
history 24 октября 2021 г.
- Группы статей
- Последовательности Чисел
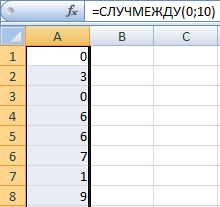
Пусть дана некая числовая последовательность, значения которой содержатся в отдельной строке или столбце. Будем искать в столбце с данными повтор такой последовательности.
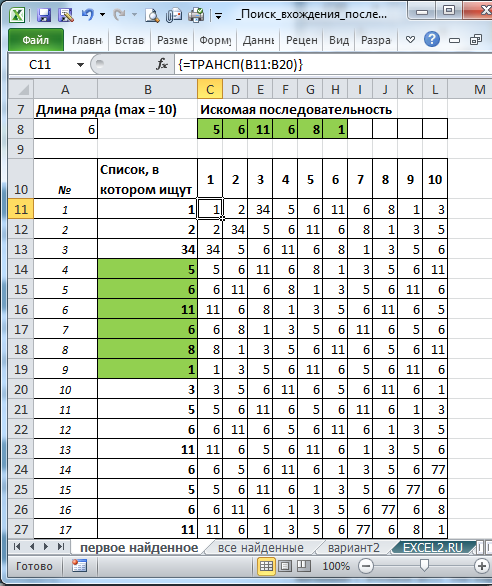
На картинке выше Искомая последовательность размещена в строке 7 и выделена зеленым (шесть чисел). Поиск производится в столбце В, начиная с ячейки В11. На картинке показана найденная последовательность, которая также выделена зеленым для наглядности.
Найти последовательность можно разными способами, в статье приведено их 2.
Примечание: Приведенные в статье формулы будут работать во всех версиях MS EXCEL — EXCEL 365, Excel 2021/2019/2016/2013/2010/2007 и Excel 97–2003.
Способ 1
В 11-й строке (с этой строки начинается список) выведем первые 10 значений из списка. Это можно сделать формулой массиваТРАНСП() или простыми формулами.
Совет: О транспонировании строк подробно написано в этом разделе https://excel2.ru/gruppy-statey/transponirovanie. В этих статьях показано как можно транспонировать диапазоны и без формул массива.
Чтобы ввести функцию ТРАНСП()
- выделите диапазон ячеек С11:L11,
- затем в Строке формул введите =ТРАНСП(B11:B20),
- нажмите CTRL+SHIFT+ENTER.
После копирования указанных ячеек вниз (также нужно сначала выделить диапазон С11:L11 и протянуть вниз с помощью Маркера заполнения. В итоге будет сформирован массив чисел как на рисунке выше. В строке 12 будут размещены значения из списка, начиная со второго, в строке 13, начиная с третьего и т.д.
Теперь займемся построчным сравнением. В способе 1 это реализовано замысловатой формулой =НЕ(СУММПРОИЗВ(—(СМЕЩ(C11;;;;$A$8)<>СМЕЩ($C$8;;;;$A$8)))) в столбце N.
Разберем подробнее. Так как длина исходной последовательности может быть произвольной, то нам нужно «вырезать» из диапазона С8:L8 только те ячейки, которые содержат значения последовательности, а не пустые ячейки. Это сделано формулой СМЕЩ($C$8;;;;$A$8), где в А8 содержится длина последовательности. О функции СМЕЩ() читайте здесь.
Аналогично формируется диапазон для сравнения СМЕЩ(C11;;;;$A$8). Обратите внимание на отсутствие знаков $ абсолютной адресации. Т.к. этот диапазон должен изменяться при копировании формулы вниз (в отличие от первого диапазона).
Идем дальше — посмотрим на выражение (СМЕЩ(C11;;;;$A$8)<>СМЕЩ($C$8;;;;$A$8)). Для первого сравнения (строка 11 и исходная последовательность) это выражение даст {ИСТИНА;ИСТИНА;ИСТИНА;ИСТИНА;ИСТИНА;ИСТИНА}, т.е. ни одно из значений не совпало (этот массив можно получить выделив в Строке формул это выражение и нажать F9). Оно и понятно, исходная последовательность 5; 6; 11; 6; 8; 1 ничего не имеет общего со значениями 11-й строки 1; 2; 34; 5; 6; 11 (если сравнивать поэлементно).
Совсем другое дело, если сравнивать со строкой 14. Выражение вернет {ЛОЖЬ;ЛОЖЬ;ЛОЖЬ;ЛОЖЬ;ЛОЖЬ;ЛОЖЬ}, что означает, что первый элемент исходной последовательности (5) равен значению из ячейки С14, второй (6) равно значению из ячейки D14, и т.д.
Затем подвергаем полученный массив преобразованию с помощью двойной смены знака (—), при этом ЛОЖЬ будет переведена в число 0, а ИСТИНА — в 1 (так устроен EXCEL: он хранит ИСТИНА как 1, а ЛОЖЬ как 0). Вместо двукратного умножения на -1, можно было прибавить 0 или возвести в степень 1. Любое математическое действие со значениями логического типа данных будет преобразовывать их в число 0 или 1.
Функция СУММПРОИЗВ() просто сложит все 0 или 1. В результате получим 0 только если все значения попарно равны между собой. Можно вместо СУММПРОИЗВ() использовать функцию СУММ(), но тогда нам пришлось бы вводить ее как формулу массива.
Наконец, функция НЕ() переводит числовые значения в логический тип данных, изменяя на противоположное значение: 0 — будет переведен в ИСТИНА, а любое другое число в ЛОЖЬ. Можно обойтись и без этой функции, тогда будет выведено число от 0 (все значения совпали) до 6 (ни одно не совпало).
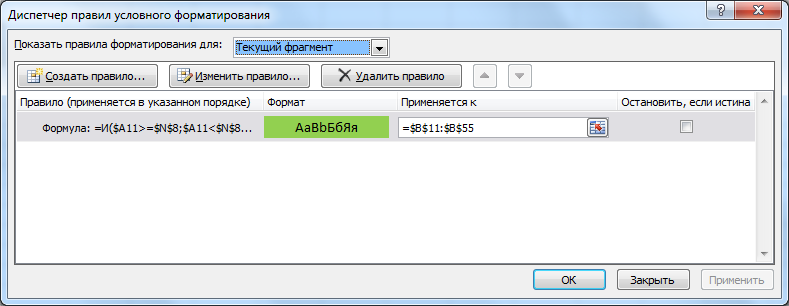
Формула в ячейке N8 =ПОИСКПОЗ(ИСТИНА;N11:N55;0) вернет номер позиции первой ячейки со значением ИСТИНА (их может быть несколько, об этом ниже). Начиная с этой позиции списка будет располагаться искомая последовательность. Ее можно выделить условным форматированием.
Чтобы настроить Условное форматирование нам потребуется написать простое правило =И($A11>=$N$8;$A11<$N$8+$A$8).
Вариантов написания формулы для поиска последовательности множество, например, формула =(СУММПРОИЗВ(—(СМЕЩ(C11;;;;$A$8)=СМЕЩ($C$8;;;;$A$8))))=$A$8, которая вернет ИСТИНА в тех же строках, что и предыдущая формула.
На листе «все найденные» приведен поиск сразу всех вхождений последовательности.
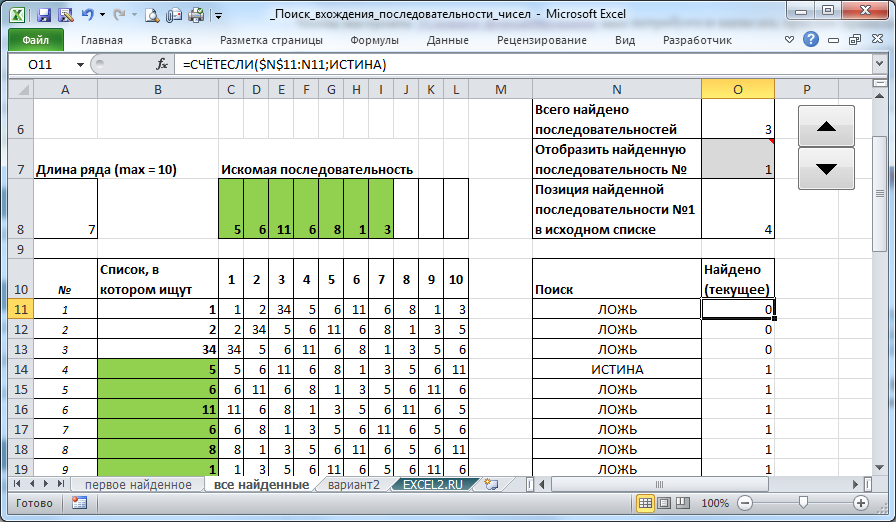
Для реализации этого решения добавлено несколько формул:
- используйте формулу =СУММПРОИЗВ(—N11:N55) чтобы найти общее количество исходных последовательностей в списке (ячейка О6)
- формулы в столбце О: =СЧЁТЕСЛИ($N$11:N11;ИСТИНА), будут показывать сколько последовательностей найдено в строках выше.
- в ячейке О7 (серая ячейка) для удобства сформирован выпадающий список, это реализовано формулой =СМЕЩ($A$11;;;$O$6). Если, например, найдено 3 совпадения, то будет сформирован список 1; 2; 3. Выбирая нужный повтор в списке будут подсвечены соответствующие найденные последовательности.
- если кому не удобно пользоваться выпадающим списком можно нажимать на элемент управления Счетчик.
В этой статье разжеваны все формулы, если и теперь не все понятно, то нужно почитать статьи на нашем сайте excel2.ru, на которые ведут ссылки в этой статье.
Способ 2
На листе Вариант2 приведено другое решение этой задачи (подсвечивается только первая найденная последовательность).
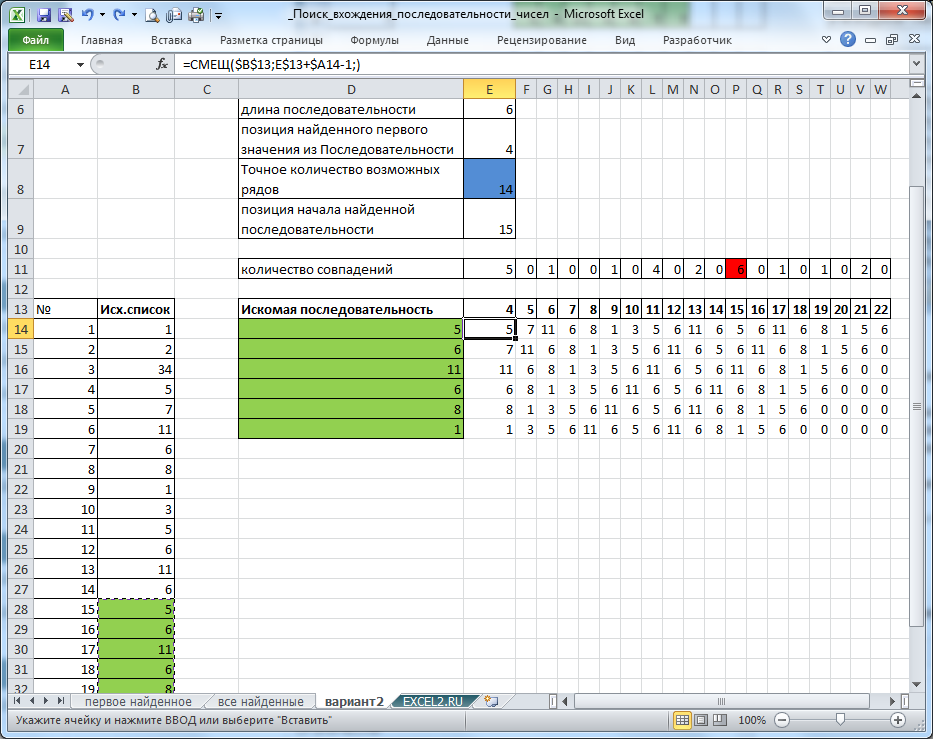
В этом варианте нет формулы массива ТРАНСП(). Исходный список многократно повторяется начиная со строки 14 и ниже (при этом последовательно отбрасывается первое значение из предыдущей строки и производится смещение всего списка на 1 позицию влево). Такой подход позволяет сравнивать исходный список (столбец D с зелеными ячейками) со столбцами значений, вырезанными из исходного списка.
При увеличении длины исходного списка соответственно растет количество столбцов в этих строках. При большой длине списка это не удобно.
Количество совпавших значений выводится в строке 11. Если это число совпадений равно длине искомой последовательности, то это значение подсвечивается красным. Найденная позиция отображается в строке 13.
Вариантов решения этой задачи множество, поэтому если будете решать самостоятельно, то наверняка придете к другому варианту решения.
У нас есть последовательность чисел, состоящая из практически независимых элементов, которые подчиняются заданному распределению. Как правило, равномерному распределению.
Сгенерировать случайные числа в Excel можно разными путями и способами. Рассмотрим только лучше из них.
Функция случайного числа в Excel
- Функция СЛЧИС возвращает случайное равномерно распределенное вещественное число. Оно будет меньше 1, больше или равно 0.
- Функция СЛУЧМЕЖДУ возвращает случайное целое число.
Рассмотрим их использование на примерах.
Выборка случайных чисел с помощью СЛЧИС
Данная функция аргументов не требует (СЛЧИС()).
Чтобы сгенерировать случайное вещественное число в диапазоне от 1 до 5, например, применяем следующую формулу: =СЛЧИС()*(5-1)+1.

Возвращаемое случайное число распределено равномерно на интервале [1,10].
При каждом вычислении листа или при изменении значения в любой ячейке листа возвращается новое случайное число. Если нужно сохранить сгенерированную совокупность, можно заменить формулу на ее значение.
- Щелкаем по ячейке со случайным числом.
- В строке формул выделяем формулу.
- Нажимаем F9. И ВВОД.
Проверим равномерность распределения случайных чисел из первой выборки с помощью гистограммы распределения.
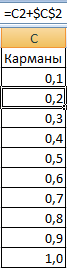
- Сформируем «карманы». Диапазоны, в пределах которых будут находиться значения. Первый такой диапазон – 0-0,1. Для следующих – формула =C2+$C$2.
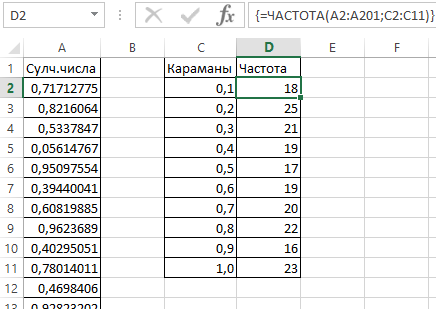
- Определим частоту для случайных чисел в каждом диапазоне. Используем формулу массива {=ЧАСТОТА(A2:A201;C2:C11)}.
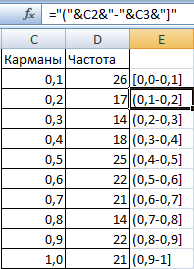
- Сформируем диапазоны с помощью знака «сцепления» (=»[0,0-«&C2&»]»).
- Строим гистограмму распределения 200 значений, полученных с помощью функции СЛЧИС ().
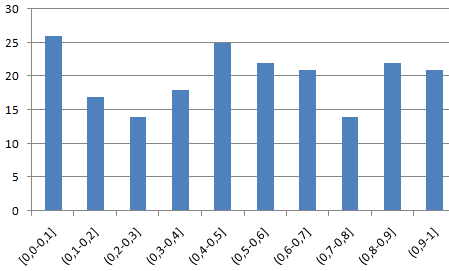
Диапазон вертикальных значений – частота. Горизонтальных – «карманы».
Функция СЛУЧМЕЖДУ
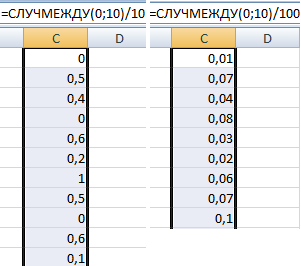
Синтаксис функции СЛУЧМЕЖДУ – (нижняя граница; верхняя граница). Первый аргумент должен быть меньше второго. В противном случае функция выдаст ошибку. Предполагается, что границы – целые числа. Дробную часть формула отбрасывает.
Пример использования функции:
Случайные числа с точностью 0,1 и 0,01:
Как сделать генератор случайных чисел в Excel
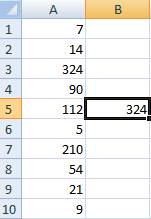
Сделаем генератор случайных чисел с генерацией значения из определенного диапазона. Используем формулу вида: =ИНДЕКС(A1:A10;ЦЕЛОЕ(СЛЧИС()*10)+1).
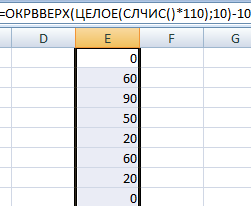
Сделаем генератор случайных чисел в диапазоне от 0 до 100 с шагом 10.
Из списка текстовых значений нужно выбрать 2 случайных. С помощью функции СЛЧИС сопоставим текстовые значения в диапазоне А1:А7 со случайными числами.
