЛИМН, у СЧЁТЕСЛИМН есть упрощенная форма СЧЁТЕСЛИ, который считает количество ячеек только по одному критерию, но лучше используйте более общий вариант.

Синтаксис у функции следующий:
СЧЁТЕСЛИМН(диапазон условия 1; условие 1;…)
— Диапазон условия 1 — Диапазон ячеек, которые проверяются на соответствие определенному условию.
— Условие 1 — Условие, которое определяет какие ячейки надо учитывать при подсчете.
Обратите внимания, что диапазонов условий и соответственно условий может быть несколько.
В примере выше, мы считаем сколько в таблице ячеек, в которых фамилия — Петров, а город — Москва. В формуле СЧЁТЕСЛИМН(A2:A13;E2;B2:B13;F2) диапазон A2:A13 — диапазон фамилий, которые мы проверяем, Е2 — та фамилия, которую мы ищем в диапазоне; B2:B13 — диапазон городов и соответственно F2 — город, который мы учитываем при подсчете ячеек. Получившееся число 3 — это количество строк в таблице, где фамилия равна Иванов, а город равен Москва.
7. СЖПРОБЕЛЫ
При работе с данными в Excel, мы можем получать их из разных источников, что может привести к тому, что получаемые значения имеют «мусорную» информацию, очень часто это лишние пробелы, которые надо удалить. Можно удалять вручную, но это долго и муторно. На выручку нам приходит функция СЖПРОБЕЛЫ, которая удаляет лишние пробелы, в случае если их больше одного подряд. Синтаксис у функции очень простой:
СЖПРОБЕЛЫ(текст)
— Текст — тот текст, из которого надо убрать лишние пробелы.

Как видно из примера выше, функция успешно удалила лишние пробелы из исходной строки.
8. ЛЕВСИМВ и ПРАВСИМВ
Функции ЛЕВСИМВ и ПРАВСИМВ возвращают определенное количество знаков с начала (ЛЕВСИМВ) либо с конца (ПРАВСИМВ) строки. Эти функции нужны для получения части строки. Синтаксис у функций однотипный:
ЛЕВСИМВ(текст; количество знаков)
ПРАВСИМВ(текст; количество знаков)
— Текст — то строковое выражение, из которого мы хотим получить часть.
— Количество знаков — число символов, которое мы хотим получить.

В примере выше мы из текста «Пример текста» извлекаем 6 символов слева и получаем текст «Пример».
9. СЦЕПИТЬ
Функция СПЕПИТЬ позволяет объединить значения из нескольких ячеек. Синтаксис у функции достаточно простой:
СЦЕПИТЬ(текст1; текст2;…)
— Текст 1 — Текст, который надо соединить в одну строку
— Текст 2 — Текст, который надо соединить в одну строку
Обратите внимание, что вы можете объединить до 255 текстовых значений.

В примере выше мы объединяем фамилию и имя. В функции СЦЕПИТЬ(A2;» «;B2), первый параметр(А2) — ссылка на ячейку с фамилией; второй параметр (» «) — пробел, что бы итоговый текст смотрелся нормально; третий параметр(В2) — ссылка на ячейку с именем.
10.ЗНАЧЕН
Часто данные, которые мы получаем из внешних источников, имеют текстовый формат и мы не можем производить с ними математических действий (складывать, вычитать и т.п.). Нам требуется сначала преобразовать текст в число, для этого используйте функцию ЗНАЧЕН. Синтаксис у функции следующий:
ЗНАЧЕН(текст)
— Текст — число, представленное в текстовом формате

Как видно в примере выше, у нас есть число 12522, которое представлено в виде текста, при помощи функции ЗНАЧЕН мы преобразовали его в число 12 522, с которым в дальнейшем можем работать, как с любыми другими числами.
Спасибо, что дочитали статью. Я постарался выбрать 10 наиболее полезных функций в Excel, которые нужны при анализе данных. Жду ваши комментарии.
На чтение 10 мин Просмотров 13.9к. Опубликовано 31.07.2020
Содержание
- 5 thoughts on “ «ВПР» по частичному совпадению ”
- Проверяем условие для полного совпадения текста.
