
Поиск ключевых слов в тексте
Поиск ключевых слов в исходном тексте — одна из очень распространенных задач при работе с данными. Давайте рассмотрим её решение несколькими способами на следующем примере:

Предположим, что у нас с вами есть список ключевых слов — названия автомобильных марок — и большая таблица всевозможных запчастей, где в описаниях иногда могут встречаться один или сразу несколько таких брендов, если запчасть подходит больше, чем к одной марке автомобиля. Наша задача состоит в том, чтобы найти и вывести все обнаруженные ключевые слова в соседние ячейки через заданный символ-разделитель (например, запятую).
Способ 1. Power Query
Само-собой, сначала превращаем наши таблицы в динамические («умные») с помощью сочетания клавиш Ctrl+T или команды Главная — Форматировать как таблицу (Home — Format as Table), даём им имена (например Марки и Запчасти) и загружаем по очереди в редактор Power Query, выбрав на вкладке Данные — Из таблицы/диапазона (Data — From Table/Range). Если у вас старые версии Excel 2010-2013, где Power Query установлена как отдельная надстройка, то нужная кнопка будет на вкладке Power Query. Если у вас совсем новая версия Excel 365, то кнопка Из таблицы/диапазона называется там теперь С листа (From Sheet).
После загрузки каждой таблицы в Power Query возвращаемся обратно в Excel командой Главная — Закрыть и загрузить — Закрыть и загрузить в… — Только создать подключение (Home — Close & Load — Close & Load to… — Only create connection).
Теперь создадим дубликат запроса Запчасти, щёлкнув по нему правой кнопкой мыши и выбрав команду Дублировать запрос (Duplicate query), затем переименуем получившийся запрос-копию в Результаты и дальше будем работать уже с ним.
Логика действий следующая:
- На вкладке Добавление столбца выбираем команду Настраиваемый столбец (Add column — Custom column) и вводим формулу =Марки. После нажатия на ОК получим новый столбец, где в каждой ячейке будет вложенная таблица со списком наших ключевых слов — марок автопроизводителей:

- Кнопкой с двойными стрелками в шапке добавленного столбца разворачиваем все вложенные таблицы. Строки с описаниями запчастей при этом размножатся кратно количеству марок, и мы получим все возможные пары-сочетания «запчасть-марка»:

- На вкладке Добавление столбца выбираем команду Условный столбец (Conditional column) и задаём условие на проверку вхождения ключевого слова (марки) в исходный текст (описание запчасти):

- Чтобы поиск был регистроНЕчувствительный, добавляем вручную в строке формул третий аргумент Comparer.OrdinalIgnoreCase к функции проверки вхождения Text.Contains (если строки формул не видно, то её можно включить на вкладке Просмотр):

- Фильтруем получившуюся таблицу, оставляя только единички в последнем столбце, т.е. совпадения и удаляем ненужный больше столбец Вхождения.
- Группируем одинаковые описания командой Группировать по на вкладке Преобразование (Transform — Group by). В качестве агрегирующей операции выбираем Все строки (All rows). На выходе получаем столбец с таблицами, куда собраны все подробности по каждой запчасти, включая необходимые нам марки автопроизводителей:

- Чтобы извлечь марки для каждой запчасти, добавляем еще один вычисляемый столбец на вкладке Добавление столбца — Настраиваемый столбец (Add column — Custom column) и используем формулу, состоящую из таблицы (они у нас располагаются в столбце Подробности) и имени извлекаемого столбца:

- Щёлкаем по кнопке с двойными стрелками в шапке получившегося столбца и выбираем команду Извлечь значения (Extract values), чтобы вывести марки через любой желаемый символ-разделитель:

- Удаляем ненужный больше столбец Подробности.
- Чтобы добавить к получившейся таблице исчезнувшие из неё запчасти, где в описаниях не было найдено ни одной марки — выполним процедуру объединения запроса Результат с исходным запросом Запчасти кнопкой Объединить на вкладке Главная (Home — Merge queries). Тип соединения — Внешнее соединение справа (Right outer join):

- Останется удалить лишние столбцы и переименовать-переместить оставшиеся — и наша задача решена:










Способ 2. Формулы
Если у вас версия Excel 2016 или новее, то нашу проблему можно весьма компактно и изящно решить с помощью новой функции ОБЪЕДИНИТЬ (TEXTJOIN):

Логика работы этой формулы проста:
- Функция ПОИСК (FIND) ищет вхождение по очереди каждой марки в текущее описание запчасти и выдаёт либо порядковый номер символа, начиная с которого марка была найдена, либо ошибку #ЗНАЧ! если марки в описании нет.
- Затем при помощи функции ЕСЛИ (IF) и ЕОШИБКА (ISERROR) мы заменяем ошибки на пустую текстовую строку «», а порядковые номера символов — на сами названия марок.
- Полученный массив из пустых ячеек и найденных марок собирается в единую строку через заданный символ-разделитель с помощью функции ОБЪЕДИНИТЬ (TEXTJOIN).
Сравнение быстродействия и буферизация запроса Power Query для ускорения
Для тестирования быстродействия возьмем в качестве исходных данных таблицу из 100 000 описаний запчастей. На ней получаем следующие результаты:
- Время пересчета формулами (Способ 2) — 9 сек. при первом копировании формулы на весь столбец и 2 сек. при повторном (сказывается буферизация, видимо).
- Время обновления запроса Power Query (Способ 1) гораздо хуже — 110 сек.
Само-собой, многое зависит от «железа» отдельно взятого ПК и установленной версии Office и обновлений, но общая картина, думаю, понятна.
Для ускорения запроса Power Query давайте буферизуем таблицу-справочник Марки, т.к. она у нас не меняется в процессе выполнения запроса и постоянно пересчитывать её (как это де-факто делает Power Query) не нужно. Для этого используем функцию Table.Buffer из встроенного в Power Query языка М.
Для этого откроем запрос Результаты и на вкладке Просмотр нажмём на кнопку Расширенный редактор (View — Advanced Editor). В открывшемся окне добавим строку с новой переменной Марки2, которая будет буферизованной версией нашего справочника автопроизводителей и используем эту новую переменную далее в следующей команде запроса:

После такой доработки скорость обновления нашего запроса возрастает почти в 7 раз — до 15 сек. Совсем другое дело 
Ссылки по теме
- Нечёткий текстовый поиск в Power Query
- Массовая замена текста формулами
- Массовая замена текста в Power Query функцией List.Accumulate
- Как составить частотный словарь в Excel?
- Простой анализ n-gram (анализ встречаемости)
- Анализ частотности слов, или как посчитать в тексте уникальные слова и вывести списком с их встречаемостью
- Анализ встречаемости биграмм (2-gram)
- Анализ n-gram с частотностью
- N-gram анализ по нескольким метрикам
- Заключение
Для поисковой рекламы и SEO анализ n-грамм – один из самых эффективных методов. Однако долгое время n-gram анализ оставался в силу сложности реализации алгоритма доступен только крупным агентствам с программистами в штате, или продвинутым специалистам со знанием программирования.
Чтобы популяризовать подход и сделать его доступным всем, у кого есть Windows и Excel, инструменты для анализа n-грамм были реализованы в !SEMTools для Excel. Ниже перечислены различные подходы анализа со схематичными примерами.
Во всех кейсах создается отдельный лист с результатами подсчета, исходные данные никак не изменяются.
Простой анализ n-gram (анализ встречаемости)
Данный подход самый простой — берётся N-грамма и для неё анализируется её встречаемость в тексте.
Анализ частотности слов, или как посчитать в тексте уникальные слова и вывести списком с их встречаемостью
Как посчитать, сколько раз встречается слово в Excel-таблице? Если мы ищем лишь одно слово, может помочь формула СЧЁТЕСЛИ. Формула ниже посчитает количество строк, в которых встречается последовательность символов «слова» вне зависимости от их регистра.
=СЧЁТЕСЛИ(A1:A100;"*слова*")
Символ звездочки определяет, что перед и после указанной последовательности символов могут быть любые другие или их отсутствие. В связи с этим могут быть учтены строки со словами «словарь», «словарный» и т.д. Чтобы найти слова по точному совпадению, нужно добавить символ пробела в начало и конец всех ячеек столбца, и воспользоваться подсчетом с учетом пробелов:
=СЧЁТЕСЛИ(A1:A100;"* слова *")
Но и это решение не убережет нас от ситуаций, когда слово повторяется в строке 2 и более раз, если мы хотим посчитать все повторения. Т.к. формула считает именно строки.
Поэтому был реализован макрос в !SEMTools, с легкостью выполняющий эту задачу.
Выделяем текст, выбираем слова, готово. Текст может быть как 5 строк, так и миллион строк – процедура займет секунды. Главное, чтобы уникальных слов в тексте было не больше 1048575 – иначе их не получится вывести на лист. Но такая ситуация — редкость.
Можно обратить внимание, что разные словоформы рассматриваются как отдельные слова, поэтому, если нужно проанализировать встречаемость без учета словоформ, текст нужно предварительно лемматизировать. Тогда вы составите не просто частотный словарь слов, а частотный словарь лемм.

Анализ встречаемости биграмм (2-gram)
Аналогично предыдущему, но берутся биграммы — последовательности из двух слов. Как посчитать в данном случае триграммы и т.д., кажется, уже понятно.

Анализ n-gram с частотностью
Когда текст состоит из фраз, и для каждой фразы известна определенная метрика (в поисковой рекламе это частотность), чтобы более достоверно измерить вес каждой словоформы или леммы, требуется производить анализ уже с учетом этой метрики.
В !SEMTools это вшито по умолчанию – просто нужно выделить два столбца вместе со столбцом используемой метрики. Аналогично можно составлять частотность биграмм, триграмм и т.д.

N-gram анализ по нескольким метрикам
Данный подход будет полезен PPC-специалистам для аналитики расчетных метрик, таких как CTR, CPC, CPA, CR, AOV, ROAS и тому подобные. Поскольку для их расчета используются несколько метрик, можно произвести n-gram анализ этих метрик и посчитать расчетные показатели в разрезе n-грамм.

Такая аналитика может дать много полезных инсайтов. Выявить высококонверсионные связки слов для последующего интенсивного биддинга на них, например. Или, наоборот, выявления низкоконверсионных связок для исключения их из рекламы, в то время как слова, из которых они составлены, в среднем по больнице не выделялись низкой конверсией.