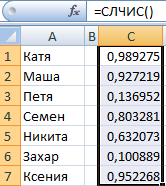
Воспользуемся функцией ИНДЕКС для выбора двух случайных текстовых значений из исходного списка.
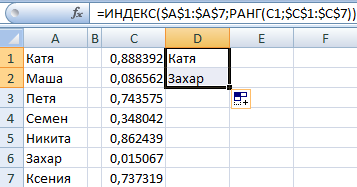
Чтобы выбрать одно случайное значение из списка, применим такую формулу: =ИНДЕКС(A1:A7;СЛУЧМЕЖДУ(1;СЧЁТЗ(A1:A7))).
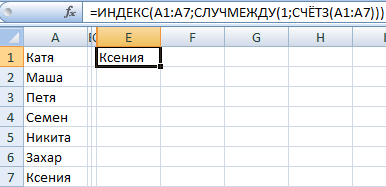
Генератор случайных чисел нормального распределения
Функции СЛЧИС и СЛУЧМЕЖДУ выдают случайные числа с единым распределением. Любое значение с одинаковой долей вероятности может попасть в нижнюю границу запрашиваемого диапазона и в верхнюю. Получается огромный разброс от целевого значения.
Нормальное распределение подразумевает близкое положение большей части сгенерированных чисел к целевому. Подкорректируем формулу СЛУЧМЕЖДУ и создадим массив данных с нормальным распределением.
Себестоимость товара Х – 100 рублей. Вся произведенная партия подчиняется нормальному распределению. Случайная переменная тоже подчиняется нормальному распределению вероятностей.
При таких условиях среднее значение диапазона – 100 рублей. Сгенерируем массив и построим график с нормальным распределением при стандартном отклонении 1,5 рубля.
Используем функцию: =НОРМОБР(СЛЧИС();100;1,5).
Программа Excel посчитала, какие значения находятся в диапазоне вероятностей. Так как вероятность производства товара с себестоимостью 100 рублей максимальная, формула показывает значения близкие к 100 чаще, чем остальные.
Перейдем к построению графика. Сначала нужно составить таблицу с категориями. Для этого разобьем массив на периоды:
- Определим минимальное и максимальное значение в диапазоне с помощью функций МИН и МАКС.
- Укажем величину каждого периода либо шаг. В нашем примере – 1.
- Количество категорий – 10.
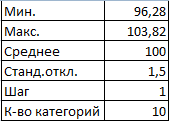
- Нижняя граница таблицы с категориями – округленное вниз ближайшее кратное число. В ячейку Н1 вводим формулу =ОКРВНИЗ(E1;E5).
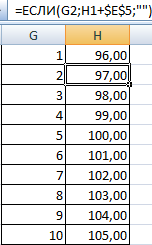
- В ячейке Н2 и последующих формула будет выглядеть следующим образом: =ЕСЛИ(G2;H1+$E$5;»»). То есть каждое последующее значение будет увеличено на величину шага.
- Посчитаем количество переменных в заданном промежутке. Используем функцию ЧАСТОТА. Формула будет выглядеть так:
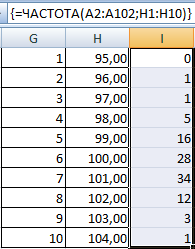
На основе полученных данных сможем сформировать диаграмму с нормальным распределением. Ось значений – число переменных в промежутке, ось категорий – периоды.
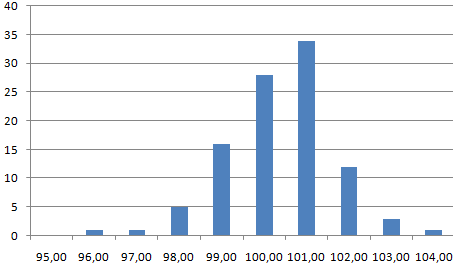
График с нормальным распределением готов. Как и должно быть, по форме он напоминает колокол.
Сделать то же самое можно гораздо проще. С помощью пакета «Анализ данных». Выбираем «Генерацию случайных чисел».
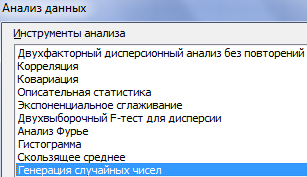
О том как подключить стандартную настройку «Анализ данных» читайте здесь.
Заполняем параметры для генерации. Распределение – «нормальное».
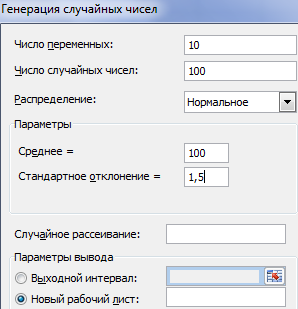
Жмем ОК. Получаем набор случайных чисел. Снова вызываем инструмент «Анализ данных». Выбираем «Гистограмма». Настраиваем параметры. Обязательно ставим галочку «Вывод графика».
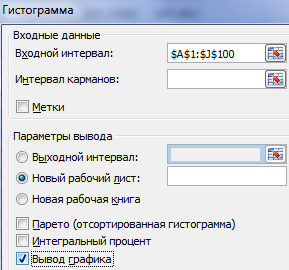
Получаем результат:
Скачать генератор случайных чисел в Excel
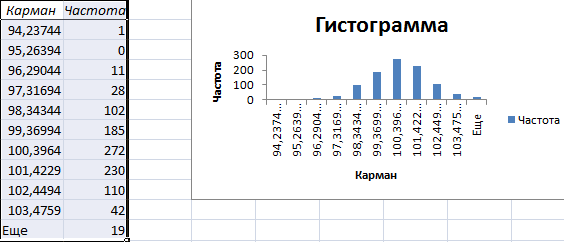
График с нормальным распределением в Excel построен.
Excel – одна из лучших программ для аналитика данных. А почти каждому человеку на том или ином этапе жизни приходилось иметь дело с цифрами и текстовыми данными и обрабатывать их в условиях жестких дедлайнов. Если вам и сейчас нужно это делать, то мы опишем техники, которые помогут существенно улучшить вам жизнь. А чтобы было более наглядно, покажем, как их воплощать, с помощью анимаций.
Содержание
- Анализ данных через сводные таблицы Excel
- Как работать со сводными таблицами
- Анализ данных с помощью 3D-карт
- Как работать с 3D-картами в Excel
- Лист прогноза в Excel
- Как работать с листом прогноза
- Быстрый анализ в Excel
- Как работать
Анализ данных через сводные таблицы Excel
Сводные таблицы – один из самых простых способов автоматизировать обработку информации. Он позволяет свести в кучу огромный массив данных, которые абсолютно не структурированы. Если его использовать, можно почти навсегда забыть о том, что такое фильтр и ручная сортировка. А чтобы их создать, достаточно нажать буквально пару кнопок и внести несколько несложных параметров в зависимости от того, какой способ представления результатов нужен конкретно вам в определенной ситуации.