- ЕСЛИ + СОВПАД
- Использование функции ЕСЛИ с частичным совпадением текста.
- ЕСЛИ + ПОИСК
- ЕСЛИ + НАЙТИ
- Примеры использования функции ПОИСКПОЗ в Excel
- Формула для поиска неточного совпадения текста в Excel
- Сравнение двух таблиц в Excel на наличие несовпадений значений
- Поиск ближайшего большего знания в диапазоне чисел Excel
- Особенности использования функции ПОИСКПОЗ в Excel
Спустя катастрофически большой промежуток времени с момента публикации моего последнего поста, решил поделиться супер крутой, на мой взгляд, Excel-формулой, узнав о которой, начинаешь удивляться, как же раньше-то я жил без нее. Но, должен сказать, авторство ее создания не мое, а вероятнее всего принадлежит англоязычному ресурсу, о котором я скажу ниже.
Кто более-менее часто работает с массивами данных в Excel почти наверняка знает про функцию ВПР (см. мою статью) или ИНДЕКС+ПОИСКПОЗ, которые решают достаточно частую задачу по объединению двух наборов данных по каким-либо совпадающим значениям. И действительно, использование этих функций решает задачи по сопоставлению и объединению данных в 90% случаев. Если бы не одно но — данные, по которым производится объединение, действительно должны именно совпадать. Но бывают случаи, когда требуется сопоставление по частичному совпадению. Да, в ВПР есть поиск по приблизительному совпадению, но работает он не совсем прозрачно, а потому предугадать, почему было подобрано одно похожее слово, а не другое, может быть невозможно не просто. Как вы поняли, эту прелюдию я затеял не просто так, а для того, чтобы рассказать, как же решить такую задачу при помощи Excel.
Предположим, у нас есть список товаров, которые надо как-то сгруппировать:





5 thoughts on “ «ВПР» по частичному совпадению ”
На форуме SQL.ru мне подсказали еще одно очень изящное решение этой задачи, посмотреть его можно здесь:
http://www.sql.ru/forum/actualutils.aspx?action=gotomsg&t > Спасибо большое, Казанский (автор совета)!
Игорь, спасибо Вам огромное за эту «бронебойную» формулу. Весь интернет «перелопатила» в поиске решения своей задачи и только Вы мне помогли на 100%. Всё работает как часики. Удачи Вам, успешной работы и ещё больше таких гениальных решений.
Ольга, спасибо большое за Ваш комментарий! Справедливости ради надо сказать, что идея этой формулы не моя, а обнаружил я ее на сайте Exceljet
Игорь, добрый день!
Формула прекрасная, но есть ли какая-нибудь ее вариация, которая может находить и подставлять несколько значений сразу?
Например, в строке указаны два производителя холодильников, LG и Samsung
Можно ли вывести их в ячейку через запятую?
Добрый день, Артём!
Спасибо за ваш комментарий и прошу прощения за медленный ответ. Вопрос интересный, но с ходу у меня на него ответа, увы, нет, а по времени довольно сильно ограничен. Если будет свободное время, попробую поломать голову на эту тему
Рассмотрим использование функции ЕСЛИ в Excel в том случае, если в ячейке находится текст.
Будьте особо внимательны в том случае, если для вас важен регистр, в котором записаны ваши текстовые значения. Функция ЕСЛИ не проверяет регистр – это делают функции, которые вы в ней используете. Поясним на примере.
Проверяем условие для полного совпадения текста.
Проверку выполнения доставки организуем при помощи обычного оператора сравнения «=».
=ЕСЛИ(G2=»выполнено»,ИСТИНА,ЛОЖЬ)
При этом будет не важно, в каком регистре записаны значения в вашей таблице.
Если же вас интересует именно точное совпадение текстовых значений с учетом регистра, то можно рекомендовать вместо оператора «=» использовать функцию СОВПАД(). Она проверяет идентичность двух текстовых значений с учетом регистра отдельных букв.
Вот как это может выглядеть на примере.
Обратите внимание, что если в качестве аргумента мы используем текст, то он обязательно должен быть заключён в кавычки.