Заключение
Примеры, приведенные выше, позволяют производить анализ не только поисковых запросов или ключевых слов, но и любого текста, который будет дан на вход, вне зависимости от его длины. Нужно только удалить лишние пробелы, перевести весь текст в нижний регистр и можно производить анализ.
Если у вас остались вопросы – подписывайтесь на канал автора и задавайте вопросы в чате: https://t.me/semtoolschat
Часто сталкиваетесь с этой или похожими задачами при работе в Excel?
Скачивайте !SEMTools и начинайте экономить рабочее время, выделяя его для более важных задач!
Для удобства работы с текстом в Excel существуют текстовые функции. Они облегчают обработку сразу сотен строк. Рассмотрим некоторые из них на примерах.
Примеры функции ТЕКСТ в Excel
Преобразует числа в текст. Синтаксис: значение (числовое или ссылка на ячейку с формулой, дающей в результате число); формат (для отображения числа в виде текста).
Самая полезная возможность функции ТЕКСТ – форматирование числовых данных для объединения с текстовыми данными. Без использования функции Excel «не понимает», как показывать числа, и преобразует их в базовый формат.
Покажем на примере. Допустим, нужно объединить текст в строках и числовые значения:

Использование амперсанда без функции ТЕКСТ дает «неадекватный» результат:
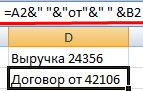
Excel вернул порядковый номер для даты и общий формат вместо денежного. Чтобы избежать подобного результата, применяется функция ТЕКСТ. Она форматирует значения по заданию пользователя.
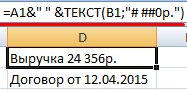
Формула «для даты» теперь выглядит так:
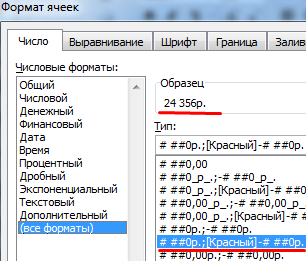
Второй аргумент функции – формат. Где брать строку формата? Щелкаем правой кнопкой мыши по ячейке со значением. Нажимаем «Формат ячеек». В открывшемся окне выбираем «все форматы». Копируем нужный в строке «Тип». Вставляем скопированное значение в формулу.
Приведем еще пример, где может быть полезна данная функция. Добавим нули в начале числа. Если ввести вручную, Excel их удалит. Поэтому введем формулу:
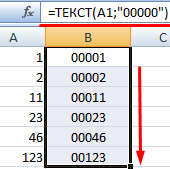
Если нужно вернуть прежние числовые значения (без нулей), то используем оператор «—»:
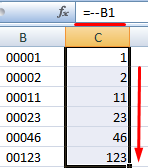
Обратите внимание, что значения теперь отображаются в числовом формате.
Функция разделения текста в Excel
Отдельные текстовые функции и их комбинации позволяют распределить слова из одной ячейки в отдельные ячейки:
- ЛЕВСИМВ (текст; кол-во знаков) – отображает заданное число знаков с начала ячейки;
- ПРАВСИМВ (текст; кол-во знаков) – возвращает заданное количество знаков с конца ячейки;
- ПОИСК (искомый текст; диапазон для поиска; начальная позиция) – показывает позицию первого появления искомого знака или строки при просмотре слева направо
При разделении текста в строке учитывается положение каждого знака. Пробелы показывают начало или конец искомого имени.
Распределим с помощью функций имя, фамилию и отчество в разные столбцы.
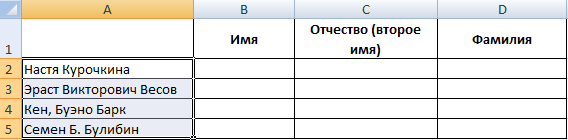
В первой строке есть только имя и фамилия, разделенные пробелом. Формула для извлечения имени: =ЛЕВСИМВ(A2;ПОИСК(» «;A2;1)). Для определения второго аргумента функции ЛЕВСИМВ – количества знаков – используется функция ПОИСК. Она находит пробел в ячейке А2, начиная слева.
Формула для извлечения фамилии:

С помощью функции ПОИСК Excel определяет количество знаков для функции ПРАВСИМВ. Функция ДЛСТР «считает» общую длину текста. Затем отнимается количество знаков до первого пробела (найденное ПОИСКом).
Вторая строка содержит имя, отчество и фамилию. Для имени используем такую же формулу:
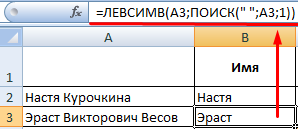
Формула для извлечения фамилии несколько иная: Это пять знаков справа. Вложенные функции ПОИСК ищут второй и третий пробелы в строке. ПОИСК(» «;A3;1) находит первый пробел слева (перед отчеством). К найденному результату добавляем единицу (+1). Получаем ту позицию, с которой будем искать второй пробел.
Часть формулы – ПОИСК(» «;A3;ПОИСК(» «;A3;1)+1) – находит второй пробел. Это будет конечная позиция отчества.
Далее из общей длины строки отнимается количество знаков с начала строки до второго пробела. Результат – число символов справа, которые нужно вернуть.
Формула «для отчества» строится по тем же принципам:

Функция объединения текста в Excel
Для объединения значений из нескольких ячеек в одну строку используется оператор амперсанд (&) или функция СЦЕПИТЬ.
Например, значения расположены в разных столбцах (ячейках):

Ставим курсор в ячейку, где будут находиться объединенные три значения. Вводим равно. Выбираем первую ячейку с текстом и нажимаем на клавиатуре &. Затем – знак пробела, заключенный в кавычки (“ “). Снова — &. И так последовательно соединяем ячейки с текстом и пробелы.
Получаем в одной ячейке объединенные значения:
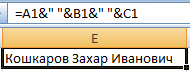
Использование функции СЦЕПИТЬ:
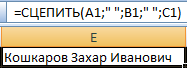
С помощью кавычек в формуле можно добавить в конечное выражение любой знак или текст.
Функция ПОИСК текста в Excel
Функция ПОИСК возвращает начальную позицию искомого текста (без учета регистра). Например:
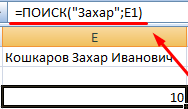
Функция ПОИСК вернула позицию 10, т.к. слово «Захар» начинается с десятого символа в строке. Где это может пригодиться?
Функция ПОИСК определяет положение знака в текстовой строке. А функция ПСТР возвращает текстовые значения (см. пример выше). Либо можно заменить найденный текст посредством функции ЗАМЕНИТЬ.
Скачать пример функции для работы с текстом в Excel
Читайте так же: как перевести число и сумму прописью.
Синтаксис функции ПОИСК:
- «искомый текст» — что нужно найти;
- «просматриваемый текст» — где искать;
- «начальная позиция» — с какой позиции начинать искать (по умолчанию – 1).
Если нужно учитывать регистр, используется функция НАЙТИ.
 Наверное, многие задавались вопросом, как найти функцию в EXCEL«СОДЕРЖИТ» , чтобы применить какое-либо условие, в зависимости от того, есть ли в текстовой строке кусок слова , или отрицание, или часть наименования контрагента, особенно при нестандартном заполнении реестров вручную.
Наверное, многие задавались вопросом, как найти функцию в EXCEL«СОДЕРЖИТ» , чтобы применить какое-либо условие, в зависимости от того, есть ли в текстовой строке кусок слова , или отрицание, или часть наименования контрагента, особенно при нестандартном заполнении реестров вручную.
Такой функционал возможно получить с помощью сочетания двух обычных стандартных функций – ЕСЛИ и СЧЁТЕСЛИ .
Рассмотрим пример автоматизации учета операционных показателей на основании реестров учета продаж и возвратов (выгрузки из сторонних программ автоматизации и т.п.)
У нас есть множество строк с документами Реализации и Возвратов .
Все документы имеют свое наименование за счет уникального номера .
Нам необходимо сделать признак « Только реализация » напротив документов продажи, для того, чтобы в дальнейшем включить этот признак в сводную таблицу и исключить возвраты для оценки эффективности деятельности отдела продаж.
Выражение должно быть универсальным , для того, чтобы обрабатывать новые добавляемые данные .
В открывшемся окне аргументов, в поле Лог_выражение вводим СЧЁТЕСЛИ() , выделяем его и нажимаем 2 раза fx.
Такая запись даст возможность не думать о том, с какой стороны написано слово реализация (до или после номера документа), а также даст возможность включить в расчет сокращенные слова «реализ.» и «реализац.»