Существует множество способов автоматизации анализа данных в Excel. Это как встроенные инструменты, так и дополнения, которые можно скачать на просторах интернета. Также есть дополнение «Пакет анализа», которое было разработано компанией Майкрософт. Она имеет все необходимые возможности, чтобы вы могли получать все необходимые результаты в одном файле Excel.
Пакет анализа данных, разработанный Майкрософт, можно использовать исключительно на едином листе в одну единицу времени. Если он будет обрабатывать информацию, расположенную на нескольких, то итоговая информация будет отображаться исключительно на одном. В других же будут показываться диапазоны без какой-либо значений, в которых есть исключительно форматы. Чтобы осуществить проанализировать информацию на нескольких листах, нужно использовать этот инструмент по отдельности. Это очень большой модуль, который поддерживает огромное количество возможностей, в частности, позволяет выполнять следующие типы обработки:
- Дисперсионный анализ.
- Корреляционный анализ.
- Ковариация.
- Вычисление скользящего среднего. Очень популярный метод в статистике и в трейдинге.
- Получать случайные числа.
- Выполнять операции с выборкой.
Эта надстройка не активирована по умолчанию, но входит в стандартный пакет. Чтобы ею воспользоваться, необходимо ее включить. Для этого сделайте следующие шаги:
- Перейдите в меню «Файл», и там найдите кнопку «Параметры». После этого перейдите в «Надстройки». Если же вы установили 2007 версию Эксель, то нужно нажать на кнопку «Параметры Excel», которая находится в меню Office.
- Далее появляется всплывающее меню, озаглавленное словом «Управление». Там находим пункт «Надстройки Excel», нажимаем на него, а потом – на кнопку «Перейти». Если же вы используете компьютер Apple, то достаточно открыть вкладку «Средства» в меню, а потом в раскрывающемся перечне найти пункт «Надстройки для Excel».
- В том диалоге, который появился после этого, нужно поставить галочку возле пункта «Пакет анализа», после чего подтвердить свои действия, нажав кнопку «ОК».
В некоторых ситуациях может оказаться так, что этого дополнения найти не удалось. В этом случае его не будет в перечне аддонов. Для этого надо нажать на кнопку «Обзор». Может также появиться информация о том, что пакет полностью отсутствует на этом компьютере. В этом случае необходимо его установить. Для этого нужно нажать на кнопку «Да».
Перед тем, как включить пакет анализа, необходимо сначала активировать VBA. Для этого его нужно загрузить таким же способом, как и саму надстройку.
Как работать со сводными таблицами
Первоначальная информация может быть какой-угодно. Это могут быть сведения о продажах, доставке, отгрузках продукции и так далее. Независимо от этого, последовательность шагов будет всегда одинаковой:
- Откройте файл, в котором содержится таблица.
- Выделите диапазон ячеек, которые мы будем анализировать с помощью сводной таблицы.
- Откройте вкладку «Вставка, и там надо найти группу «Таблицы», где есть кнопка «Сводная таблица». Если же используется компьютер под операционной системой Mac OS, то нужно открыть вкладку «Данные», и эта кнопка будет находиться во вкладке «Анализ».
- После этого откроется диалог с заголовком «Создание сводной таблицы».
- Затем выставите такое отображение данных, которое соответствует выделенному диапазону.
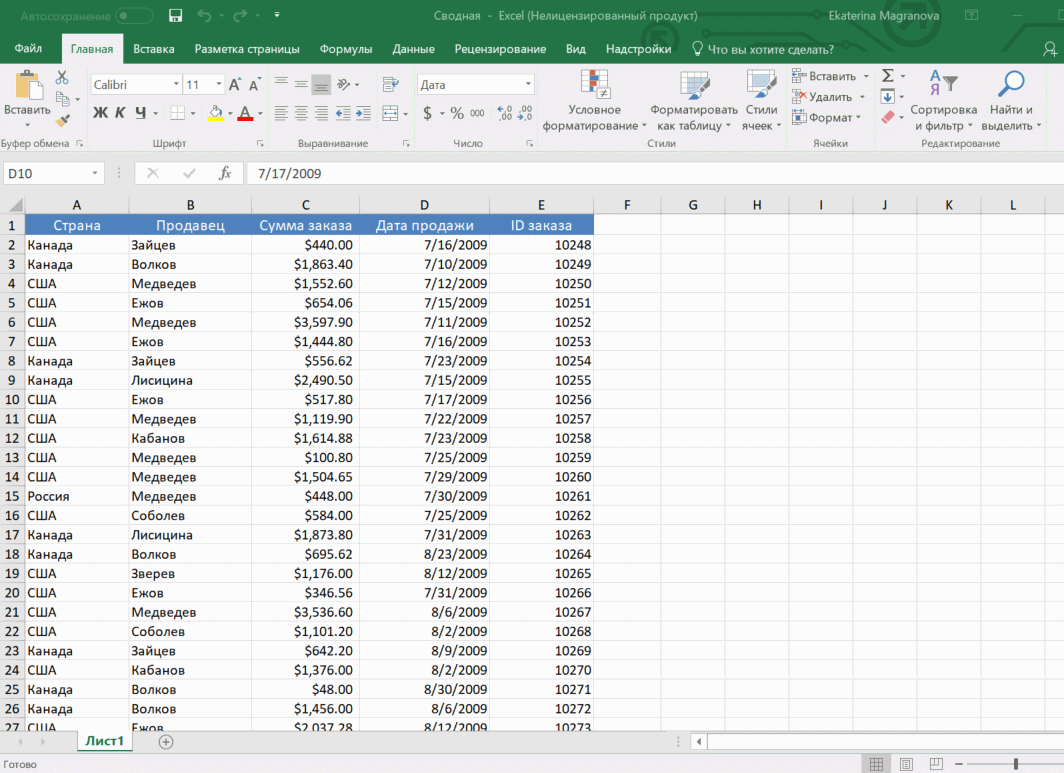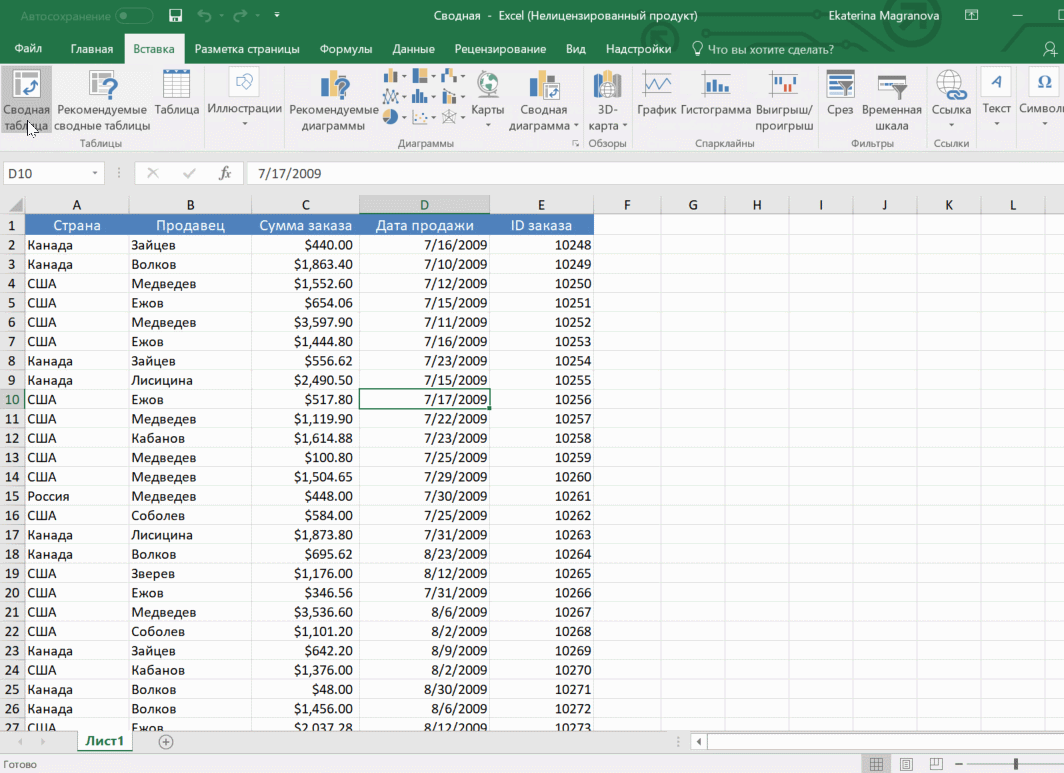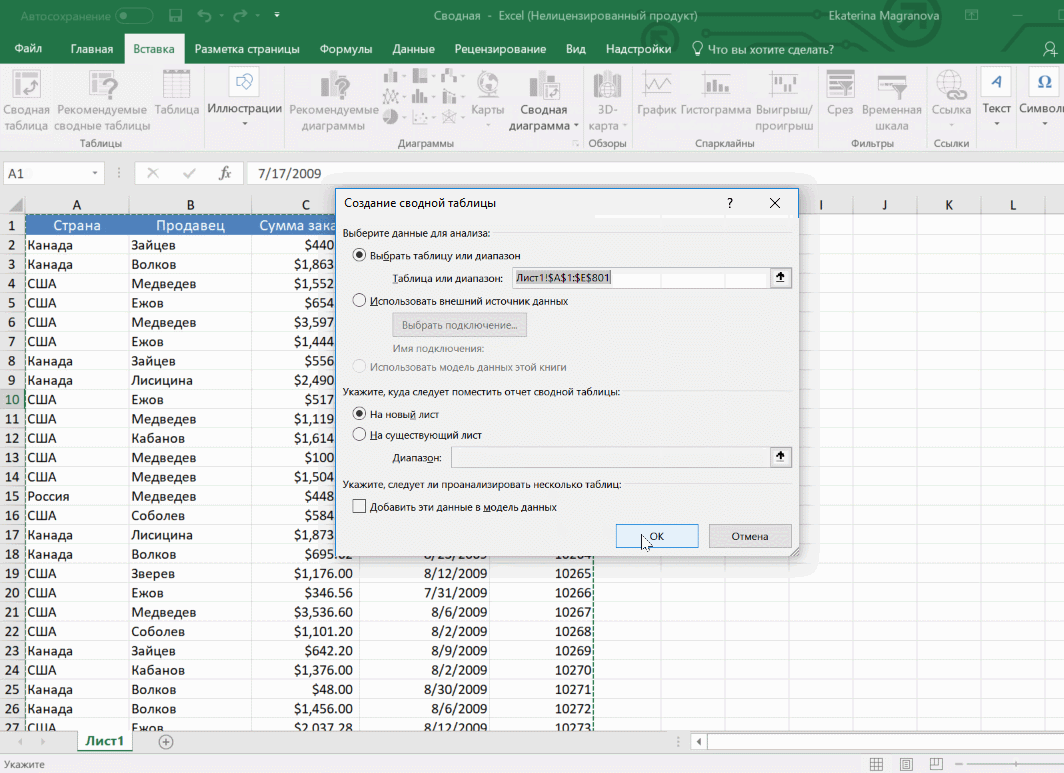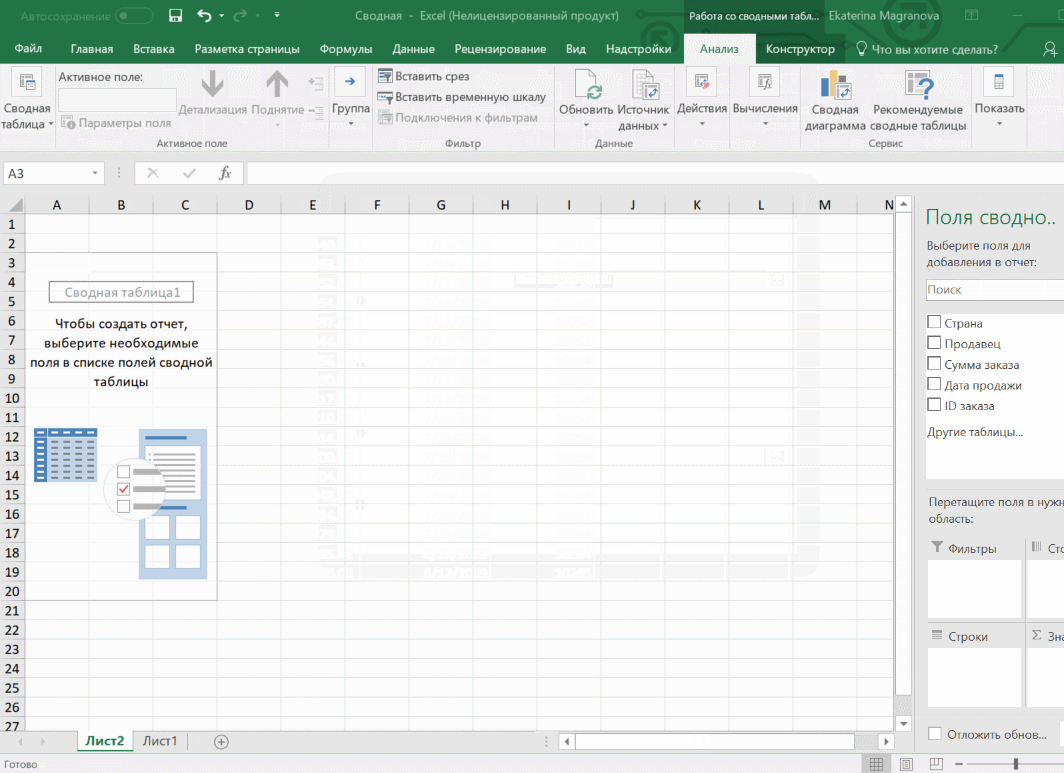
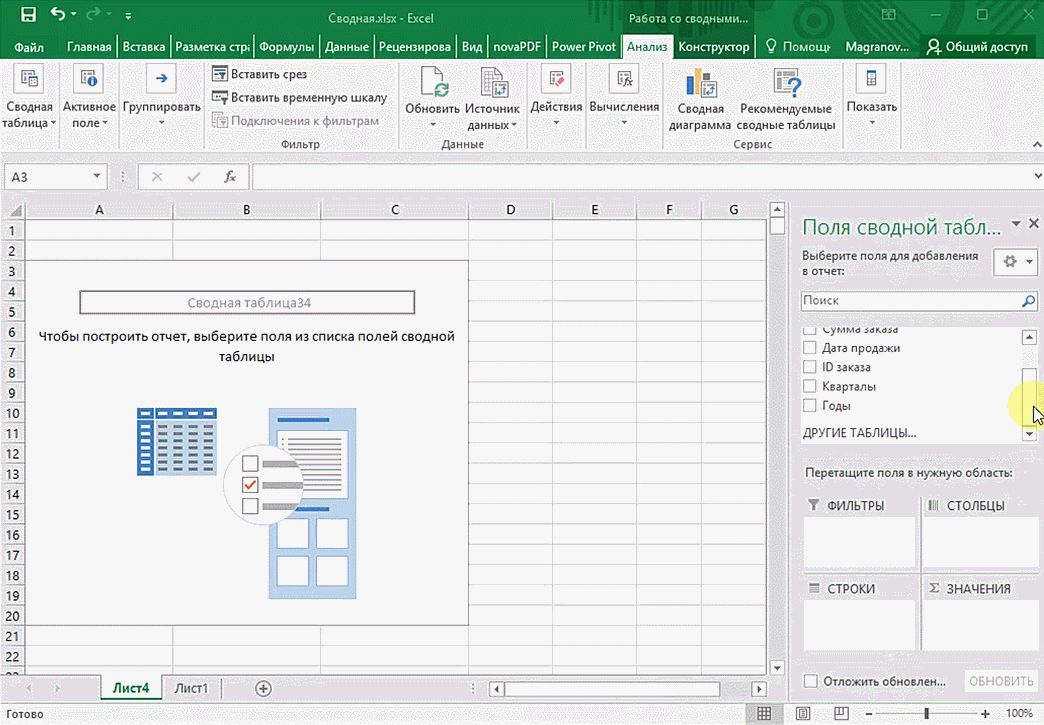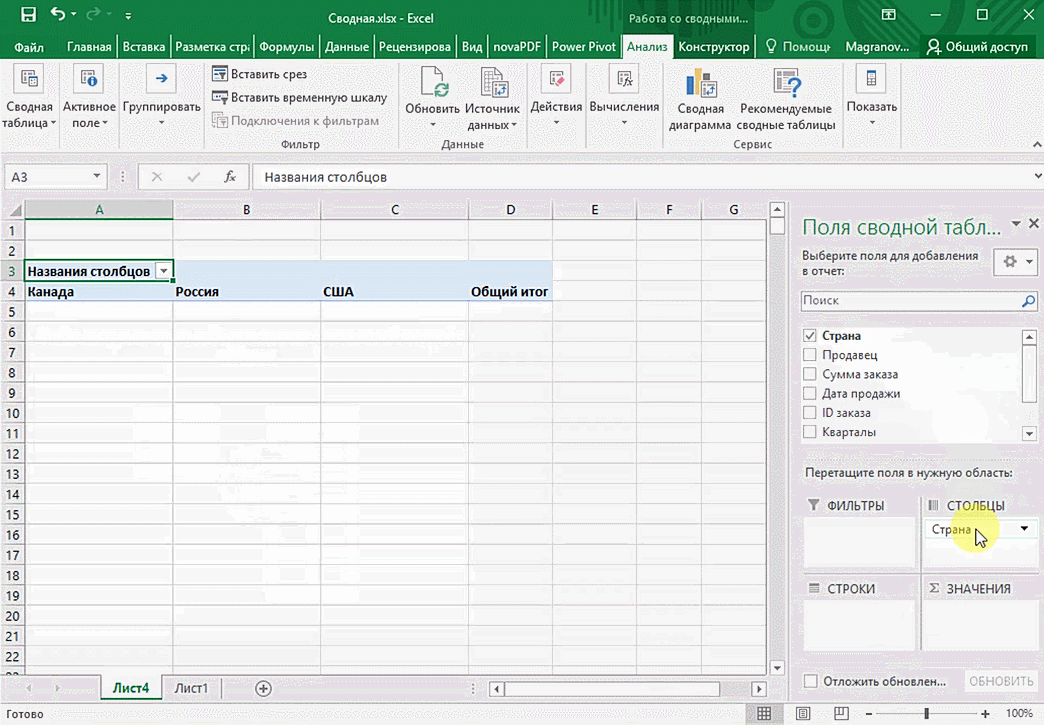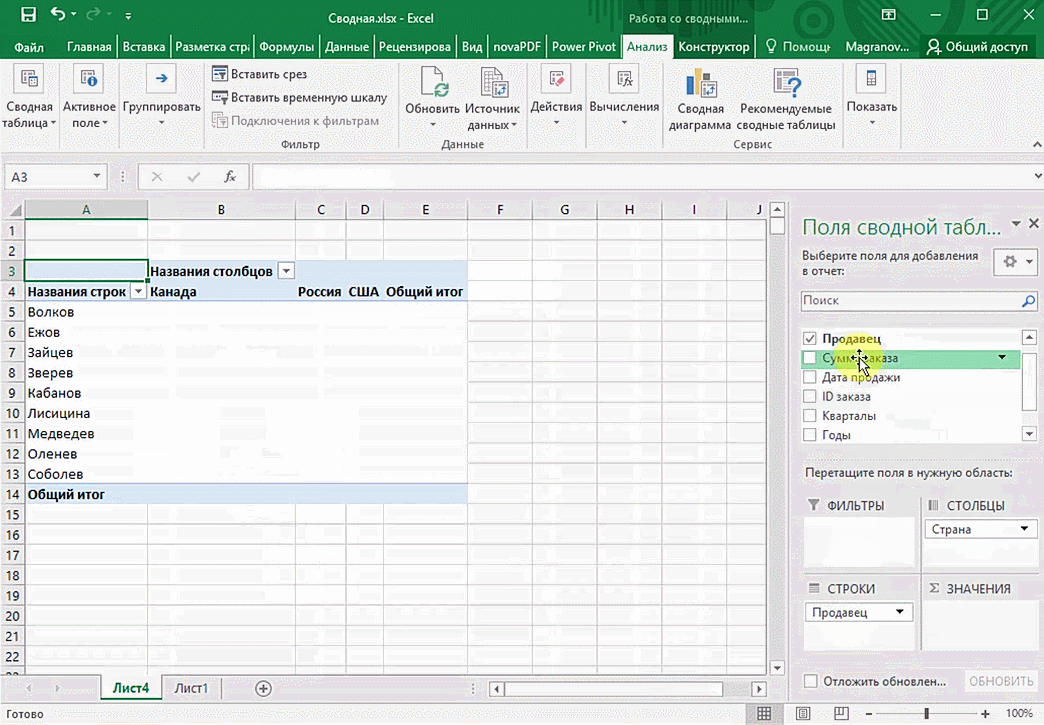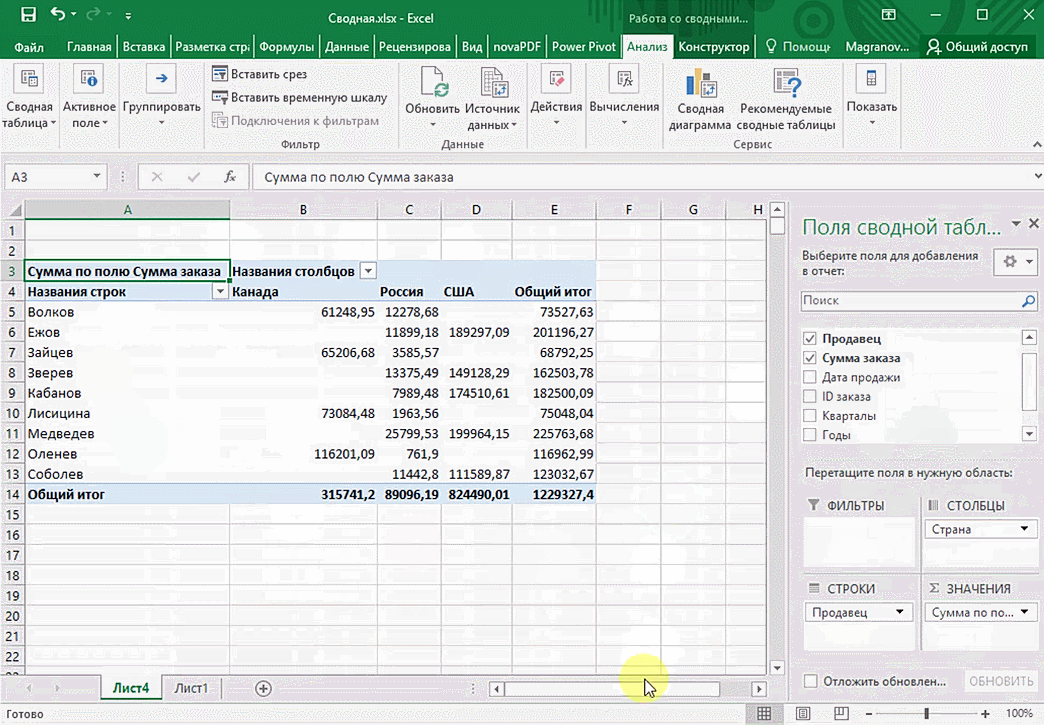
Мы открыли таблицу, информация в которой никоим образом не структурирована. Чтобы это сделать, можно воспользоваться настройками полей сводной таблицы в правой стороне экрана. Например, отправим в поле «Значения» «Сумму заказов», а информацию про продавцов и дату продажи – в строки таблицы. Исходя из данных, которые содержатся в этой таблице, автоматически определились суммы. Если есть необходимость, можно открыть информацию по каждому году, кварталу или месяцу. Это позволит получить детальную информацию, которая надо в конкретный момент.