ЕСЛИ + СОВПАД
В случае, если нас интересует полное совпадение текста с заданным условием, включая и регистр его символов, то оператор «=» нам не сможет помочь.
Но мы можем использовать функцию СОВПАД (английский аналог — EXACT).
Функция СОВПАД сравнивает два текста и возвращает ИСТИНА в случае их полного совпадения, и ЛОЖЬ — если есть хотя бы одно отличие, включая регистр букв. Поясним возможность ее использования на примере.
Формула проверки выполнения заказа в столбце Н может выглядеть следующим образом:
Как видите, варианты «ВЫПОЛНЕНО» и «выполнено» не засчитываются как правильные. Засчитываются только полные совпадения. Будет полезно, если важно точное написание текста — например, в артикулах товаров.
Использование функции ЕСЛИ с частичным совпадением текста.
Выше мы с вами рассмотрели, как использовать текстовые значения в функции ЕСЛИ. Но часто случается, что необходимо определить не полное, а частичное совпадение текста с каким-то эталоном. К примеру, нас интересует город, но при этом совершенно не важно его название.
Первое, что приходит на ум – использовать подстановочные знаки «?» и «*» (вопросительный знак и звездочку). Однако, к сожалению, этот простой способ здесь не проходит.
ЕСЛИ + ПОИСК
Нам поможет функция ПОИСК (в английском варианте – SEARCH). Она позволяет определить позицию, начиная с которой искомые символы встречаются в тексте. Синтаксис ее таков:
=ПОИСК(что_ищем, где_ищем, начиная_с_какого_символа_ищем)
Если третий аргумент не указан, то поиск начинаем с самого начала – с первого символа.
Функция ПОИСК возвращает либо номер позиции, начиная с которой искомые символы встречаются в тексте, либо ошибку.
Но нам для использования в функции ЕСЛИ нужны логические значения.
Здесь нам на помощь приходит еще одна функция EXCEL – ЕЧИСЛО. Если ее аргументом является число, она возвратит логическое значение ИСТИНА. Во всех остальных случаях, в том числе и в случае, если ее аргумент возвращает ошибку, ЕЧИСЛО возвратит ЛОЖЬ.
В итоге наше выражение в ячейке G2 будет выглядеть следующим образом:
Еще одно важное уточнение. Функция ПОИСК не различает регистр символов.
ЕСЛИ + НАЙТИ
В том случае, если для нас важны строчные и прописные буквы, то придется использовать вместо нее функцию НАЙТИ (в английском варианте – FIND).
Синтаксис ее совершенно аналогичен функции ПОИСК: что ищем, где ищем, начиная с какой позиции.
Изменим нашу формулу в ячейке G2
То есть, если регистр символов для вас важен, просто замените ПОИСК на НАЙТИ.
Итак, мы с вами убедились, что простая на первый взгляд функция ЕСЛИ дает нам на самом деле много возможностей для операций с текстом.
Функция ПОИСКПОЗ в Excel используется для поиска точного совпадения или ближайшего (меньшего или большего заданному в зависимости от типа сопоставления, указанного в качестве аргумента) значения заданному в массиве или диапазоне ячеек и возвращает номер позиции найденного элемента.
Примеры использования функции ПОИСКПОЗ в Excel
Например, имеем последовательный ряд чисел от 1 до 10, записанных в ячейках B1:B10. Функция =ПОИСКПОЗ(3;B1:B10;0) вернет число 3, поскольку искомое значение находится в ячейке B3, которая является третьей от точки отсчета (ячейки B1).
Данная функция удобна для использования в случаях, когда требуется вернуть не само значение, содержащееся в искомой ячейке, а ее координату относительно рассматриваемого диапазона. В случае использования для констант массивов, которые могут быть представлены как массивы элементов «ключ» — «значение», функция ПОИСКПОЗ возвращает значение ключа, который явно не указан.
Например, массив <«виноград»;»яблоко»;»груша»;»слива»>содержит элементы, которые можно представить как: 1 – «виноград», 2 – «яблоко», 3 – «груша», 4 – «слива», где 1, 2, 3, 4 – ключи, а названия фруктов – значения. Тогда функция =ПОИСКПОЗ(«яблоко»;<«виноград»;»яблоко»;»груша»;»слива»>;0) вернет значение 2, являющееся ключом второго элемента. Отсчет выполняется не с 0 (нуля), как это реализовано во многих языках программирования при работе с массивами, а с 1.