Теперь мы можем работать и сводить данные только по документам реализации исключая возвраты . При дополнении таблицы новыми данными, остается только протягивать строку с нашим выражением и обновлять сводную таблицу.
Если материал Вам понравился или даже пригодился, Вы можете поблагодарить автора, переведя определенную сумму по кнопке ниже:
(для перевода по карте нажмите на VISA и далее «перевести»)
Проверка ячейки на наличие текста (без учета регистра)
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим ссылку на оригинал (на английском языке).
Допустим, вы хотите убедиться, что столбец имеет текст, а не числа. Или перхапсйоу нужно найти все заказы, соответствующие определенному продавцу. Если вы не хотите учитывать текст верхнего или нижнего регистра, есть несколько способов проверить, содержит ли ячейка.
Вы также можете использовать фильтр для поиска текста. Дополнительные сведения можно найти в разделе Фильтрация данных.
Поиск ячеек, содержащих текст
Чтобы найти ячейки, содержащие определенный текст, выполните указанные ниже действия.
Выделите диапазон ячеек, которые вы хотите найти.
Чтобы выполнить поиск на всем листе, щелкните любую ячейку.
На вкладке Главная в группе Редактирование нажмите кнопку найти _амп_и выберите пункт найти.
В поле найти введите текст (или числа), который нужно найти. Вы также можете выбрать последний поисковый запрос из раскрывающегося списка найти .
Примечание: В критериях поиска можно использовать подстановочные знаки.
Чтобы задать формат поиска, нажмите кнопку Формат и выберите нужные параметры в всплывающем окне Найти формат .
Нажмите кнопку Параметры , чтобы еще больше задать условия поиска. Например, можно найти все ячейки, содержащие данные одного типа, например формулы.
В поле внутри вы можете выбрать лист или книгу , чтобы выполнить поиск на листе или во всей книге.
Нажмите кнопку найти все или Найти далее.
Найдите все списки всех вхождений элемента, который нужно найти, и вы можете сделать ячейку активной, выбрав определенное вхождение. Вы можете отсортировать результаты поиска » найти все «, щелкнув заголовок.
Примечание: Чтобы остановить поиск, нажмите клавишу ESC.
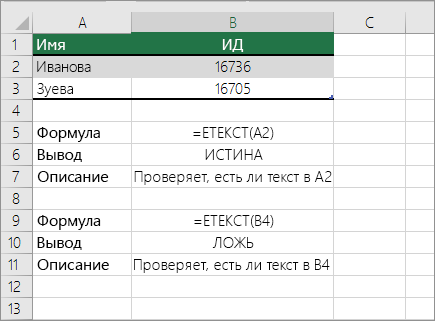
Проверка ячейки на наличие в ней текста
Для выполнения этой задачи используйте функцию текст .
Проверка соответствия ячейки определенному тексту
Используйте функцию Если , чтобы вернуть результаты для указанного условия.
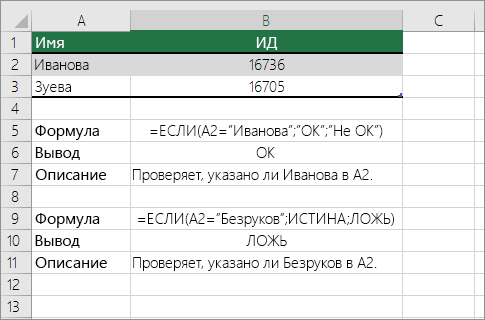
Проверка соответствия части ячейки определенному тексту
Для выполнения этой задачи используйте функции Если, Поиски функция номер .
Примечание: Функция Поиск не учитывает регистр.
Как в excel строки, содержащие текст «N», сделать последовательно?
Есть документ excel. Там много строк. В некоторых строках, в определённой ячейке совпадает слово, скажем — «TheWord», но данные строки разрознены по всей таблице. Как эти строки сделать в последовательности?
Например есть 10 строк со словом «Table» в ячейке, а есть 10 слов со словом «Street», причем в одной ячейке два этих слова встречаться не могут. Так вот, эти строки расположены чередой (сначала строка со словом Table, затем со словом Street, затем снова Table и т.д.). Нужно чтобы сначала шли 10 строк со словом Table, а затем 10 строк со словом Street.
- Вопрос задан более трёх лет назад
- 2718 просмотров
Реализация может быть различной.
Зависит, в частности, от того, сколько в таблице столбцов, в которых нужно искать слово — один или более; сколько искомых слов (например, если их много, то IF использовать будет неудобно, а то и невозможно). Предположим, что столбец один, и это столбец А, а искомых слов — два, Table и Street.
Создайте дополнительный столбец B с формулой, например,
Протяните ее вниз параллельно исходным данным. Тогда в столбец B будут выбраны ключевые слова TableStreet для каждой строки, и other, если строка не содержит ни одного ключевого значения.
Теперь можно выделить столбцы A и B, и отсортировать по значениям столбца B.
Если ключевых слов больше, то ввиду ограничения числа вложенности функции IF такой подход не пойдет. Тогда лучше использовать вариант с функцией CHOOSE:
Работает так же — протягиваете, сортируете по второму столбцу.
Каждое новое ключевое слово добавляете к первому аргументу CHOOSE как элемент
+ISNUMBER(SEARCH(«keyword_n+1»;A1))*[index+1]
где keyword_n+1 — иcкомое ключевое слово, а [index+1] — следующий по порядку индекс. В итоге первый аргумент CHOOSE сводится к числовому значению, равному индексу искомого элемента*. В конце формулы идет перечень значений, выдаваемых по этому индексу. Новое ключевое слово как текстовую строку добавляете туда в конец.
Внимание, в отличие от первого способа, при отсутствии в тексте строки ключевых слов выдает ошибку «#VALUE!» (вместо «other», как в предыдущем примере).
* Корректно работает при условии, что в строке не могут встречаться более одного ключевого слова одновременно. Если у вас будет строка, где есть и Street, и Table, получится фигня. Это же касается и предыдущего способа.
Текстовые функции Excel
ФИО, номера банковских карт, адреса клиентов или сотрудников, комментарии и многое другое –все это является строками, с которыми многие сталкиваются, работая с приложением Excel. Поэтому полезно уметь обрабатывать информацию подобного типа. В данной статье будут рассмотрены текстовые функции в Excel, но не все, а те, которые, по мнению office-menu.ru, самые полезные и интересные:
Список всех текстовых функций Вы можете найти на вкладке «Формулы» => выпадающий список «Текстовые»:
Функция ЛЕВСИМВ
Возвращает подстроку из текста в порядке слева направо в заданном количестве символов.
Синтаксис: =ЛЕВСИМВ(текст; [количество_знаков])
- текст – строка либо ссылка на ячейку, содержащую текст, из которого необходимо вернуть подстроку;
- количество_знаков – необязательный аргумент. Целое число, указывающее, какое количество символов необходимо вернуть из текста. По умолчанию принимает значение 1.
Пример использования:
Формула: =ЛЕВСИМВ(«Произвольный текст»;8) – возвращенное значение «Произвол».
Функция ПРАВСИМВ
Данная функция аналогична функции «ЛЕВСИМВ», за исключением того, что знаки возвращаются с конца строки.
Пример использования:
Формула: =ПРАВСИМВ(«произвольный текст»;5) – возвращенное значение «текст».
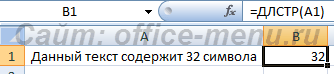
Функция ДЛСТР
С ее помощью определяется длина строки. В качестве результата возвращается целое число, указывающее количество символов текста.
Синтаксис: =ДЛСТР(текст)
Пример использования:
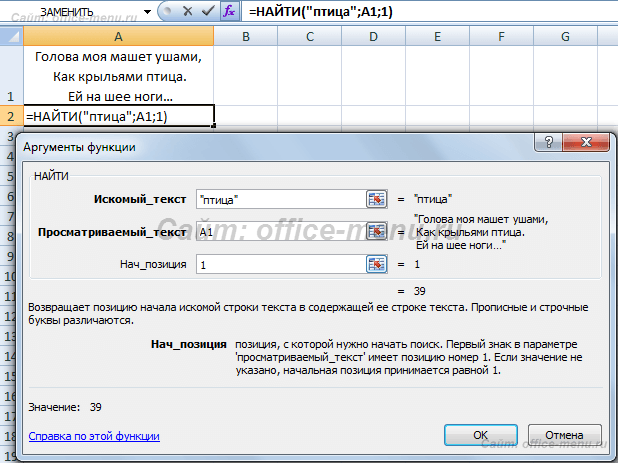
Функция НАЙТИ
Возвращает число, являющееся вхождением первого символа подстроки, искомого текста. Если текст не найден, то возвращается ошибка «#ЗНАЧ!».
Синтаксис: =НАЙТИ(искомый_текст; текст_для_поиска; [нач_позиция])
- искомый_текст – строка, которую необходимо найти;
- текст_для_поиска – текст, в котором осуществляется поиск первого аргумента;
- нач_позиция – необязательный элемент. Принимает целое число, которое указывает, с какого символа текст_для_поиска необходимо начинать просмотр. По умолчанию принимает значение 1.
Пример использования:
Из отрывка стихотворения великого поэта С.А.Есенина находим вхождение первого символа строки «птица». Поиск осуществляется с начала строки. Если в приведенном примере поиск осуществлялся бы с 40 символа, то функция в результате вернула ошибку, т.к. позиции вхождения не было найдено.
Функция ЗАМЕНИТЬ
Данная функция заменяет часть строки в заданном количестве символов, начиная с указанного по счету символа на новый текст.
Синтаксис: ЗАМЕНИТЬ(старый_текст; начальная_позиция; количество_знаков; новый_текст)
- старый_текст – строка либо ссылка на ячейку, содержащую текст;
- начальная_позиция – порядковый номер символа слева направо, с которого нужно производить замену;
- количество_знаков – количество символов, начиная с начальная_позиция включительно, которые необходимо заменить новым текстом;
- новый_текст – строка, которая подменяет часть старого текста, заданного аргументами начальная_позиция и количество_знаков.
Пример использования:
Здесь в строке, содержащейся в ячейке A1, подменяется слово «старый», которое начинается с 19-го символа и имеет длину 6 символов, на слово «новый».
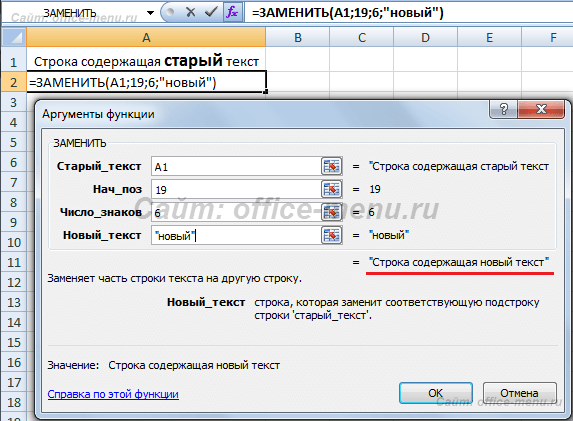
В случае обработки небольшого количества ячеек такой способ вполне приемлем. Но если обработать необходимо несколько тысяч различных строк, то процесс составления формул станет трудоемким. Поэтому переделаем рассмотренный пример, используя знания по тем функциям, которые уже описаны в начале статьи, а именно:
- Аргумент «начальная_позиция» подменим функцией «НАЙТИ»;
- В место аргумент «количество_знаков» вложим функцию «ДЛСТР».
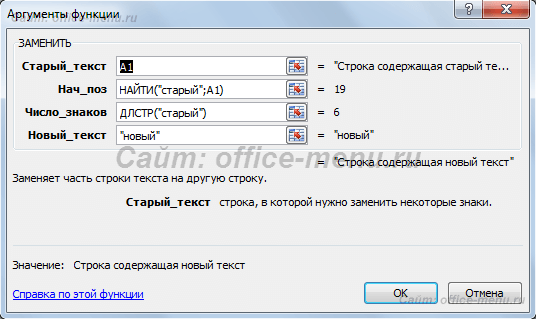
В результате получим формулу: =ЗАМЕНИТЬ(A1;НАЙТИ(«старый»;A1);ДЛСТР(«старый»);»новый»)
Посмотрите на принтскрин окна функции. Возвращаемые результаты аргументов не поменялись, зато теперь их можно определять динамически, составив формулу один раз.
Функция ПОДСТАВИТЬ
Данная функция заменяет в тексте вхождения указанной подстроки на новый текст, чем схожа с функцией «ЗАМЕНИТЬ», но между ними имеется принципиальное отличие. Если функция «ЗАМЕНИТЬ» меняет текст, указанный посимвольно вручную, то функция «ПОДСТАВИТЬ» автоматически находит вхождения указанной строки и меняет их.
Синтаксис: ПОДСТАВИТЬ(текст; старый_текст; новый_текст; [номер_вхождения])
- текст – строка или ссылка на ячейку, содержащую текст;
- старый_текст – подстрока из первого аргумента, которую необходимо заменить;
- новый_текст – строка для подмены старого текста;
- номер_вхождения – необязательный аргумент. Принимает целое число, указывающее порядковый номер вхождения старый_текст, которое подлежит замене, все остальные вхождения затронуты не будут. Если оставить аргумент пустым, то будут заменены все вхождения.
Пример использования:
Строка в ячейке A1 содержит текст, в котором имеются 2 подстроки «старый». Нам необходимо подставить на место первого вхождения строку «новый». В результате часть текста «…старый-старый…», заменяется на «…новый-старый…».