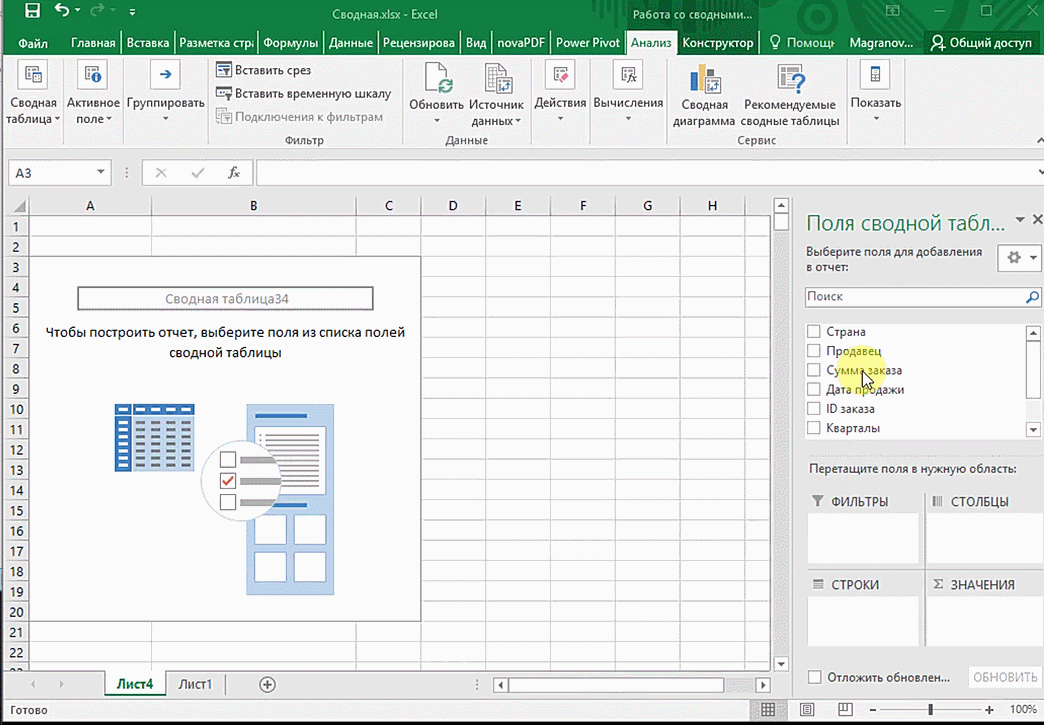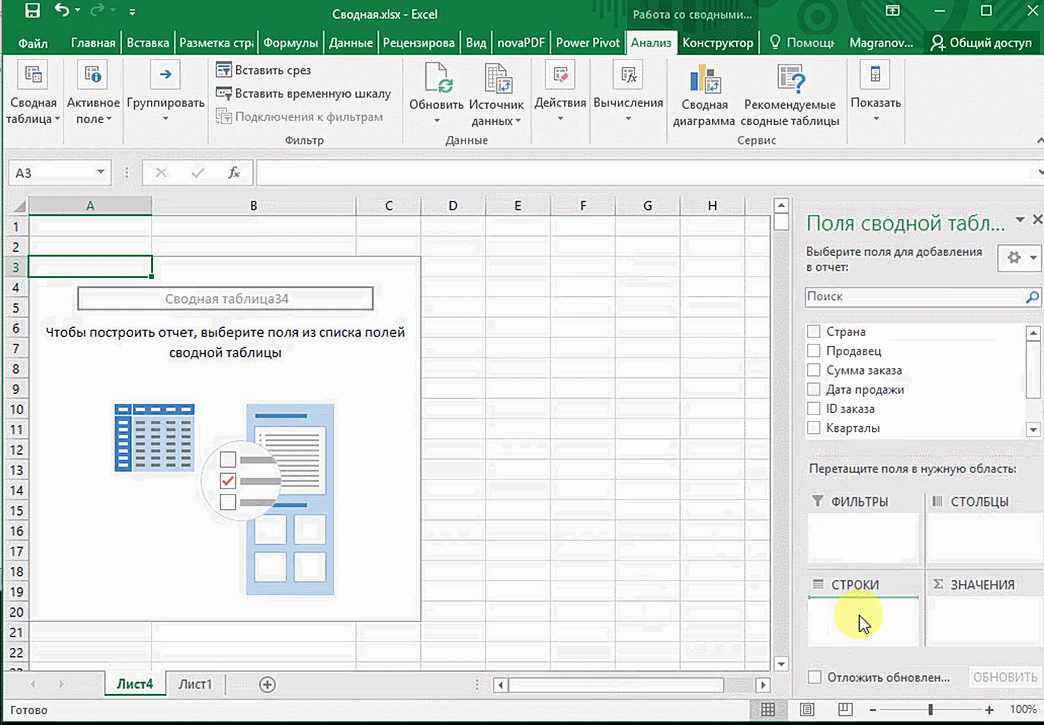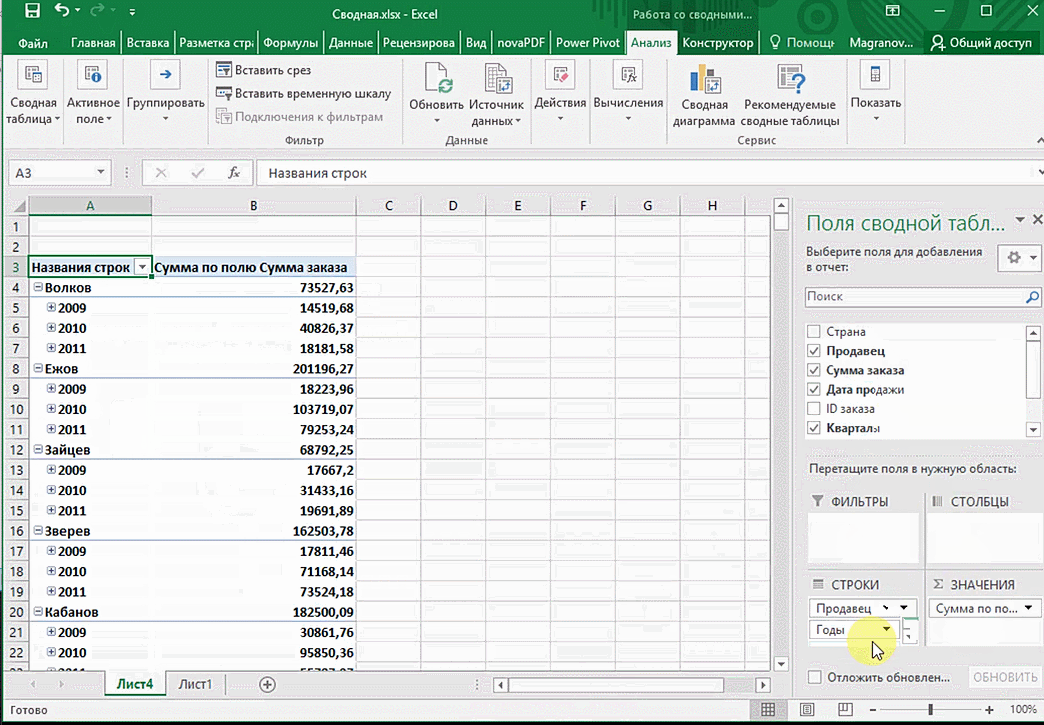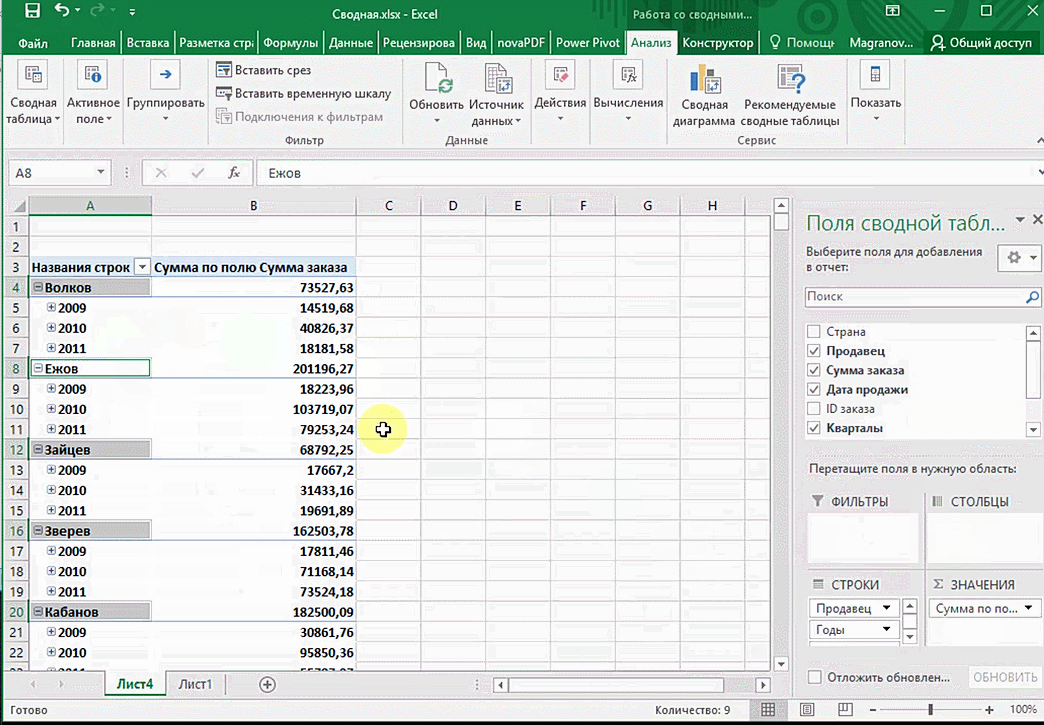
От того, сколько колонок есть, будет отличаться и набор имеющихся параметров. Например, общее число столбцов – 5. И нам надо просто разместить и выбрать их верным образом, а показать сумму. В таком случае выполняем действия, показанные на этой анимации.
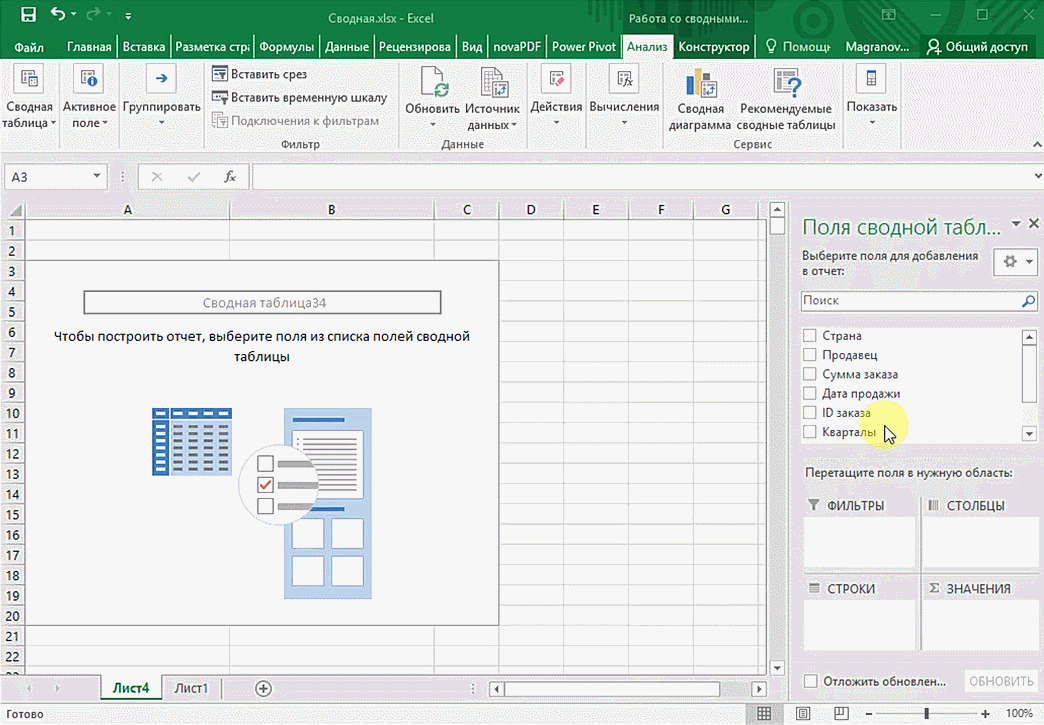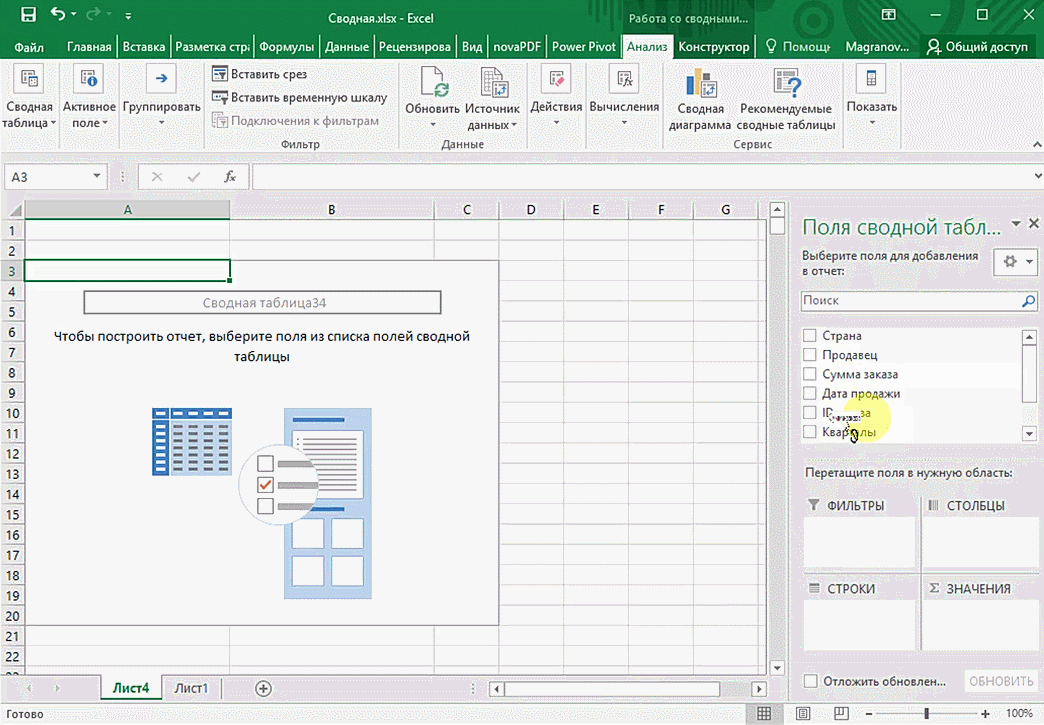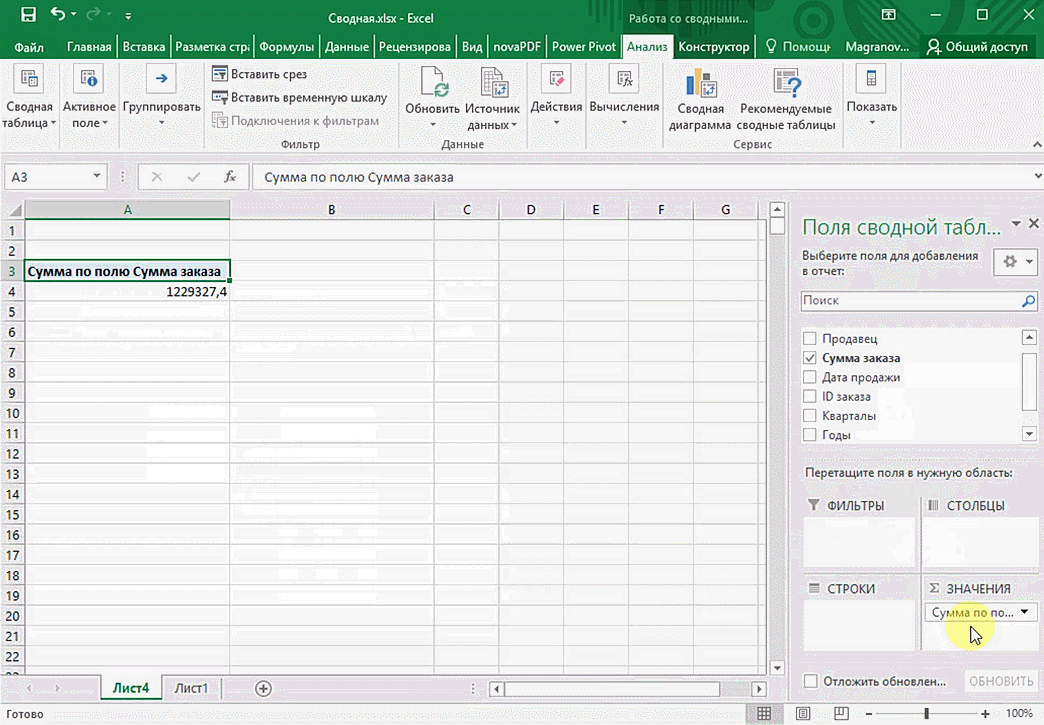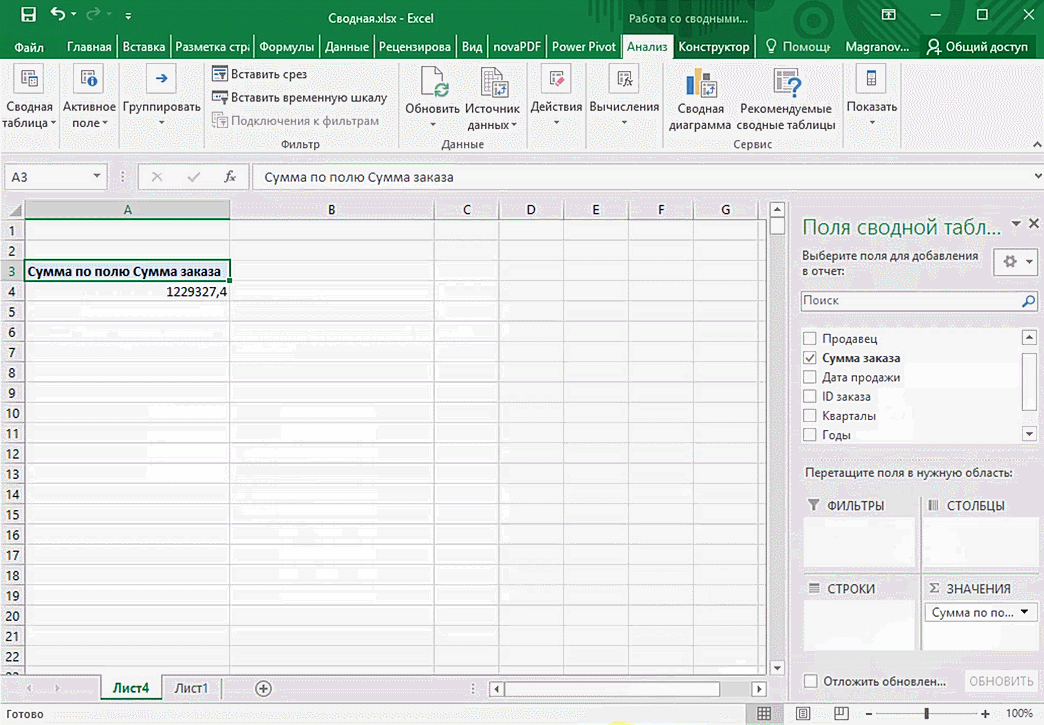
Можно сводную таблицу конкретизировать, указав, например, страну. Для этого мы включаем пункт «Страна».