Функция ПОИСКПОЗ редко используется самостоятельно. Ее целесообразно применять в связке с другими функциями, например, ИНДЕКС.
Формула для поиска неточного совпадения текста в Excel
Пример 1. Найти позицию первого частичного совпадения строки в диапазоне ячеек, хранящих текстовые значения.
Вид исходной таблицы данных:
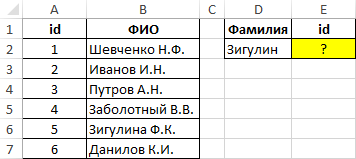
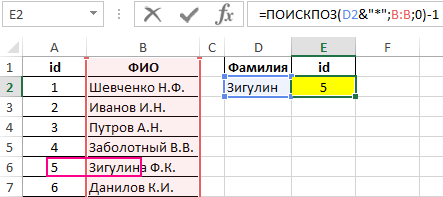
Для нахождения позиции текстовой строки в таблице используем следующую формулу:
Из полученного значения вычитается единица для совпадения результата с id записи в таблице.
Сравнение двух таблиц в Excel на наличие несовпадений значений
Пример 2. В Excel хранятся две таблицы, которые на первый взгляд кажутся одинаковыми. Было решено сравнить по одному однотипному столбцу этих таблиц на наличие несовпадений. Реализовать способ сравнения двух диапазонов ячеек.
Вид таблицы данных:
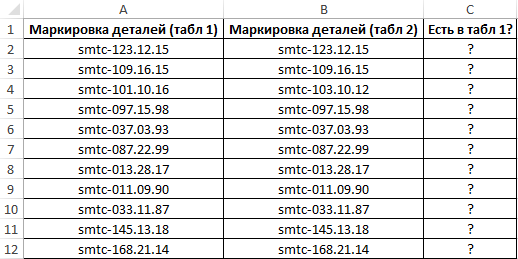
Для сравнения значений, находящихся в столбце B:B со значениями из столбца A:A используем следующую формулу массива (CTRL+SHIFT+ENTER):
Функция ПОИСКПОЗ выполняет поиск логического значения ИСТИНА в массиве логических значений, возвращаемых функцией СОВПАД (сравнивает каждый элемент диапазона A2:A12 со значением, хранящимся в ячейке B2, и возвращает массив результатов сравнения). Если функция ПОИСКПОЗ нашла значение ИСТИНА, будет возвращена позиция его первого вхождения в массив. Функция ЕНД возвратит значение ЛОЖЬ, если она не принимает значение ошибки #Н/Д в качестве аргумента. В этом случае функция ЕСЛИ вернет текстовую строку «есть», иначе – «нет».
Чтобы вычислить остальные значения «протянем» формулу из ячейки C2 вниз для использования функции автозаполнения. В результате получим:
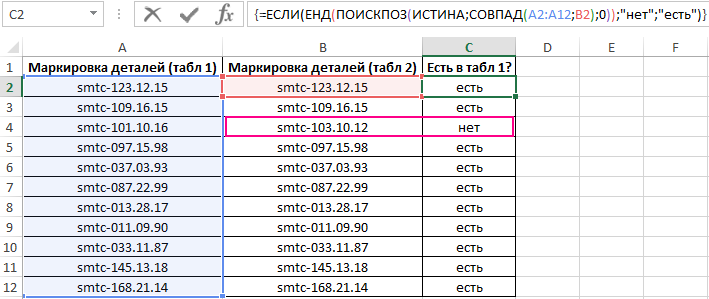
Как видно, третьи элементы списков не совпадают.
Поиск ближайшего большего знания в диапазоне чисел Excel
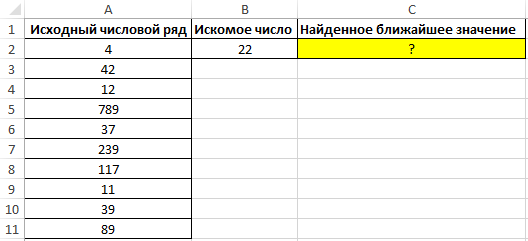
Пример 3. Найти ближайшее меньшее числу 22 в диапазоне чисел, хранящихся в столбце таблицы Excel.