Если ли бы последний аргумент был опущен, то результатом бы стала строка «строка, содержащая новый-новый текст».
Функция ПСТР
ПСТР возвращает из указанной строки часть текста в заданном количестве символов, начиная с указанного символа.
Синтаксис: ПСТР(текст; начальная_позиция; количество_знаков)
- текст – строка или ссылка на ячейку, содержащую текст;
- начальная_позиция – порядковый номер символа, начиная с которого необходимо вернуть строку;
- количество_знаков – натуральное целое число, указывающее количество символов, которое необходимо вернуть, начиная с позиции начальная_позиция.
Пример использования:
Из текста, находящегося в ячейке A1 необходимо вернуть последние 2 слова, которые имеют общую длину 12 символов. Первый символ возвращаемой фразы имеет порядковый номер 12.
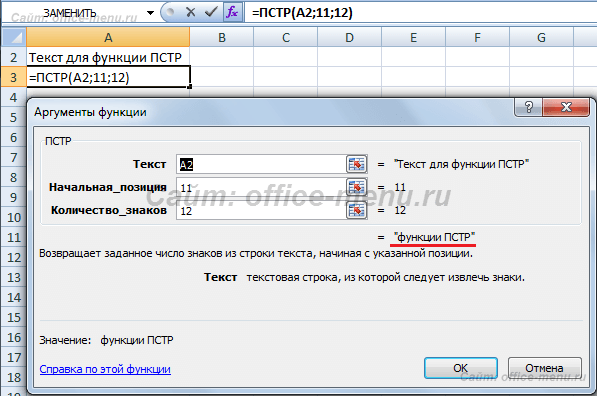
Аргумент количество_знаков может превышать допустимо возможную длину возвращаемых символов. Т.е. если в рассмотренном примере вместо количество_знаков = 12, было бы указано значение 15, то результат не изменился, и функция так же вернула строку «функции ПСТР».
Для удобства использования данной функции ее аргументы можно подменить функциями «НАЙТИ» и «ДЛСТР», как это было сделано в примере с функцией «ЗАМЕНИТЬ».
Функция СЖПРОБЕЛЫ
Данная функция удаляется все лишние пробелы: пробелы по краям и двойные пробелы между словами. После обработки строк функцией остаются только одиночные пробелы между словами.
Синтаксис: =СЖПРОБЕЛЫ(текст)
Пример использования:
=СЖПРОБЕЛЫ( » Текст с лишними пробелами между словами и по краям « )
Результатом выполнения функции будет строка: «Текст с лишними пробелами между словами и по краям» .
Функция СЦЕПИТЬ
С помощью функции «СЦЕПИТЬ» можно объединить несколько строк между собой. Максимальное количество строк для объединения – 255.
Синтаксис: =СЦЕПИТЬ(текст1; [текст2]; …)
Функция должна содержать не менее одного аргумента
Пример использования:
Функция возвратит строку: «Слово1 Слово2».
Не забывайте, что функция самостоятельно не добавляет пробелы между строками, поэтому добавлять их приходится самостоятельно.
Вместо использования данной функции можно применять знак амперсанда «&». Он так же объединяет строки. Например: «=»Слово1″&» «&«Слово2″».
Есть ли слово в списке MS EXCEL
Найдем слово в диапазоне ячеек, удовлетворяющее критерию: точное совпадение с критерием, совпадение с учетом регистра, совпадение лишь части символов из слова и т.д.
Пусть Список значений, в котором производится поиск содержит только отдельные слова (см. столбец А на рисунке ниже).
Совет: О поиске слова в списках, состоящих из текстовых строк (т.е. в ячейке содержится не одно слово, а несколько, разделенных пробелами) можно прочитать в статье Выделение ячеек c ТЕКСТом с применением Условного форматирования в MS EXCEL.
Задачу поиска текстового значения в диапазоне ячеек можно разбить на несколько типов:
- ищутся значения в точности совпадающие с критерием;
- ищутся значения содержащие критерий;
- ищутся значения с учетом РЕгиСТра.
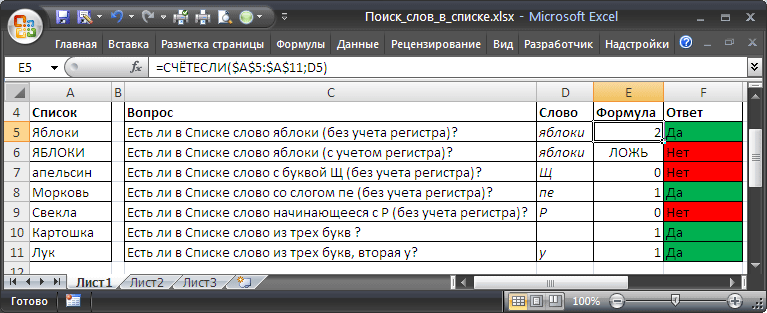
Ищутся значения в точности соответствующие критерию
Это простейший случай. Здесь можно использовать формулу наподобие нижеуказанной
=СЧЁТЕСЛИ($A$5:$A$11;»яблоки»)
Формула возвращает количество найденных значений, соответствующих критерию (см. файл примера ).
Ищутся значения содержащие часть текстовой строки
Типичный вопрос для этого типа поиска: Есть ли в Списке слово со слогом МА?
Для ответа на вопросы такого типа требуется задать в качестве критерия часть текстового значения. Например, для отбора всех ячеек, содержащих все склонения слова яблоко (яблоку, яблоком, яблока и пр.) можно использовать критерии с подстановочным знаком * (звездочка). Для этого нужно использовать конструкцию *яблок*.
Типичная формула =СЧЁТЕСЛИ($A$5:$A$11;»*МА*»)
Ищутся значения с учетом РЕгиСТрА
Учет регистра приводит к необходимости создания сложных формул или использования дополнительных столбцов. Чаще всего используются формулы на основе функций учитывающих регистр НАЙТИ() , СОВПАД() .
Формула массива =ИЛИ(СОВПАД(«яблоки»;A5:A11)) дает ответ на вопрос есть ли такой элемент в списке.
СОВЕТ:
Идеи о поиске также можно посмотреть в статье Поиск текстовых значений в списках. Часть1. Обычный поиск.
Похожие статьи
Часто текстовая строка может содержать несколько значений. Например, адрес компании: «г.Москва, ул.Тверская, д.13», т.е. название города, улицы и номер дома. Если необходимо определить все компании в определенном городе, то нужно «разобрать» адрес на несколько составляющих. Аналогичный подход потребуется, если необходимо разнести по столбцам Имя и фамилию, артикул товара или извлечь число или дату из текстовой строки.
Данная статья является сводной, т.е. в ней содержатся ссылки на другие статьи, в которых решены определенные задачи. Начнем с адресов.
Самый простейший случай, если адрес, состоящий из названия города, улицы и т.д., импортирован в ячейку MS EXCEL из другой информационной системы. В этом случае у адреса имеется определенная структура (если элементы адреса хранились в отдельных полях) и скорее всего нет (мало) опечаток. Разгадав структуру можно быстро разнести адрес по столбцам. Например, адрес
«г.Москва, ул.Тверская, д.13»
очевидно состоит из 3-х блоков: город, улица, дом, разделенных пробелами и запятыми. Кроме того, перед названием стоят сокращения г., ул., д. С такой задачей достаточно легко справится инструмент MS EXCEL
Текст по столбцам
. Как это сделать написано в статье
Текст-по-столбцам (мастер текстов) в MS EXCEL
.
Очевидно, что не всегда адрес имеет четкую структуру, например, могут быть пропущены пробелы (запятые все же стоят). В этом случае помогут функции, работающие с текстовыми строками. Вот эти функции:
—
Функция ЛЕВСИМВ() в MS EXCEL
— выводит нужное количество левых символов строки;
—
Функция ПРАВСИМВ() в MS EXCEL
— выводит нужное количество правых символов строки;
—
Функция ПСТР() в MS EXCEL
— выводит часть текста из середины строки.
Используя комбинации этих функций можно в принципе разобрать любую строку, имеющую определенную структуру. Об этом смотри статью
Разнесение в MS EXCEL текстовых строк по столбцам
.
Еще раз отмечу, что перед использованием функций необходимо понять структуру текстовой строки, которую требуется разобрать. Например, извлечем номер дома из вышеуказанного адреса. Понятно, что потребуется использовать функцию ПРАВСИМВ(), но сколько символов извлечь? Два? А если в других адресах номер дома состоит из 1 или 3 цифр? В этом случае можно попытаться найти подстроку «д.», после которой идет номер дома. Это можно сделать с помощью
функции ПОИСК()
(см. статью
Нахождение в MS EXCEL позиции n-го вхождения символа в слове
). Далее нужно вычислить количество цифр номера дома. Это сделано в файле примера , ссылка на который внизу статьи.
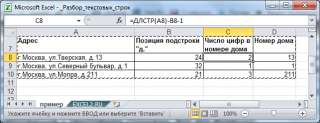
Усложним ситуацию. Пусть подстрока «д.» может встречаться в адресе несколько раз, например, при указании названия
деревни
используется сокращение «д.», т.е. совпадает с префиксом номера дома. В этом случае нужно определить все строки, в которых имеется название деревень (первые 2 символа, т.к. это адрес населенного пункта) и исключить их. Также можно извлечь все цифры из строки в отдельный диапазон (см. статью
Извлекаем в MS EXCEL число из конца текстовой строки
). Но, что делать, если в названии улицы есть числа? Например, «26 Бакинских комиссаров». Короче, тут начинается творчество.
Не забудьте про пробелы! Каждый пробел — это отдельный символ. Часто при печати их ставят 2 или 3 подряд, а это совсем не то же самое, что один пробел. Используйте функцию
Функция СЖПРОБЕЛЫ() в MS EXCEL
, чтобы избавиться от лишних пробелов.
Об извлечении чисел из текстовой строки
см. здесь:
Извлекаем в MS EXCEL число из начала текстовой строки
или здесь
Извлекаем в MS EXCEL число из середины текстовой строки
.
Об извлечении названия файла из полного пути
см.
Извлечение имени файла в MS EXCEL
.
Про разбор фамилии
см.
Разделяем пробелами Фамилию, Имя и Отчество
.
Часто в русских текстовых строках попадаются
английские буквы
. Их также можно обнаружить и извлечь, см.
Есть ли в слове в MS EXCEL латинские буквы, цифры, ПРОПИСНЫЕ символы
.
Все статьи сайта, связанные с преобразованием текстовых строк собраны в этом разделе:
Изменение Текстовых Строк (значений)
.
Артикул товара
Пусть имеется перечень артикулов товара: 2-3657; 3-4897; …
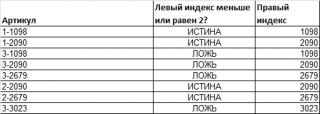
Как видно, артикул состоит из 2-х числовых частей, разделенных дефисом. Причем, числовые части имеют строго заданный размер: первое число состоит из 1 цифры, второе — из 4-х.
Задача состоит в том, чтобы определить артикулы, у которых левый индекс <=2 и вывести для них правый индекс.
Первая часть задачи решается формулой =—ЛЕВСИМВ(A16;1)<=2 или =ЗНАЧЕН(ЛЕВСИМВ(A16;НАЙТИ(«-«;A16;1)-1))<=2 . Вторая формула понадобится, если длина первого индекса не обязательна равна 1 (см. файл примера ).
Вторая часть задачи решается формулой =ЗНАЧЕН(ПРАВСИМВ(A16;4)) .
Зачем нам потребовалась функция ЗНАЧЕН() ? Дело в том, что текстовые функции, такие ка ПРАВСИМВ() , возвращают текст, а не число (т.е. в нашем случае число в текстовом формате). Для того, чтобы применить к таким числам в текстовом формате операцию сравнения с другим числом, т.е. <=2, потребуется сначала
преобразовать текстовый формат в числовой формат
. Самый простой для этого способ — использовать функцию ЗНАЧЕН() или попытаться применить к нему арифметическую операцию, например, двойное вычитание — или *1 или +0.
ВНИМАНИЕ!
Если у Вас есть примеры или вопросы, связанные с разбором текстовых строк — смело пишите в комментариях к этой статье или в группу
]]>
https://vk.com/excel2ru
]]> ! Я дополню эту статью самыми интересными из них.
Время прочтения: 7 мин.
Зачастую, при работе с многочисленными выгрузками в MS Excel нам приходится обрабатывать, фильтровать и буквально «вытаскивать» интересующие нас и так необходимые в повседневной работе данные. Степень трудоемкости таких «вытаскиваний» варьируется от «выбрать все желтые и красные строчки, потому что остальные – это не наши» до «посчитать для всех клиентов с ФИО Иванов Иван Иванович, у которых в день было больше трех операций и которые обслуживались в ВСП на территории ГОСБ, сумму их вкладных операций». В соответствии с поставленной перед нами задачей, мы выбираем инструмент для ее решения.
Но что делать, если стандартными средствами MS Excel поставленную задачу не решить. Одним из наиболее подходящих инструментов в данной ситуации является применение «регулярных выражений» (regular expressions). Проще говоря, регулярные выражения — это язык, где с помощью специальных символов и правил производится поиск нужных подстрок в тексте, их извлечение или замена на другой текст. Но, к сожалению, MS Excel, не имеет поддержки данного инструмента по умолчанию, тем не менее, это легко исправить вручную, проделав ряд следующих операций (нижеследующая настройка производится для MS Excel 2016, для MS Excel 2010 процедура аналогична):
- Необходимо убедиться в том, что в MS Excel включена вкладка «Разработчик» и не запрещено
применение макросов:

Если вкладка отсутствует, ее необходимо активировать
следующим образом:
а) С помощью перехода в меню «Файл»-> «Параметры», отрываем окно «Параметры Excel»:

б) На вкладке «Настроить ленту» нужно выбрать «Все вкладки» и поставить отметку в строке «Разработчик», после чего нажать «ОК»:

в) Также, во вкладке «Центр управления безопасностью», необходимо перейти в «Параметры центра управления безопасностью»:

г) В открывшемся окне нужно проверить, включены ли макросы, и нажать «ОК»:

2. Перейти в «Microsoft Visual Basic for Applications», нажав кнопку «Visual Basic» во вкладке «Разработчик» или же с помощью сочетания клавиш Alt+F11

3. В открывшемся окне, необходимо последовательно перейти в меню «Инструменты» («Tools») -> «Ссылки» («References»):

4. В окне «Ссылки» («References») нужно проставить отметку в строке Microsoft VBScript Regular Expressions 5.5, после чего нажать «ОК»:

5. В окне «Microsoft Visual Basic for Applications» создать новый модуль с помощью команд «Вставка» («Insert») -> «Модуль» («Module»):

6. В открывшемся редакторе кода, необходимо написать следующую функцию:

Мы только что написали пользовательскую функцию, которая и будет
обрабатывать наши текстовые конструкции, используя механизм регулярных
выражений. Параметрами этой функции являются соответственно: последовательность
символов, подлежащая обработке и шаблон, по которому будет производиться отбор
интересующих нас подпоследовательностей символов.
Результатом же будет искомая
подпоследовательность, либо сообщение об ошибке в случае отсутствия таковой.
Прим.: в случае повторного нахождения в
строке подходящей нам подпоследовательности, она будет проигнорирована, а
результатом функции будет самая первая подходящая подпоследовательность
символов.
Наконец, процесс подготовки завершен, и мы можем потренироваться в написании регулярных выражений. Но, предварительно, давайте разберемся, как выглядят шаблоны для поиска. Вот самые основные из них:
| Метасимвол | Описание |
| . |
Точка — обозначает любой символ в шаблоне на указанной позиции (кроме знака новой строки n). |
| s | Любой знак пробела, а именно: пробел, табуляция и перенос строки. |
| S |
Противоположный по смыслу вариант предыдущего шаблона, то есть любой символ, не выглядящий как пробел. |
| d | Цифровой символ, то есть любая цифра. |
| D | Нецифровой символ — любой символ кроме цифры. |
| w | Любой символ латиницы (a-z, A-Z), цифра (0-9) или знак подчеркивания (_). |
| W |
Анти-вариант предыдущего, то есть не латиница, не цифра и не подчеркивание. |
| [символы] |
В квадратных скобках можно указать один или несколько символов, разрешенных на указанной позиции в тексте. Например, тр[ае]к будет соответствовать любому из слов: трак или трек. Также можно не перечислять символы, а задать их диапазоном через дефис, таким образом, вместо [АБВГД] можно написать [А-Д], или вместо [12345] ввести [1-5]. Например, для обозначения всех символов кириллицы можно использовать шаблон [а-яА-ЯёЁ]. |
| [^символы] |
Символ ^ придает набору символов в квадратных скобках обратный смысл — на указанной позиции в тексте будут разрешены все символы, кроме перечисленных. Так, шаблон [^дп]уть найдет суть или муть, но не дуть или путь, например. |
| | |
Логический оператор ИЛИ для проверки по любому из альтернативных критериев. Например, (ТБ|ГОСБ|ВСП) будет искать в тексте любое из указанных слов. Обычно набор вариантов заключается в скобки. |
| ^ | Позиция начала строки |
| $ | Позиция конца строки |
| b | Граница слова, то есть позиция между словом и пробелом |
| B | Позиция, отличная от границы слова |
Если мы ищем определенное количество символов, например, пятизначные номера ВСП или двадцатизначные номера счетов, то на помощь нам приходят квантификаторы — специальные выражения, задающие количество вхождений искомых знаков. Квантификатор применяется к предыдущему символу:
| Квантификатор | Описание |
| ? |
Ноль или одно вхождение. Например, d? будет означать одна любая цифра или ее отсутствие. |
| + | Одно или более вхождений. К примеру, s+ означает один или более пробелов. |
| * |
Ноль или более вхождений. Так [A—Z]* — как отсутствие, так и наличие любого количества прописных символов латиницы. |
|
{число} или {число1,число2} |
Этот квантификатор задает строго определенное вхождение символа. Например, d{10} означает строго десять цифр, а d{3,5} — от трех до пяти цифр. |
Теперь можем перейти к
самому интересному – написанию формул, обрабатывающих реальные примеры из
жизни. Все, что нам потребуется – это написать в качестве формулы наименование
нашей пользовательской функции (RegExp), где первым параметром
будет просматриваемый текст, а вторым – шаблон регулярного выражения,
осуществляющий поиск интересующей нас подстроки.
К примеру, рассмотрим задачу поиска в строке ИНН:*

Как видим, теперь и 10-значные, и 12-значные ИНН извлекаются корректно. Рассмотрим шаблон более подробно: b(d{10}|d{12})b. В начале и в конце шаблона мы видим добавившиеся символы b – они означают края слова и применяются для того, чтобы вместо ИНН из текста не тянулась часть более длинного ОГРН или еще какой-либо последовательности цифр. Также, мы видим, что уже знакомый нам шаблон d{10} переместился в скобки и получил альтернативный шаблон d{12} – это сделано для того, чтобы наряду с 10-значными ИНН, производился поиск и 12-значных.
Рассмотрим следующий пример: имеется перечень клиентских операций, где
каждая операция содержит ФИО клиента, которые нам требуется извлечь. Относительно
ФИО строго выполняется лишь одно условие — они всегда набраны в верхнем
регистре. Стандартные функции Excel также не справятся:

В данном случае мы
применяем шаблон вида [А-ЯЁ]+s[А-ЯЁ]+s[А-ЯЁ]+, который состоит из трех шаблонов [А-ЯЁ]+,
соединенных между собой символами s. Здесь все просто –
[А-ЯЁ]+ это любой заглавный символ кириллицы с квантификатором +, то есть
встречающийся от одного раза до бесконечности. Это, как раз, и будет либо
фамилией, либо именем, либо отчеством клиента. Соединительные символы s означают пробелы между членами ФИО.
Подытоживая, хочется
отметить, что мы рассмотрели лишь малую часть всех возможностей, которые
предоставляют регулярные выражения. Существует огромное множество спецсимволов,
правил и квантификаторов, комбинируя которые возможно создавать шаблоны
практически под любые подпоследовательности символов. На тему использования регулярных
выражений написаны целые книги. Стоит отметить, что не все возможности
классических регулярных выражений поддерживаются в VBA, но и этого хватит, чтобы облегчить нашу работу с MS Excel.
Время на прочтение
10 мин
Количество просмотров 20K
Кто работал с онлайн-рекламой,
тот в цирке не смеётся
знает, что поисковики порой выдают неожиданные ответы на запросы или подкидывают совершенно не те объявления, которые могут быть интересны. В последнем случае корень проблемы зачастую кроется в наборе ключевых слов, которые использует рекламодатель в своих кампаниях. Бездумная автоматизация подбора ключевиков приводит к печальным последствиям, среди которых самое удручающее — пустые показы и клики. Excel-изобретатель и рационализатор Realweb Дмитрий Тумайкин озадачился этой проблемой и создал очередной файл-робот, который рад раздать миру и Хабру. Вновь передаём слово автору.