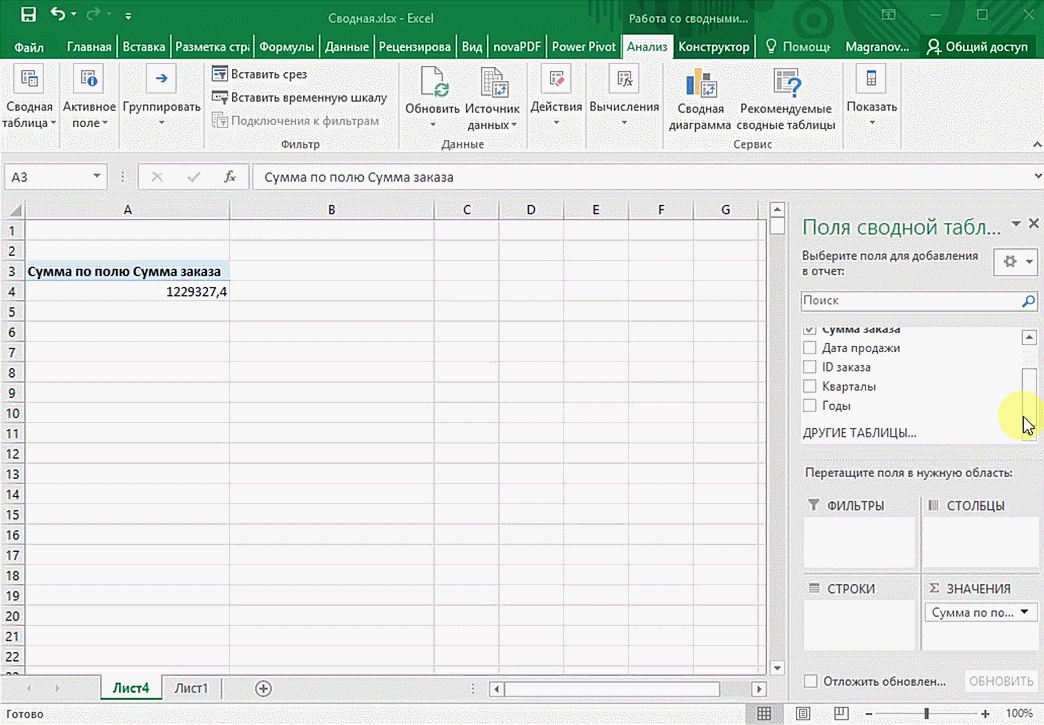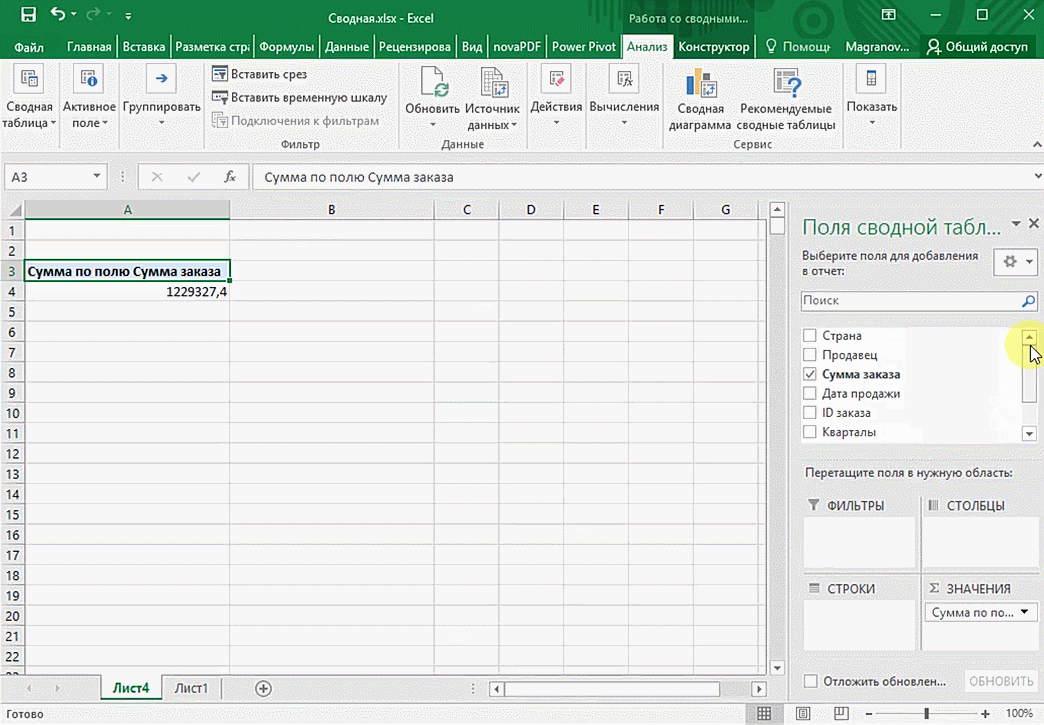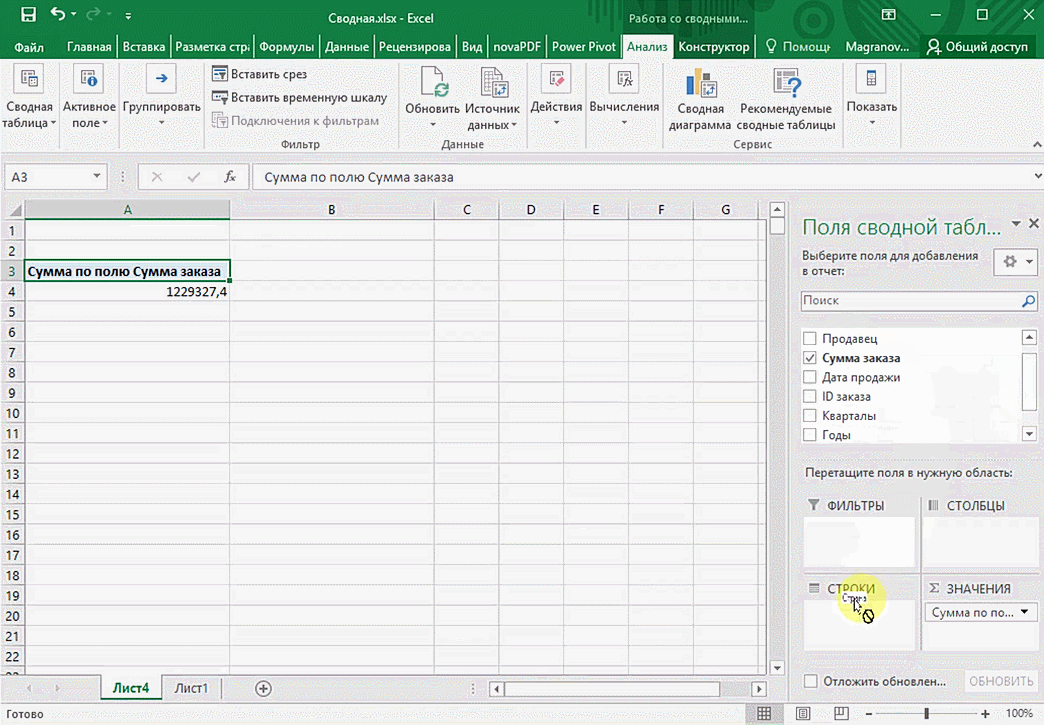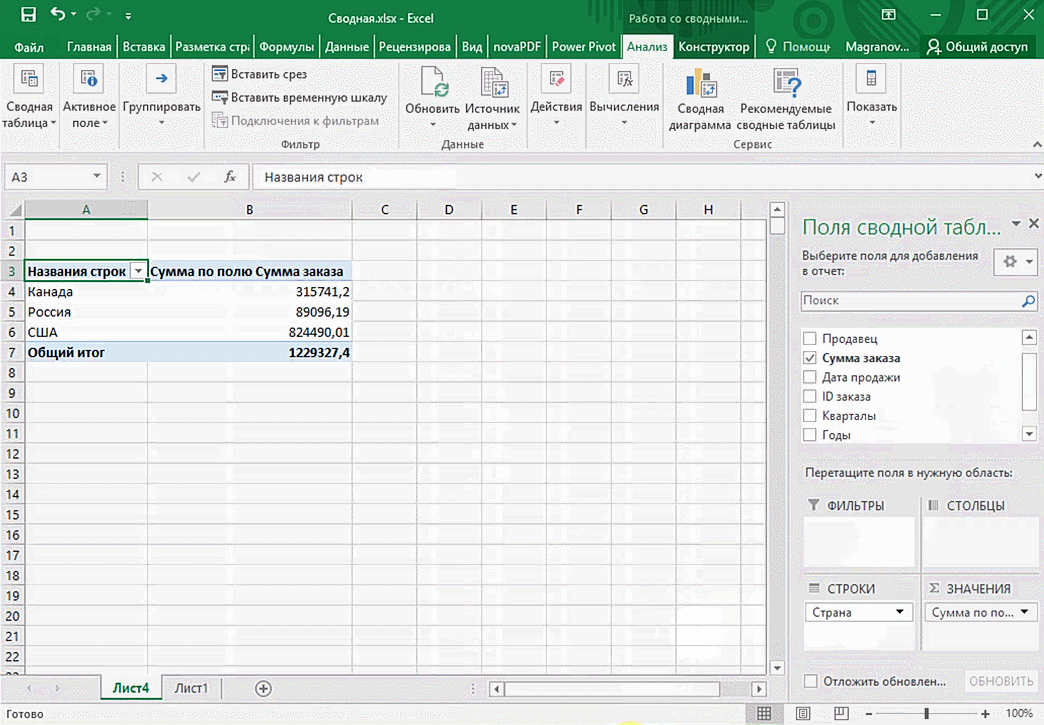
Можно также посмотреть информацию про продавцов. Для этого мы заменяем колонку «Страна» на «Продавец». Результат получится следующий.
Анализ данных с помощью 3D-карт
Данный метод визуального представления с географической привязкой дает возможность искать закономерности, привязанные к регионам, а также анализировать информацию этого типа.
Преимущество этого способа в том, что нет необходимости отдельно прописывать координаты. Необходимо просто правильно написать географическое положение в таблице.
Как работать с 3D-картами в Excel
Последовательность действий, которую вам необходимо выполнить, чтобы работать с 3Д-картами, следующая:
- Откройте файл, в котором есть интересующий диапазон данных. Например, таблица, где есть колонка «Страна» или «Город».
- Информацию, которая будет показываться на карте, нужно сначала отформатировать, как таблицу. Для этого надо найти соответствующий пункт на вкладке «Главная».
- Выделите те ячейки, которые будут анализироваться.
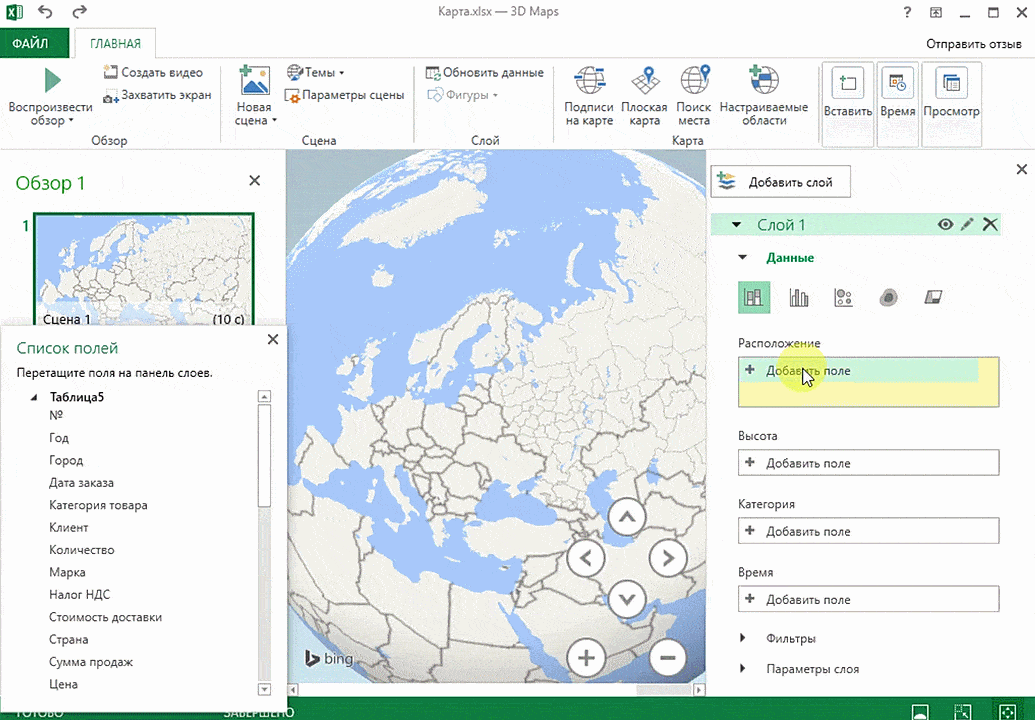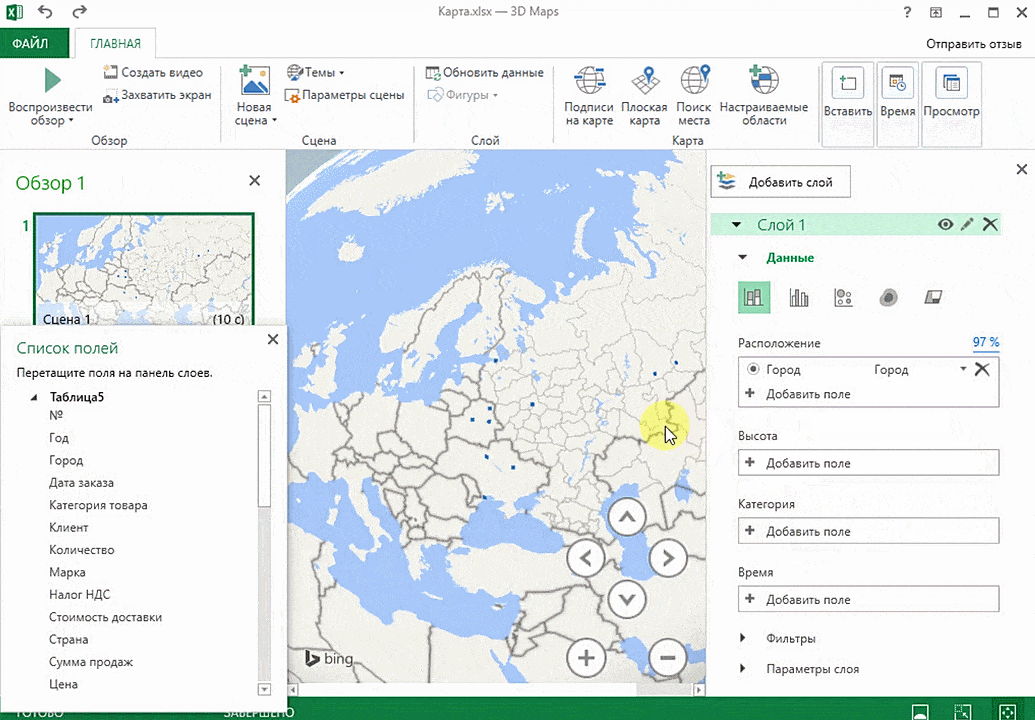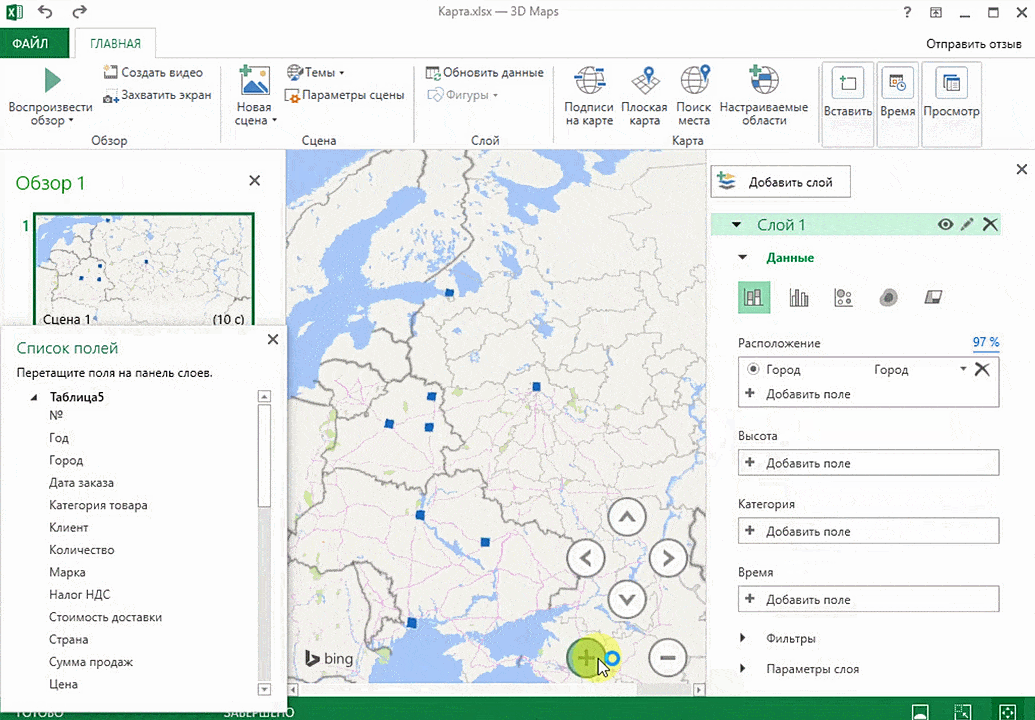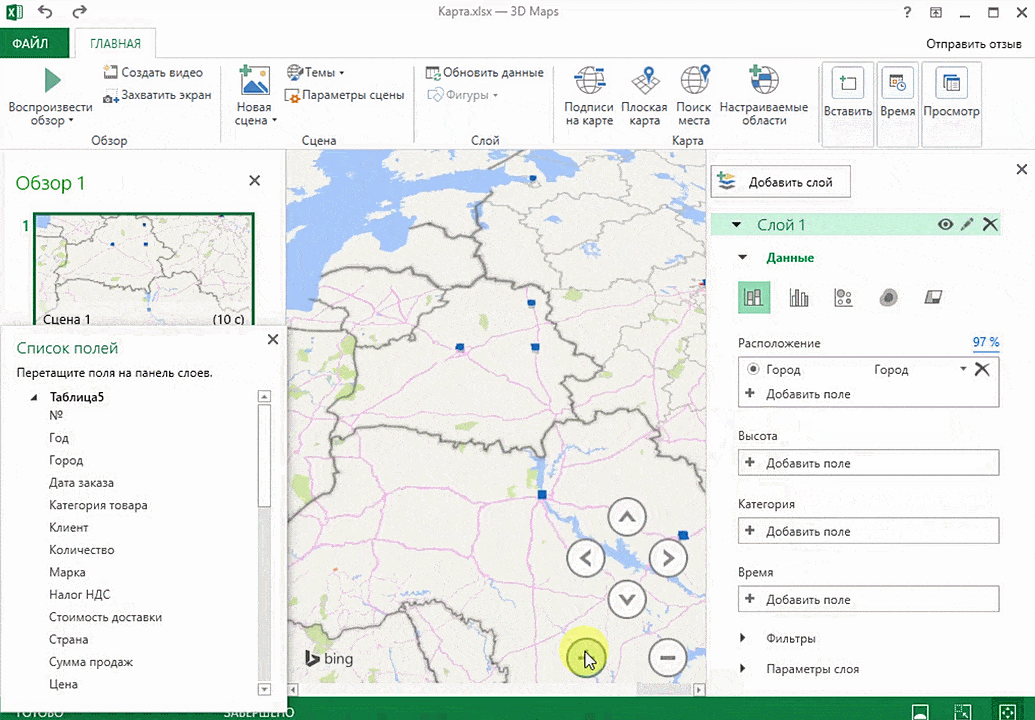
- После этого переходим на вкладку «Вставка», и там находим кнопку «3Д-карта».