Вид исходной таблицы данных:
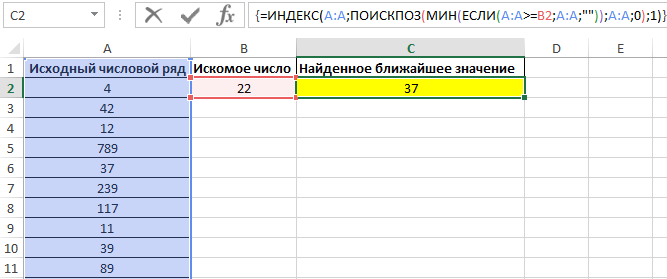
Для поиска ближайшего большего значения заданному во всем столбце A:A (числовой ряд может пополняться новыми значениями) используем формулу массива (CTRL+SHIFT+ENTER):
Функция ПОИСКПОЗ возвращает позицию элемента в столбце A:A, имеющего максимальное значение среди чисел, которые больше числа, указанного в ячейке B2. Функция ИНДЕКС возвращает значение, хранящееся в найденной ячейке.
Для поиска ближайшего меньшего значения достаточно лишь немного изменить данную формулу и ее следует также ввести как массив (CTRL+SHIFT+ENTER):
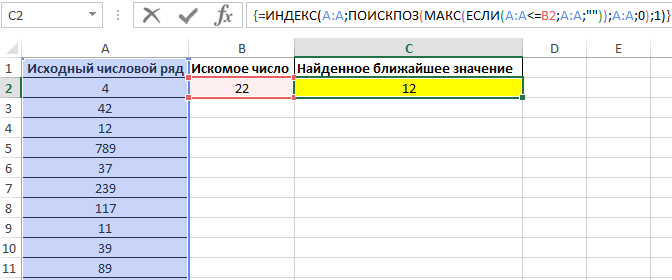
Особенности использования функции ПОИСКПОЗ в Excel
Функция имеет следующую синтаксическую запись:
=ПОИСКПОЗ( искомое_значение;просматриваемый_массив; [тип_сопоставления])
- искомое_значение – обязательный аргумент, принимающий текстовые, числовые значения, а также данные логического и ссылочного типов, который используется в качестве критерия поиска (для сопоставления величин или нахождения точного совпадения);
- просматриваемый_массив – обязательный аргумент, принимающий данные ссылочного типа (ссылки на диапазон ячеек) или константу массива, в которых выполняется поиск позиции элемента согласно критерию, заданному первым аргументом функции;
- [тип_сопоставления] – необязательный для заполнения аргумент в виде числового значения, определяющего способ поиска в диапазоне ячеек или массиве. Может принимать следующие значения:
- -1 – поиск наименьшего ближайшего значения заданному аргументом искомое_значение в упорядоченном по убыванию массиве или диапазоне ячеек.
- 0 – (по умолчанию) поиск первого значения в массиве или диапазоне ячеек (не обязательно упорядоченном), которое полностью совпадает со значением, переданным в качестве первого аргумента.
- 1 – Поиск наибольшего ближайшего значения заданному первым аргументом в упорядоченном по возрастанию массиве или диапазоне ячеек.
- Если в качестве аргумента искомое_значение была передана текстовая строка, функция ПОИСКПОЗ вернет позицию элемента в массиве (если такой существует) без учета регистра символов. Например, строки «МоСкВа» и «москва» являются равнозначными. Для различения регистров можно дополнительно использовать функцию СОВПАД.
- Если поиск с использованием рассматриваемой функции не дал результатов, будет возвращен код ошибки #Н/Д.
- Если аргумент [тип_сопоставления] явно не указан или принимает число 0, для поиска частичного совпадения текстовых значений могут быть использованы подстановочные знаки («?» — замена одного любого символа, «*» — замена любого количества символов).
- Если в объекте данных, переданном в качестве аргумента просматриваемый_массив, содержится два и больше элементов, соответствующих искомому значению, будет возвращена позиция первого вхождения такого элемента.