«В моей предыдущей статье речь шла о кластеризации больших семантических ядер с помощью макросов и формул в MS Excel. На этот раз речь пойдет о ещё более интересных вещах – словоформах, лемматизации, Яндексе, Google, словаре Зализняка и снова об Excel – его ограничениях, методах их обхода и невероятных скоростях бинарного поиска. Статья, как и предыдущая, будет интересна специалистам по контекстной рекламе и SEO-специалистам.
Итак, с чего всё началось?
Как известно, ключевым отличием алгоритмов поиска Яндекса от поиска Google является поддержка морфологии русского языка. Что имеется в виду: одна из самых больших приятностей заключается в том, что в Яндекс.Директ достаточно задать одну словоформу как минус-слово (любую), и объявление не будет показываться ни по одной из всех его словоформ. Занёс в минус-слова слово «бесплатно» — и не будет показов по словам «бесплатный», «бесплатная», «бесплатных», «бесплатными» и т.д. Удобно? Конечно же!
Однако не всё так просто. На тему странностей морфологии Яндекса была написана не одна статья, включая посты на самом Хабре, да и я в ходе своей работы неоднократно сталкивался с ними. Споры идут по сей день, но я считаю, данный алгоритм несмотря ни на что можно считать преимуществом перед логикой Google.
Странность же заключается в том, что, если группа всех словоформ, скажем, глагола или прилагательного, содержит омоним с группой словоформ существительного, то Яндекс фактически «склеивает» их в некое единое множество словоформ, по всем из которых будут показываться ваши объявления.
Вот наглядный пример, да простит меня НашЛось:
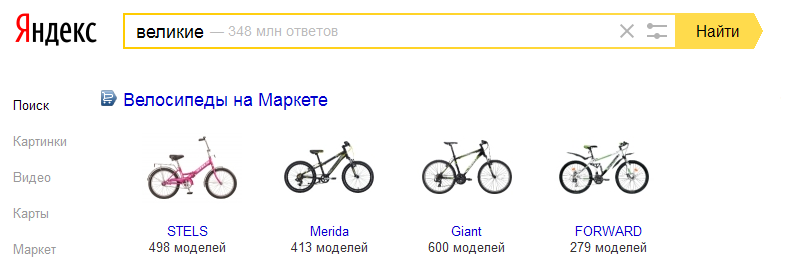
Как всем ясно, краткая форма прилагательного «великий», «велик», является омонимом слову «велик», который, в свою очередь — синоним слова «велосипед». У самого «велика» словоформы «великий», разумеется, нет, поэтому показывать его по этому запросу очевидно неправильно. Говоря языком лингвистов, Яндекс перепутал парадигмы.
Ситуация в естественной выдаче намного лучше, возможно, алгоритмы там более сложны и оптимизированы. А может, это связано с более высокой конкуренцией, т.к. SEO условно-бесплатно (если в штате есть свой вебмастер), а охотников платить за каждый клик в Директе на порядок меньше, несмотря на позитивные тренды в контекстной рекламе. Может, аукцион VCG все исправит? Поживём — увидим.
Однако у корпорации добра свои причуды. Google
плохо говорить по-русски
практически не распознаёт словоформы. В отличие от Директа, в AdWords нужно исключать все словоформы минус-слов (что уже само по себе морока). При этом количество исключаемых элементов на уровне одной кампании по внутренним ограничениям системы — не более 5000, а в сумме по всем кампаниям в аккаунте – не более 1 млн. Казалось бы, немало, и должно быть достаточно, но владельцам больших рекламных аккаунтов, уверен, так не покажется.
В общем, вывод, который я сделал для себя, работая с Директом и AdWords – для достижения максимальных результатов будешь вынужден копаться в словоформах, какой бы инструмент ни использовал. Поэтому мне нужна была полная база словоформ, желательно наиболее близкая к алгоритмам Яндекса. Я был невероятно рад, когда узнал о ныне ещё живущем, и дай ему Бог ещё здоровья и долгих лет жизни, Зализняке Андрее Анатольевиче, который и создал такой словарь. Данный словарь содержит порядка 100 000 смысловых парадигм, у самой «многогранной» из которых 182 словоформы. В сумме весь словарь составляет чуть более 2,5 млн. слов. Он лёг в основу множества систем распознавания морфологии. Именно этот словарь в электронной табличной форме я нашёл на просторах Интернета и успешно интегрировал в Excel для рабочих нужд.
У любопытных может возникнуть вопрос — зачем было нужно вставлять в Excel 2,5 млн. слов?
И у меня на это 5 причин
, отвечаю:
- Во-первых, было просто любопытно, что за словарь. Дело в том, что Яндекс начал поддержку словоформ, взяв за основу и используя как базу данных именно его. Далее, конечно, программисты Яндекса существенно продвинулись, что видно хотя бы по последней версии Mystem, в которой присутствует алгоритм снятия омонимии, о которой написано выше (как я понимаю, алгоритм распознает части речи близлежащих слов, и на базе этой информации строит предположения о части речи у исходного «многозначного» слова). Но тем не менее, основное конкурентное преимущество нашего интернет-гиганта — поддержка морфологии «великого и могучего» — результат проделанной работы и частично дело рук 80-летнего профессора.
- Бесплатные лемматизаторы (например, от K50 или Андрея Кашина) с простым интерфейсом, известные мне и находящиеся в открытом доступе, не отвечают моим требованиям, т.к. их выдача не соответствует алгоритмам Яндекса. И мне, не будучи их разработчиком, данную ситуацию никак не исправить.
- Поскольку основная часть работы с текстом происходит в таблицах Excel, и веб-интерфейсы не всегда могут быть доступны или «тормозят» на больших объемах данных, для меня удобнее иметь все инструменты «под рукой», локально.
- «Робот-распознаватель 1.0» без встроенной нормализации был никуда не годен, и я сам это осознавал. Какой смысл специалисту по контекстной рекламе кластеризовать не нормализованное ядро? Все равно придётся заходить в веб-интерфейс, там нормализовать запросы, копировать и далее уже обрабатывать в Excel.
- После того, как я открыл для себя бинарный поиск в Excel, захотелось опробовать его в действии, на действительно больших объемах данных. А чем 2,5 млн. ячеек не большой объём для MS Excel?
Рождение лемматизатора и бинарный поиск
Поэтому я и решил, что создам свой лемматизатор, с блэкджеком пресловутыми макросами и формулами. По ходу дела внесу ясность: лемматизация — процесс приведения слоформы к лемме — начальной словарной форме (инфинитив для глагола, именительный падеж единственного числа — для существительных и прилагательных).
Результат стараний можно скачать по ссылке: Робот-распознаватель — 3
Визуально файл практически не отличается от предыдущей версии. Разница лишь в том, что в него добавлены два дополнительных листа (словарь) и макрос, выполняющий поиск по ним, и возвращающий начальную форму. Поскольку ограничения Excel – 2 в 20-й степени строк минус одна строка (чуть больше миллиона), пришлось разделить словарь на 2 листа и составлять макрос исходя из этой особенности. Изначально предполагалось, что данные займут 3 листа, но на счастье, в словаре оказалось порядочное количество дублей. Дублями они являются для компьютера, для человека это могут быть разные словоформы разных парадигм.
В основе файла — гигантский по меркам файла Excel массив. Обработка такого массива данных требует больших ресурсов и может быть довольно медленной. Эту проблему как раз и решил бинарный (двоичный) поиск в Excel, который я упомянул в начале. Линейный алгоритм поиска может построчно пробегать по всем 2,5 млн.+ записей — это займёт очень много времени. Бинарный поиск позволяет обрабатывать массивы данных очень быстро, так как выполняет четыре основных шага:
- Массив данных делится пополам и позиция чтения перемещается в середину.
- Найденное значение (пусть n) сравнивается с тем, которое мы ищем (пусть m).
- Если m > n, то берется вторая часть массива, если m < n — первая часть.
- Далее шаги 1-3 повторяются на выбранной части массива данных.
Проще выражаясь, алгоритм двоичного поиска похож на то, как мы ищем слово в словаре. Открываем словарь посередине, смотрим, в какой из половин будет нужное нам слово. Допустим, в первой. Открываем первую часть посередине, продолжаем половинить, пока не найдем нужное слово. В отличие от линейного, где нужно будет сделать 2 в 20 степени операций (при максимальной заполненности столбца в Excel), при бинарном нужно будет сделать всего 20, например. Согласитесь, впечатляет. В скорости работы двоичного поиска вы можете убедиться, поработав с файлом: по 3 млн. ячеек он ищет каждое из слов в запросах за считанные секунды
Все формулы и макросы работают только в оригинальном файле, и не будут работать в других. И ещё. Если вы будете дополнять словарь в файле, то перед обработкой файла, необходимо отсортировать словарь в алфавитном порядке — как вы уже поняли, этого требует логика бинарного поиска.
Конечно, назвать решение самым изящным не получится хотя бы ввиду использования огромной формулы на 3215 символов. Желающие увидеть её воочию и попробовать разобраться в логике могут зайти и посмотреть.
Посмотреть
СЖПРОБЕЛЫ(ЕСЛИ(substring(A1;» «;1)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;1);’А-Л’!$A:$B;1;1)<substring(A1;» «;1);substring(A1;» «;1); ВПР(substring(A1;» «;1);’А-Л’!$A:$B;2;1));»»); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;1);’М-Я’!$A:$B;1;1)<substring(A1;» «;1);substring(A1;» «;1); ВПР(substring(A1;» «;1);’М-Я’!$A:$B;2;1));»»))&» «&ЕСЛИ(substring(A1;» «;2)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;2);’А-Л’!$A:$B;1;1)<substring(A1;» «;2);substring(A1;» «;2); ВПР(substring(A1;» «;2);’А-Л’!$A:$B;2;1));»»); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;2);’М-Я’!$A:$B;1;1)<substring(A1;» «;2);substring(A1;» «;2); ВПР(substring(A1;» «;2);’М-Я’!$A:$B;2;1));»»))&» «&ЕСЛИ(substring(A1;» «;3)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;3);’А-Л’!$A:$B;1;1)<substring(A1;» «;3);substring(A1;» «;3); ВПР(substring(A1;» «;3);’А-Л’!$A:$B;2;1));»»); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;3);’М-Я’!$A:$B;1;1)<substring(A1;» «;3);substring(A1;» «;3); ВПР(substring(A1;» «;3);’М-Я’!$A:$B;2;1));»»))&» «&ЕСЛИ(substring(A1;» «;4)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;4);’А-Л’!$A:$B;1;1)<substring(A1;» «;4);substring(A1;» «;4); ВПР(substring(A1;» «;4);’А-Л’!$A:$B;2;1));»»); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;4);’М-Я’!$A:$B;1;1)<substring(A1;» «;4);substring(A1;» «;4); ВПР(substring(A1;» «;4);’М-Я’!$A:$B;2;1));»»))&» «&ЕСЛИ(substring(A1;» «;5)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;5);’А-Л’!$A:$B;1;1)<substring(A1;» «;5);substring(A1;» «;5); ВПР(substring(A1;» «;5);’А-Л’!$A:$B;2;1));»»); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;5);’М-Я’!$A:$B;1;1)<substring(A1;» «;5);substring(A1;» «;5); ВПР(substring(A1;» «;5);’М-Я’!$A:$B;2;1));»»))&» «&ЕСЛИ(substring(A1;» «;6)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;6);’А-Л’!$A:$B;1;1)<substring(A1;» «;6);substring(A1;» «;6); ВПР(substring(A1;» «;6);’А-Л’!$A:$B;2;1));»»); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;6);’М-Я’!$A:$B;1;1)<substring(A1;» «;6);substring(A1;» «;6); ВПР(substring(A1;» «;6);’М-Я’!$A:$B;2;1));»»))&» «&ЕСЛИ(substring(A1;» «;7)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;7);’А-Л’!$A:$B;1;1)<substring(A1;» «;7);substring(A1;» «;7); ВПР(substring(A1;» «;7);’А-Л’!$A:$B;2;1));»»); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;7);’М-Я’!$A:$B;1;1)<substring(A1;» «;7);substring(A1;» «;7); ВПР(substring(A1;» «;7);’М-Я’!$A:$B;2;1));»»))&» «&ЕСЛИ(substring(A1;» «;8)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;8);’А-Л’!$A:$B;1;1)<substring(A1;» «;8);substring(A1;» «;8); ВПР(substring(A1;» «;8);’А-Л’!$A:$B;2;1));»»); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;8);’М-Я’!$A:$B;1;1)<substring(A1;» «;8);substring(A1;» «;8); ВПР(substring(A1;» «;8);’М-Я’!$A:$B;2;1));»»))&» «&ЕСЛИ(substring(A1;» «;9)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;9);’А-Л’!$A:$B;1;1)<substring(A1;» «;9);substring(A1;» «;9); ВПР(substring(A1;» «;9);’А-Л’!$A:$B;2;1));»»); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;9);’М-Я’!$A:$B;1;1)<substring(A1;» «;9);substring(A1;» «;9); ВПР(substring(A1;» «;9);’М-Я’!$A:$B;2;1));»»))&» «&ЕСЛИ(substring(A1;» «;10)<«м»; ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;10);’А-Л’!$A:$B;1;1)<substring(A1;» «;10);substring(A1;» «;10); ВПР(substring(A1;» «;10);’А-Л’!$A:$B;2;1));»»); ЕСЛИОШИБКА(ЕСЛИ(ВПР(substring(A1;» «;10);’М-Я’!$A:$B;1;1)<substring(A1;» «;10);substring(A1;» «;10); ВПР(substring(A1;» «;10);’М-Я’!$A:$B;2;1));»»)))
Однако огромная формула — не единственная проблема, с которой пришлось столкнуться в ходе работы над лемматизатором.
- Словарь Зализняка — старое издание (1977 год) и среди словоформ нет некоторых самых простых и привычных для 2015 года слов, например, «компьютерный». Именно поэтому его дорабатывает Яндекс, дорабатываю я и при необходимости может доработать любой. Проблема до конца не решена, но ждите скорые апдейты «Робота» — всё будет.
- В словаре нет имён собственных — их тоже нужно туда добавлять. Я поработал над этим и добавил имена, страны мира и города России.
Проблема отсутствия современных слов решается путём добавления слов, собранных из различных открытых источников. В частности, на момент публикации поста уже собрана база из 300 000 коммерческих запросов, которые будут сравнены с базой. Слова, которых в ней не хватает, будут добавлены в словарь в нужных словоформах. Может показаться, что 300 тысяч слов — это немного, однако, поверьте, это достаточно для значительного расширения словаря Зализняка.
Кроме того, в «Роботе-распознавателе 2» не будет вышеупомянутых ошибок других лемматизаторов, в которых, например, «авито» считается словоформой и возвращает глагол «авить» и генерируются многочисленные словоформы этого несуществующего глагола.
P.S.:Пожелания и багрепорты приветствуются.
Сейчас Дмитрий работает над очередным инструментом, который будет производить обратные операции: генерировать словоформы заданных слов, а не возвращать лемму. Мы ждём очередной поток макросов и гигантских формул. Наряду с системами автоматизации контекстной рекламы, мы в RealWeb активно пользуемся роботами-распознавателями в Excel — это серьёзное подспорье в работе с семантическим ядром, необходимым для работы с web в целом и с онлайн-рекламой в частности.l — это серьёзное подспорье в работе с семантическим ядром, необходимым для работы с web в целом и с онлайн-рекламой в частности. Уверены, что эти инструменты пригодятся и вам!
На чтение 9 мин Просмотров 12.2к. Опубликовано 31.07.2020
Содержание
- Функция ЕСЛИ СОДЕРЖИТ
- Проверяем условие для полного совпадения текста.
- ЕСЛИ + СОВПАД
- Использование функции ЕСЛИ с частичным совпадением текста.
- ЕСЛИ + ПОИСК
- ЕСЛИ + НАЙТИ
- Функция ЕСЛИ: примеры с несколькими условиями
- Если ячейки не пустые, то делаем расчет
- Проверка ввода данных в Excel
- Функция ЕСЛИ: проверяем условия с текстом
- Визуализация данных при помощи функции ЕСЛИ
- Как функция ЕСЛИ работает с датами?
- Функция ЕСЛИ в Excel – примеры использования
- Поиск ячеек, содержащих текст
- Проверка ячейки на наличие в ней текста
- Проверка соответствия ячейки определенному тексту
- Проверка соответствия части ячейки определенному тексту
Функция ЕСЛИ СОДЕРЖИТ
Наверное, многие задавались вопросом, как найти функцию в EXCEL«СОДЕРЖИТ» , чтобы применить какое-либо условие, в зависимости от того, есть ли в текстовой строке кусок слова , или отрицание, или часть наименования контрагента, особенно при нестандартном заполнении реестров вручную.
Такой функционал возможно получить с помощью сочетания двух обычных стандартных функций – ЕСЛИ и СЧЁТЕСЛИ .
Рассмотрим пример автоматизации учета операционных показателей на основании реестров учета продаж и возвратов (выгрузки из сторонних программ автоматизации и т.п.)
У нас есть множество строк с документами Реализации и Возвратов .
Все документы имеют свое наименование за счет уникального номера .
Нам необходимо сделать признак « Только реализация » напротив документов продажи, для того, чтобы в дальнейшем включить этот признак в сводную таблицу и исключить возвраты для оценки эффективности деятельности отдела продаж.
Выражение должно быть универсальным , для того, чтобы обрабатывать новые добавляемые данные .
Для того, чтобы это сделать, необходимо:
-
- Начинаем с ввода функции
ЕСЛИ
-
- (вводим
«=»
-
- , набираем наименование
ЕСЛИ
-
- , выбираем его из выпадающего списка, нажимаем
fx
-
- в строке формул).

В открывшемся окне аргументов, в поле Лог_выражение вводим СЧЁТЕСЛИ() , выделяем его и нажимаем 2 раза fx.

Далее в открывшемся окне аргументов функции СЧЁТЕСЛИ в поле «Критерий» вводим кусок искомого наименования *реализ* , добавляя в начале и в конце символ * .

Такая запись даст возможность не думать о том, с какой стороны написано слово реализация (до или после номера документа), а также даст возможность включить в расчет сокращенные слова «реализ.» и «реализац.»
- Аргумент «Диапазон» — это соответствующая ячейка с наименованием документа.
- Далее нажимаем ОК , выделяем в строке формул ЕСЛИ и нажимаем fx и продолжаем заполнение функции ЕСЛИ.