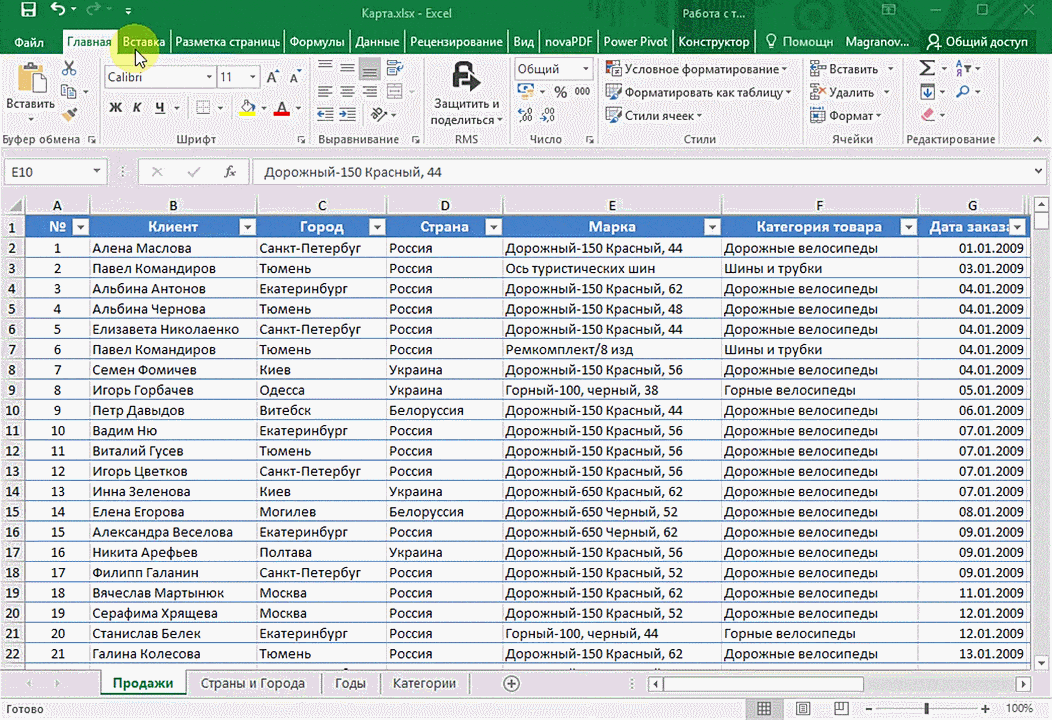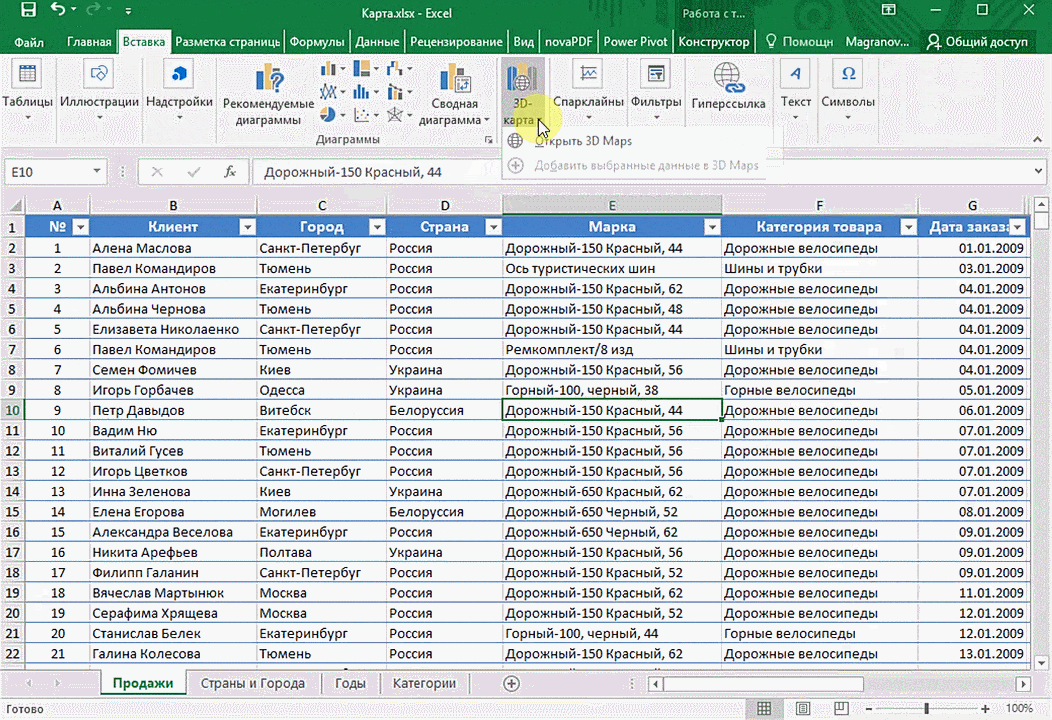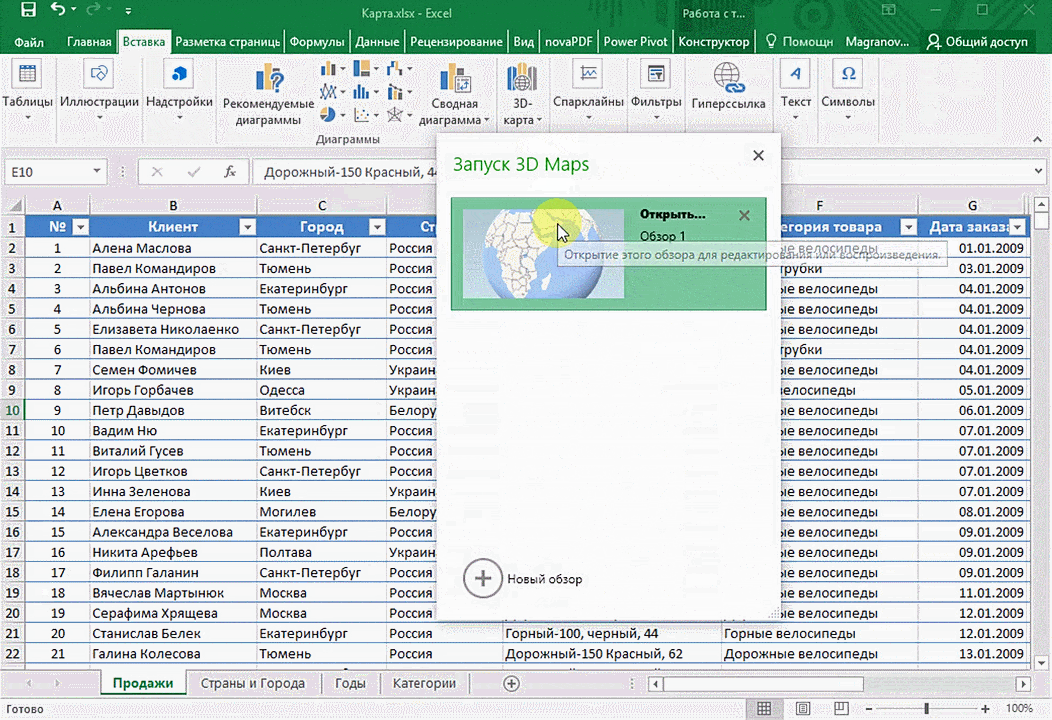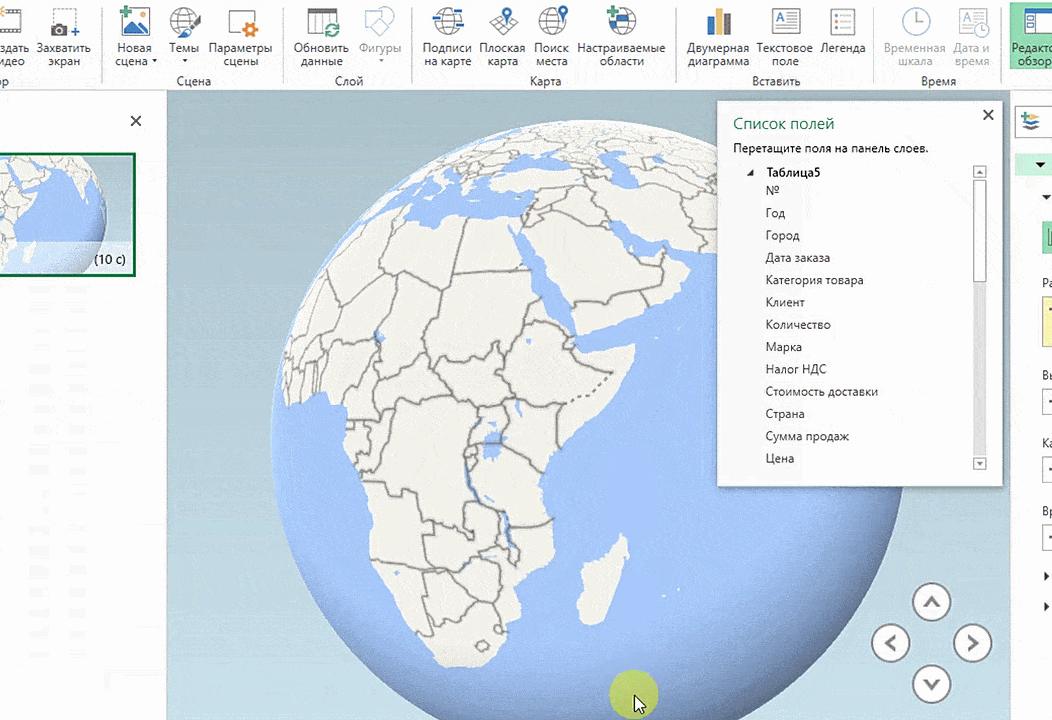
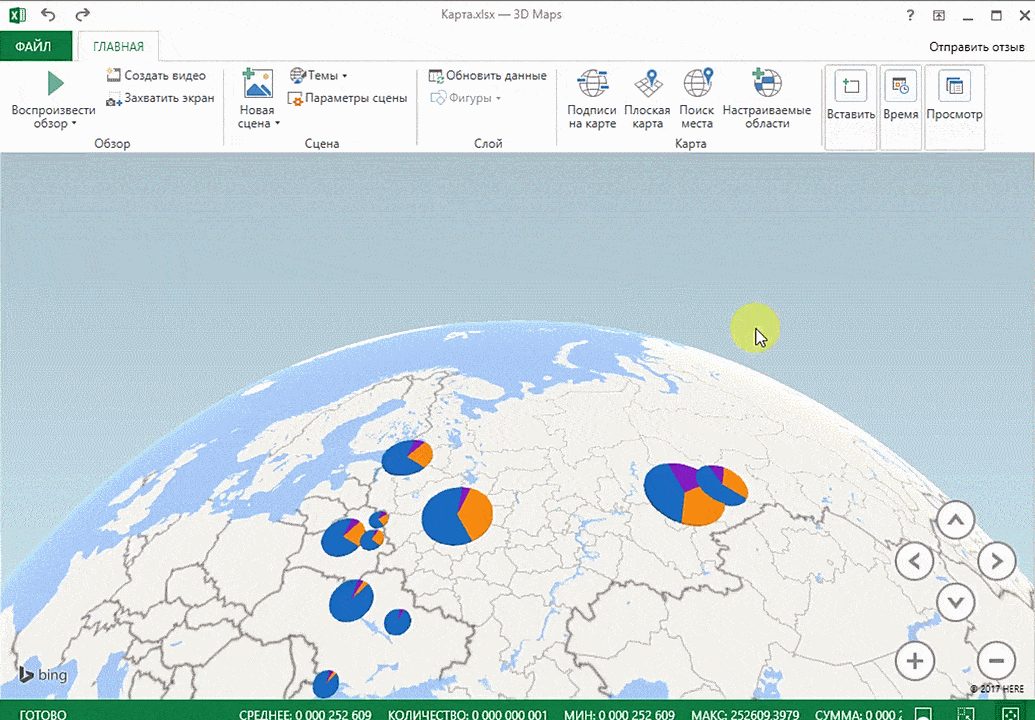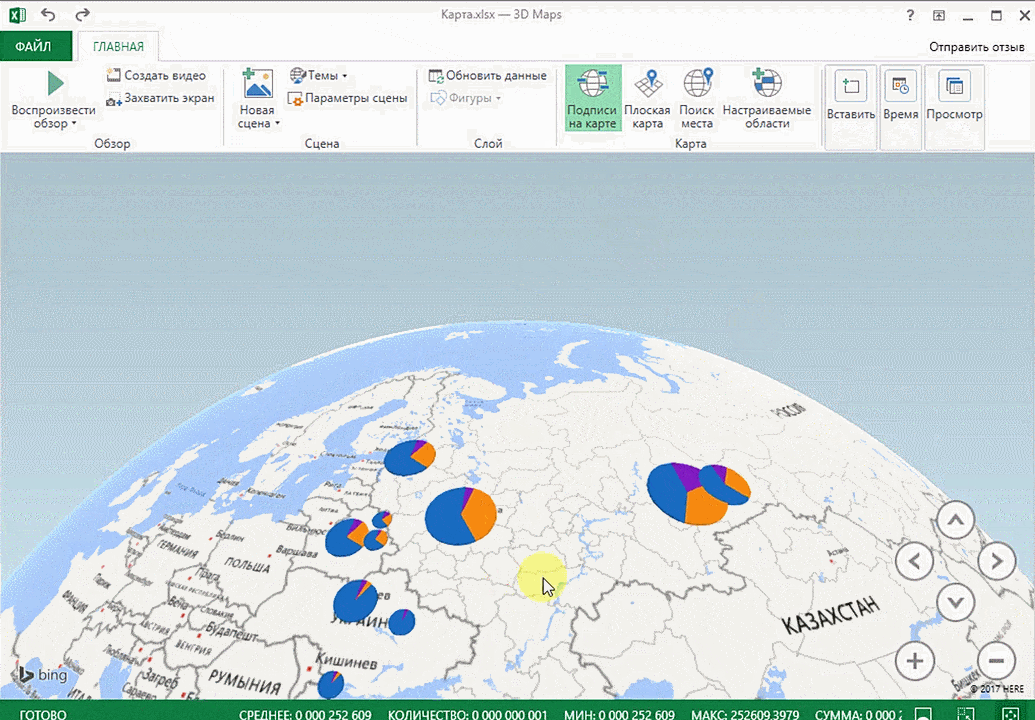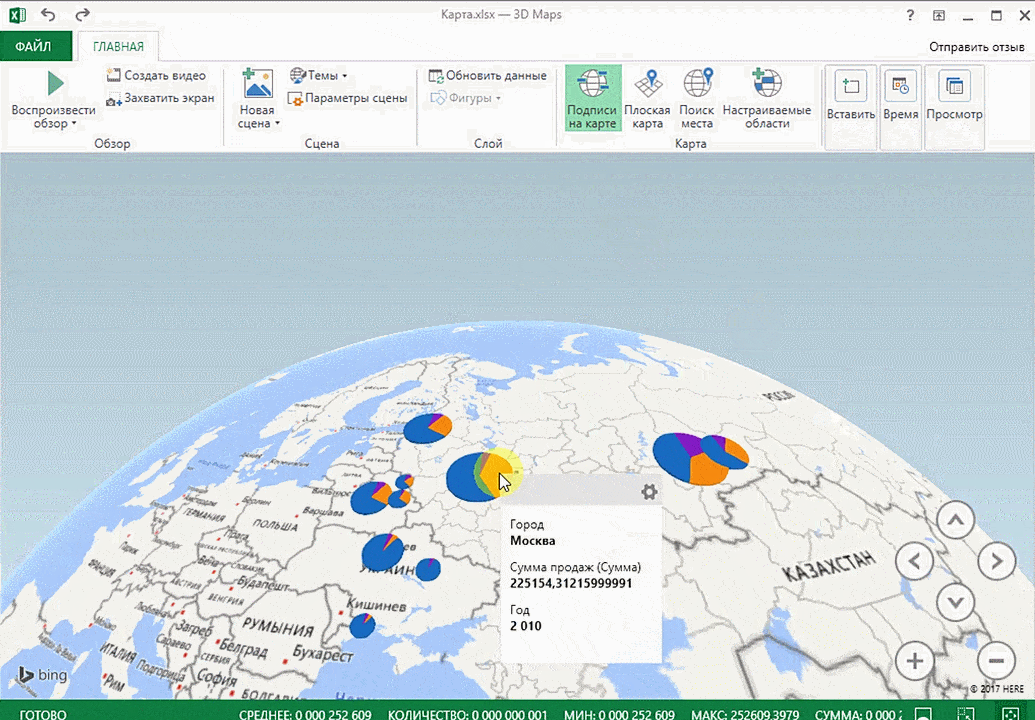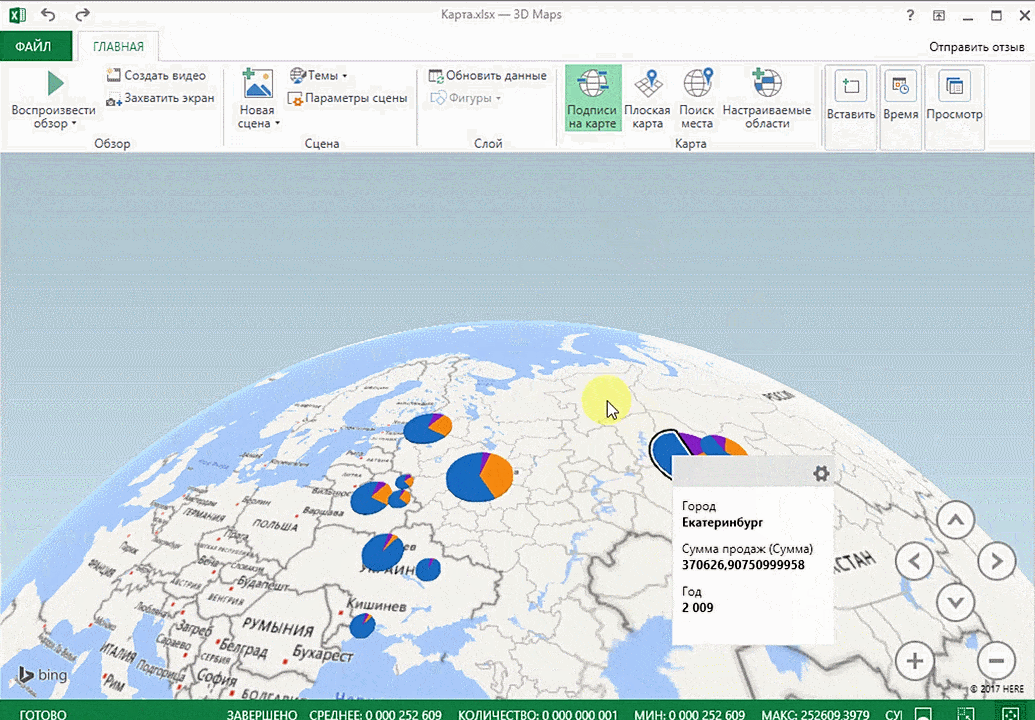
Затем показывается наша карта, где города в таблице представлены в виде точек. Но нам не особо нужно просто наличие информации о населенных пунктах на карте. Нам гораздо важнее видеть ту информацию, которая привязана к ним. Например, те суммы, которые можно показать, как высоту столбика. После того, как мы выполним действия, указанные на этой анимации, при наведении курсора на соответствующий столбик будут отображаться привязанные к нему данные.
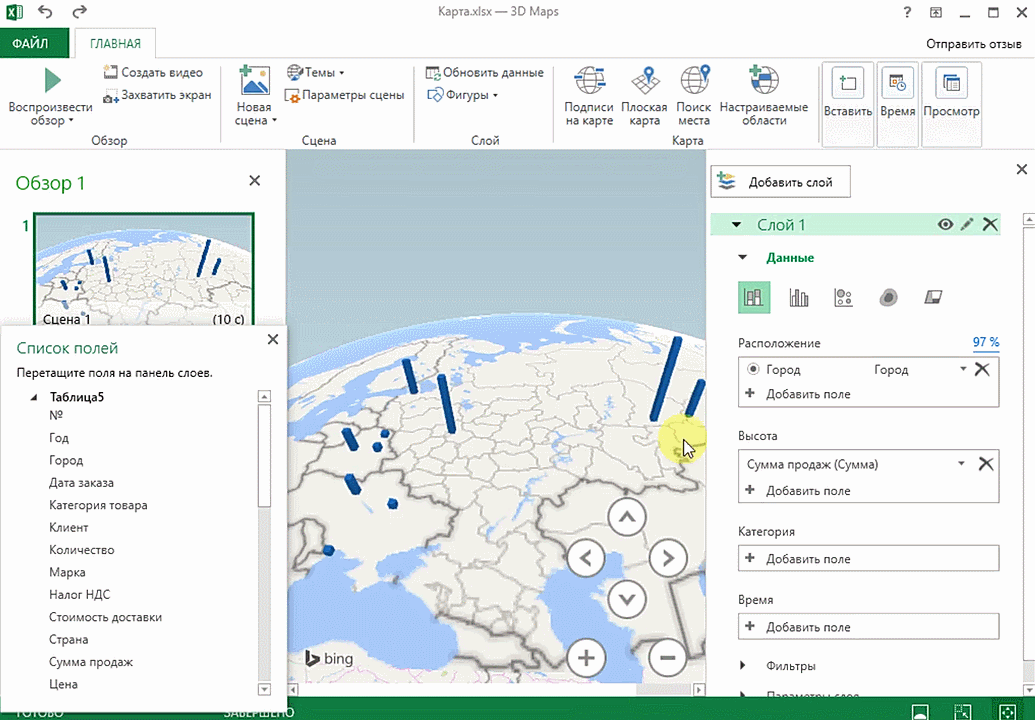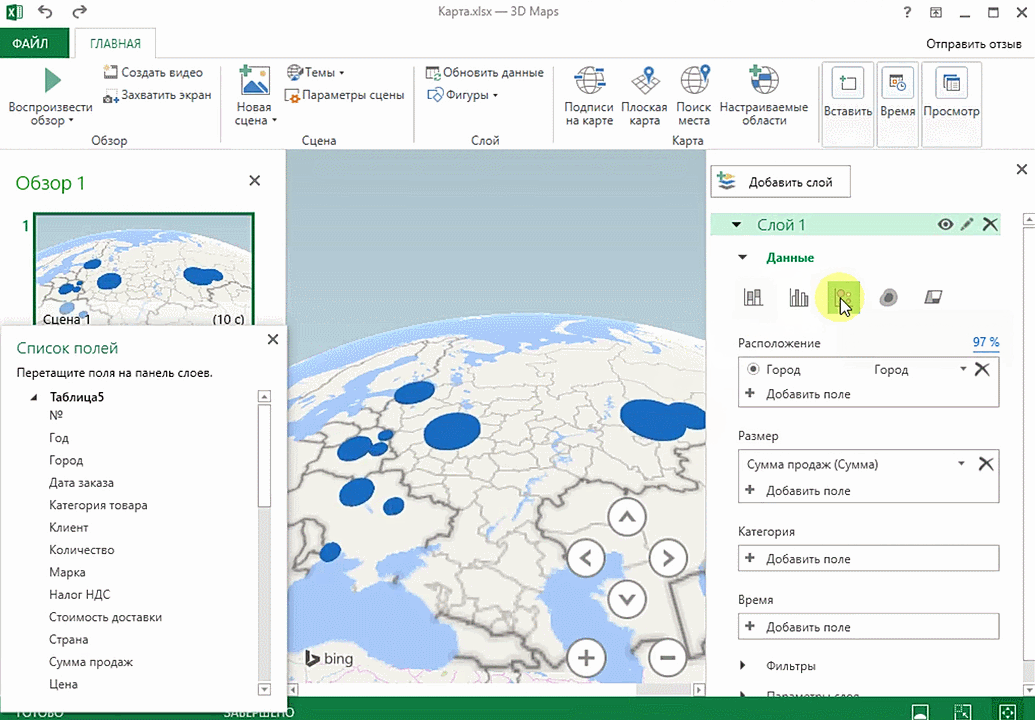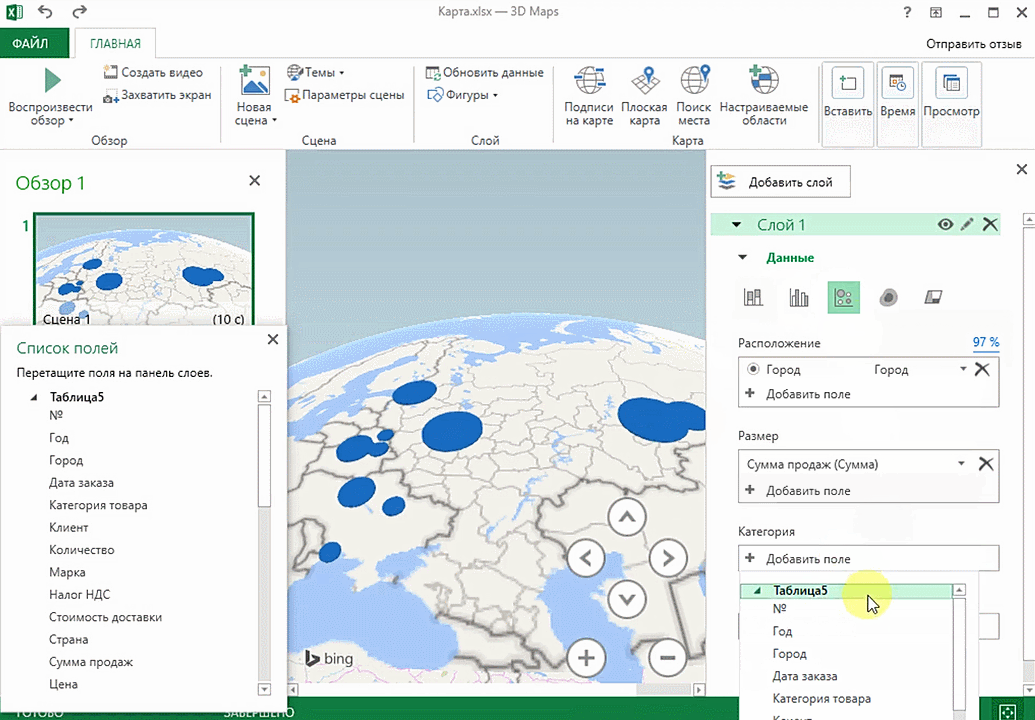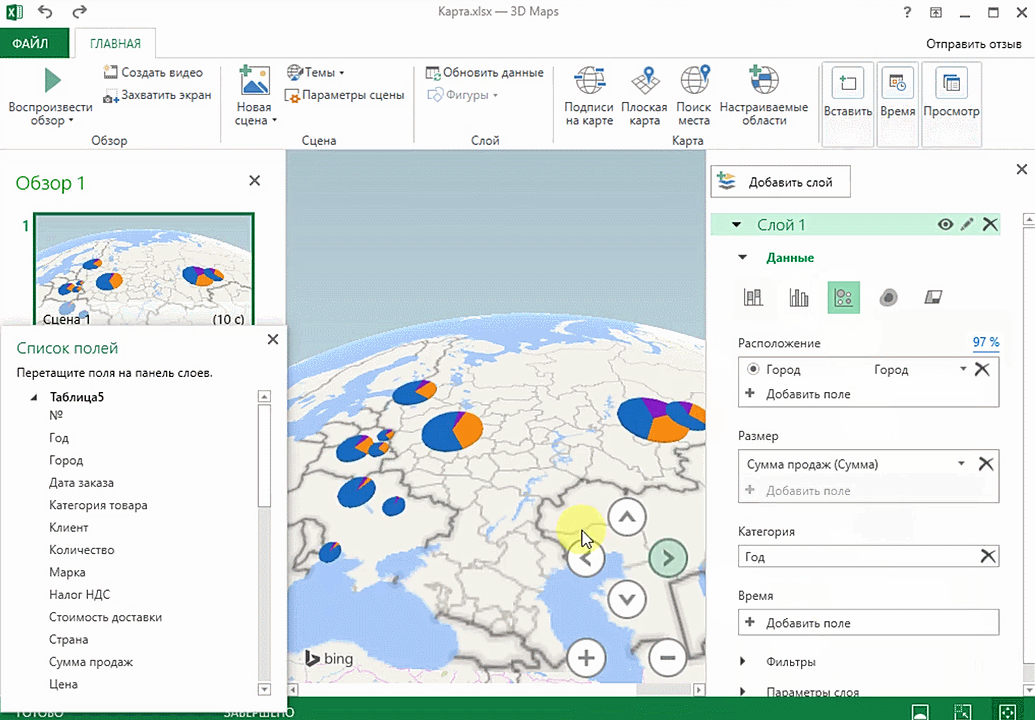
Также можно воспользоваться круговой диаграммой, которая является намного более информативной в некоторых случаях. От того, какая общая сумма по величине, зависит размер круга.
Лист прогноза в Excel
Нередко бизнес-процессы зависят от сезонных особенностей. И такие факторы надо обязательно принимать в учет на этапе планирования. Для этого существует специальный инструмент Excel, который понравится вам своей высокой точностью. Он значительно более функциональный, чем все описанные выше методы, какими бы отличными они ни были. Точно так же, очень широкой является сфера его использования – коммерческие, финансовые, маркетинговые и даже государственные структуры.
Важно: чтобы рассчитать прогноз, необходимо получить информацию за предыдущее время. От того, насколько долгосрочные данные, зависит качество прогнозирования. Рекомендуется иметь данные, которые разбиты по одинаковым интервалам (например, поквартально или помесячно).
Как работать с листом прогноза
Чтобы работать с листом прогноза, необходимо выполнять следующие действия:
- Откройте файл, в котором содержится большой объем информации по тем показателям, которые нам надо проанализировать. Например, в течение прошлого года (хотя чем больше, тем лучше).
- Выделите две строки с информацией.