- В Значение_если_истина вводим « Реализация », а в Значение_если_ложь – можно ввести прочерк « — »
- Далее протягиваем формулу до конца таблицы и подключаем сводную.
Теперь мы можем работать и сводить данные только по документам реализации исключая возвраты . При дополнении таблицы новыми данными, остается только протягивать строку с нашим выражением и обновлять сводную таблицу.
Если материал Вам понравился или даже пригодился, Вы можете поблагодарить автора, переведя определенную сумму по кнопке ниже:
(для перевода по карте нажмите на VISA и далее «перевести»)
Рассмотрим использование функции ЕСЛИ в Excel в том случае, если в ячейке находится текст.
Будьте особо внимательны в том случае, если для вас важен регистр, в котором записаны ваши текстовые значения. Функция ЕСЛИ не проверяет регистр – это делают функции, которые вы в ней используете. Поясним на примере.
Проверяем условие для полного совпадения текста.
Проверку выполнения доставки организуем при помощи обычного оператора сравнения «=».
=ЕСЛИ(G2=»выполнено»,ИСТИНА,ЛОЖЬ)
При этом будет не важно, в каком регистре записаны значения в вашей таблице.

Если же вас интересует именно точное совпадение текстовых значений с учетом регистра, то можно рекомендовать вместо оператора «=» использовать функцию СОВПАД(). Она проверяет идентичность двух текстовых значений с учетом регистра отдельных букв.
Вот как это может выглядеть на примере.

Обратите внимание, что если в качестве аргумента мы используем текст, то он обязательно должен быть заключён в кавычки.
ЕСЛИ + СОВПАД
В случае, если нас интересует полное совпадение текста с заданным условием, включая и регистр его символов, то оператор «=» нам не сможет помочь.
Но мы можем использовать функцию СОВПАД (английский аналог — EXACT).
Функция СОВПАД сравнивает два текста и возвращает ИСТИНА в случае их полного совпадения, и ЛОЖЬ — если есть хотя бы одно отличие, включая регистр букв. Поясним возможность ее использования на примере.
Формула проверки выполнения заказа в столбце Н может выглядеть следующим образом:

Как видите, варианты «ВЫПОЛНЕНО» и «выполнено» не засчитываются как правильные. Засчитываются только полные совпадения. Будет полезно, если важно точное написание текста — например, в артикулах товаров.
Использование функции ЕСЛИ с частичным совпадением текста.
Выше мы с вами рассмотрели, как использовать текстовые значения в функции ЕСЛИ. Но часто случается, что необходимо определить не полное, а частичное совпадение текста с каким-то эталоном. К примеру, нас интересует город, но при этом совершенно не важно его название.
Первое, что приходит на ум – использовать подстановочные знаки «?» и «*» (вопросительный знак и звездочку). Однако, к сожалению, этот простой способ здесь не проходит.
ЕСЛИ + ПОИСК
Нам поможет функция ПОИСК (в английском варианте – SEARCH). Она позволяет определить позицию, начиная с которой искомые символы встречаются в тексте. Синтаксис ее таков:
=ПОИСК(что_ищем, где_ищем, начиная_с_какого_символа_ищем)
Если третий аргумент не указан, то поиск начинаем с самого начала – с первого символа.
Функция ПОИСК возвращает либо номер позиции, начиная с которой искомые символы встречаются в тексте, либо ошибку.
Но нам для использования в функции ЕСЛИ нужны логические значения.
Здесь нам на помощь приходит еще одна функция EXCEL – ЕЧИСЛО. Если ее аргументом является число, она возвратит логическое значение ИСТИНА. Во всех остальных случаях, в том числе и в случае, если ее аргумент возвращает ошибку, ЕЧИСЛО возвратит ЛОЖЬ.
В итоге наше выражение в ячейке G2 будет выглядеть следующим образом:
Еще одно важное уточнение. Функция ПОИСК не различает регистр символов.

ЕСЛИ + НАЙТИ
В том случае, если для нас важны строчные и прописные буквы, то придется использовать вместо нее функцию НАЙТИ (в английском варианте – FIND).
Синтаксис ее совершенно аналогичен функции ПОИСК: что ищем, где ищем, начиная с какой позиции.
Изменим нашу формулу в ячейке G2

То есть, если регистр символов для вас важен, просто замените ПОИСК на НАЙТИ.
Итак, мы с вами убедились, что простая на первый взгляд функция ЕСЛИ дает нам на самом деле много возможностей для операций с текстом.
Примеры использования функции ЕСЛИ:

Функция ЕСЛИ: примеры с несколькими условиями
Для того, чтобы описать условие в функции ЕСЛИ, Excel позволяет использовать более сложные конструкции. В том числе можно использовать и несколько условий. Рассмотрим на примере. Для объединения нескольких условий в […]

Если ячейки не пустые, то делаем расчет
Чтобы выполнить действие только тогда, когда ячейка не пуста (содержит какие-то значения), вы можете использовать формулу, основанную на функции ЕСЛИ. В примере ниже столбец F содержит даты завершения закупок шоколада. […]

Проверка ввода данных в Excel
Подтверждаем правильность ввода галочкой. Задача: При ручном вводе данных в ячейки таблицы проверять правильность ввода в соответствии с имеющимся списком допустимых значений. В случае правильного ввода в отдельном столбце ставить […]
Функция ЕСЛИ: проверяем условия с текстом
Рассмотрим использование функции ЕСЛИ в Excel в том случае, если в ячейке находится текст. Будьте особо внимательны в том случае, если для вас важен регистр, в котором записаны ваши текстовые […]
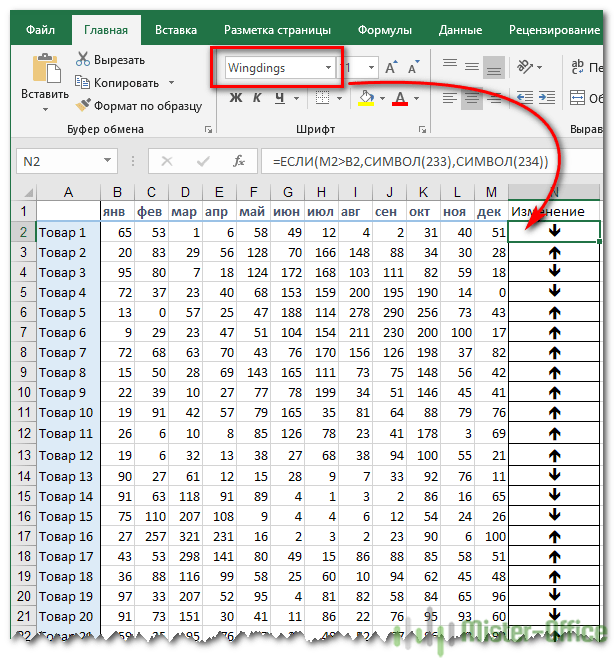
Визуализация данных при помощи функции ЕСЛИ
Функцию ЕСЛИ можно использовать для вставки в таблицу символов, которые наглядно показывают происходящие с данными изменения. К примеру, мы хотим показать, происходит рост или снижение продаж. В столбце N поставим […]
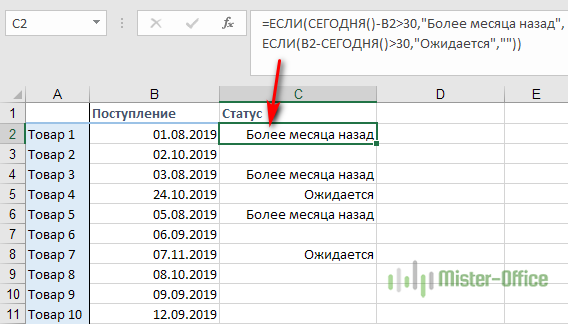
Как функция ЕСЛИ работает с датами?
На первый взгляд может показаться, что функцию ЕСЛИ для работы с датами можно использовать так же, как для числовых и текстовых значений, которые мы только что обсудили. К сожалению, это […]

Функция ЕСЛИ в Excel – примеры использования
на примерах рассмотрим, как можно использовать функцию ЕСЛИ в Excel, а также какие задачи мы можем решить с ее помощью
Примечание: Мы стараемся как можно оперативнее обеспечивать вас актуальными справочными материалами на вашем языке. Эта страница переведена автоматически, поэтому ее текст может содержать неточности и грамматические ошибки. Для нас важно, чтобы эта статья была вам полезна. Просим вас уделить пару секунд и сообщить, помогла ли она вам, с помощью кнопок внизу страницы. Для удобства также приводим ссылку на оригинал (на английском языке).
Допустим, вы хотите убедиться, что столбец имеет текст, а не числа. Или перхапсйоу нужно найти все заказы, соответствующие определенному продавцу. Если вы не хотите учитывать текст верхнего или нижнего регистра, есть несколько способов проверить, содержит ли ячейка.
Вы также можете использовать фильтр для поиска текста. Дополнительные сведения можно найти в разделе Фильтрация данных.
Поиск ячеек, содержащих текст
Чтобы найти ячейки, содержащие определенный текст, выполните указанные ниже действия.
Выделите диапазон ячеек, которые вы хотите найти.
Чтобы выполнить поиск на всем листе, щелкните любую ячейку.
На вкладке Главная в группе Редактирование нажмите кнопку найти _амп_и выберите пункт найти.
В поле найти введите текст (или числа), который нужно найти. Вы также можете выбрать последний поисковый запрос из раскрывающегося списка найти .
Примечание: В критериях поиска можно использовать подстановочные знаки.
Чтобы задать формат поиска, нажмите кнопку Формат и выберите нужные параметры в всплывающем окне Найти формат .
Нажмите кнопку Параметры , чтобы еще больше задать условия поиска. Например, можно найти все ячейки, содержащие данные одного типа, например формулы.
В поле внутри вы можете выбрать лист или книгу , чтобы выполнить поиск на листе или во всей книге.
Нажмите кнопку найти все или Найти далее.
Найдите все списки всех вхождений элемента, который нужно найти, и вы можете сделать ячейку активной, выбрав определенное вхождение. Вы можете отсортировать результаты поиска » найти все «, щелкнув заголовок.
Примечание: Чтобы остановить поиск, нажмите клавишу ESC.
Проверка ячейки на наличие в ней текста
Для выполнения этой задачи используйте функцию текст .
Проверка соответствия ячейки определенному тексту
Используйте функцию Если , чтобы вернуть результаты для указанного условия.
Проверка соответствия части ячейки определенному тексту
Для выполнения этой задачи используйте функции Если, Поиски функция номер .
Примечание: Функция Поиск не учитывает регистр.