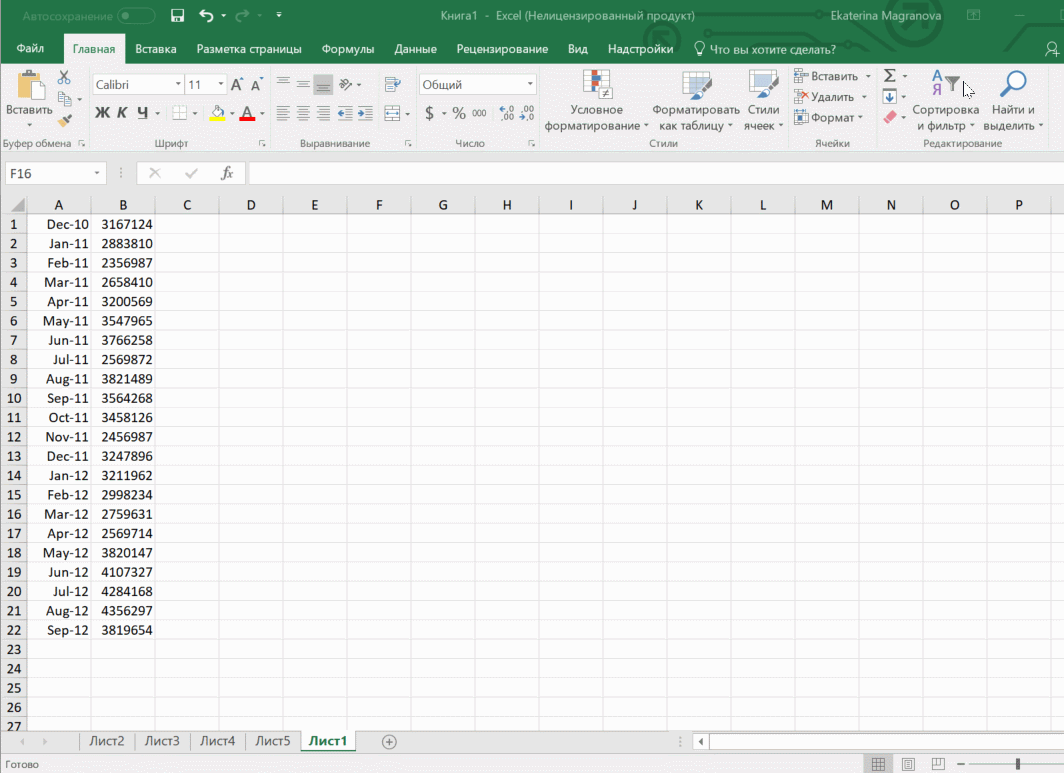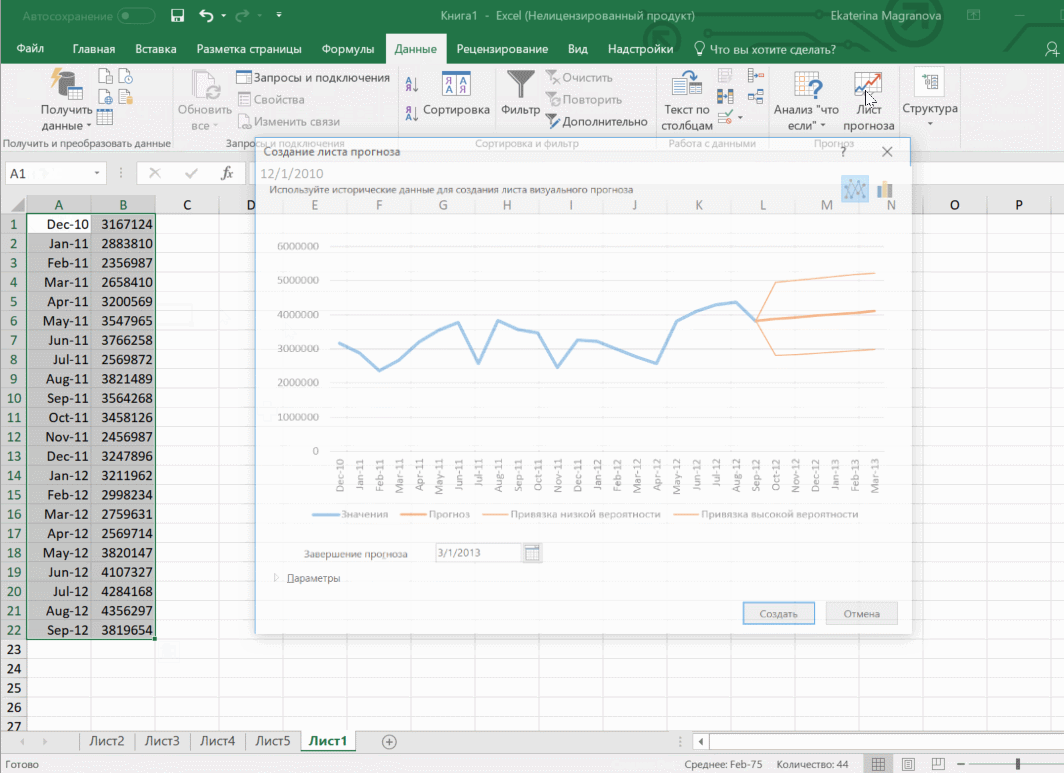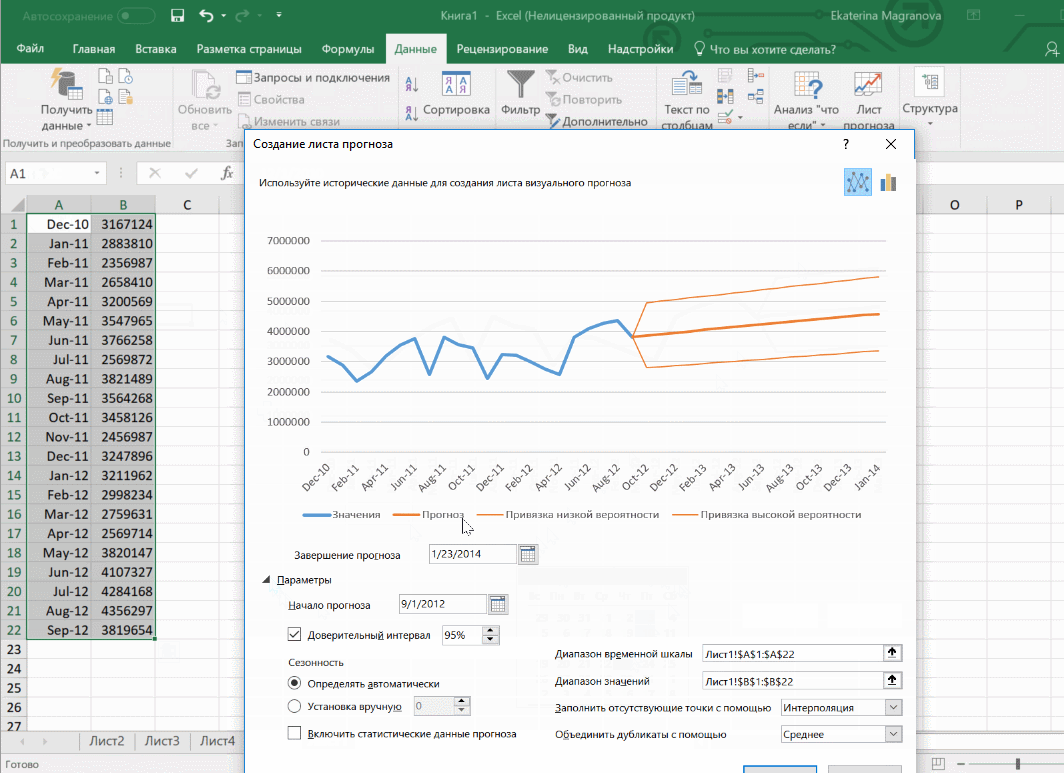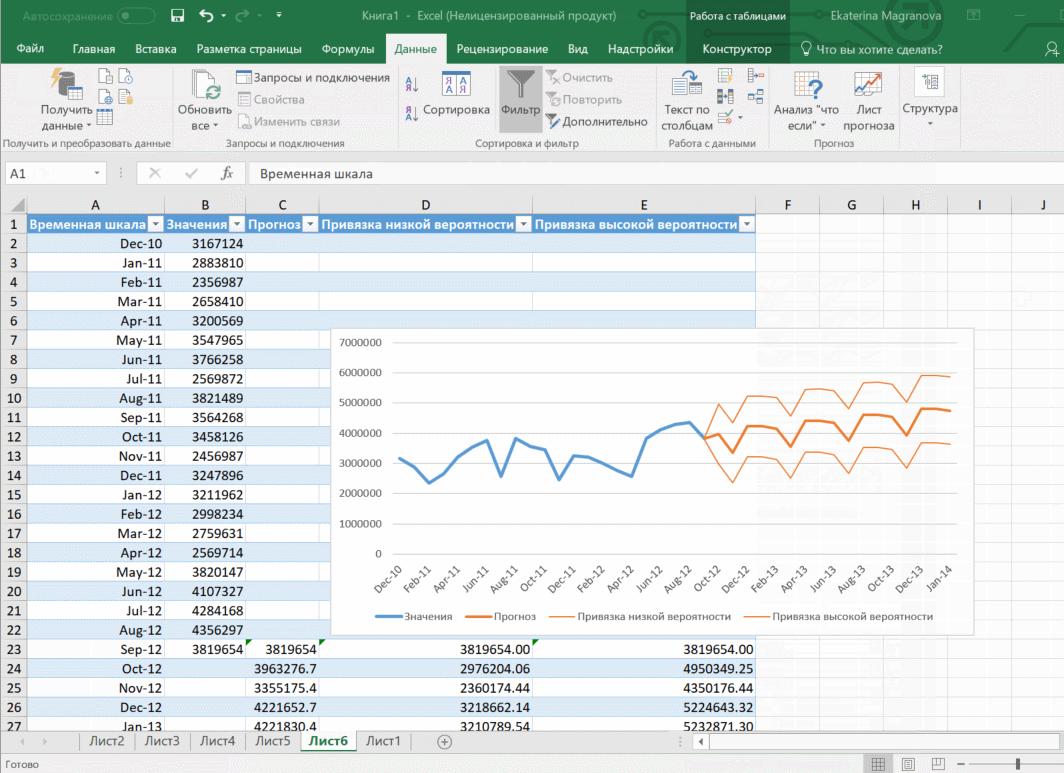
- Перейдите в меню «Данные», и там кликните по кнопке «Лист прогноза».
- После этого откроется диалог, в котором можно выбрать тип визуального представления прогноза: график или гистограмма. Выберите тот, который подходит под вашу ситуацию.
- Установите дату, когда прогноз должен закончиться.
В приводимом нами ниже примере даются сведения за три года – 2011-2013. При этом рекомендуется указывать временные промежутки, а не конкретные числа. То есть, лучше писать март 2013, а не конкретное число типа 7 марта 2013 года. Чтобы исходя из этих данных получить прогноз на 2014 год необходимо получить данных, расположенные в рядах с датой и показателями, которые были на этот момент. Выделяем эти строки.
Затем переходим на вкладку «Данные» и ищем группу «Прогноз». После этого переходим в меню «Лист прогноза». После этого появится окно, в котором снова выбираем способ представления прогноза, а затем устанавливаем дату, к которой прогноз должен быть закончен. После этого нажимаем на «Создать», после чего получаем три варианта прогноза (показываются оранжевой линией).
Быстрый анализ в Excel
Предыдущий способ действительно хорош, потому что позволяет составлять реальные прогнозы, основываясь на статистических показателях. Но этот метод позволяет фактически проводить полноценную бизнес-аналитику. Очень классно, что эта возможность создана максимально эргономичной, поскольку для достижения желаемого результата необходимо совершить буквально несколько действий. Никаких ручных подсчетов, записи каких-либо формул. Достаточно просто выбрать диапазон, который будет анализироваться и задать конечную цель.
Есть возможность прямо в ячейке создавать самые разные диаграммы и микрографики.
Как работать
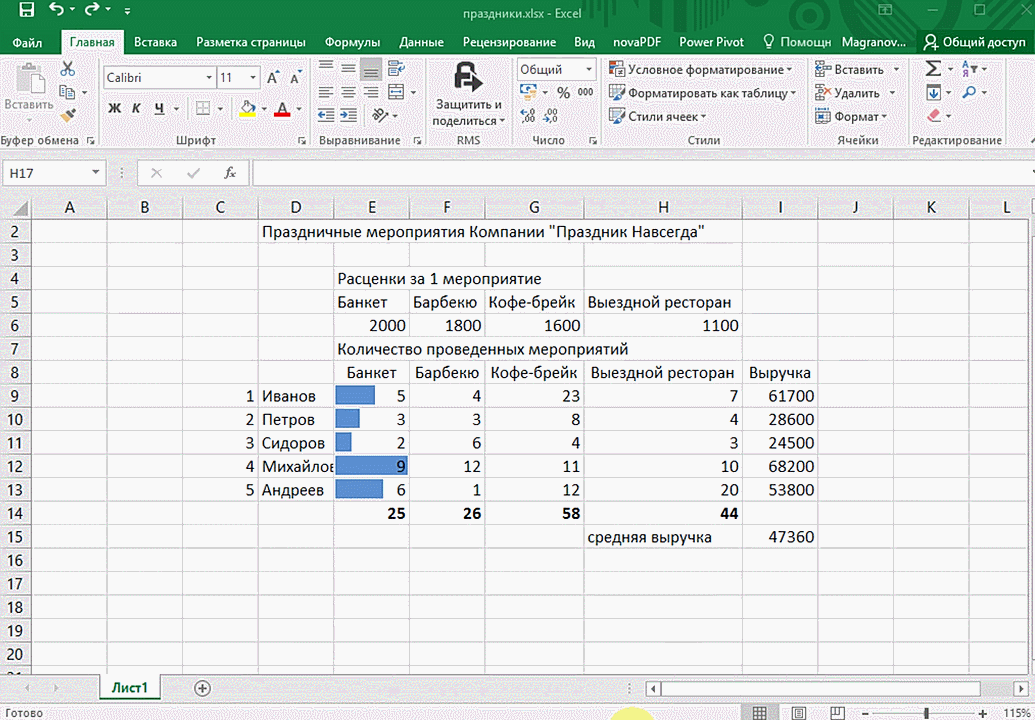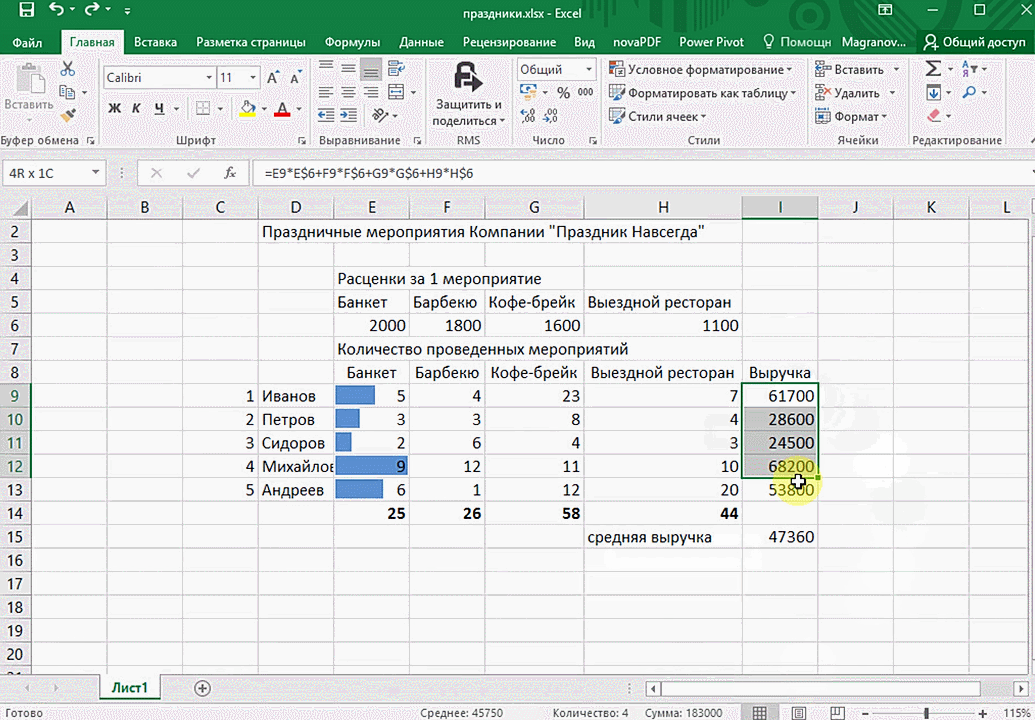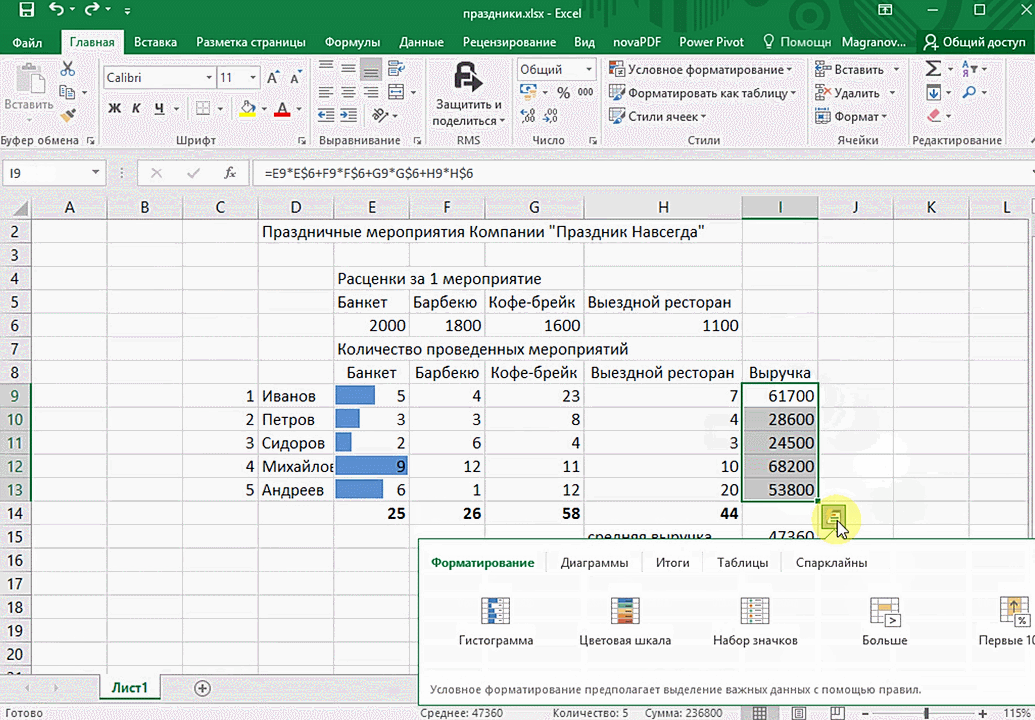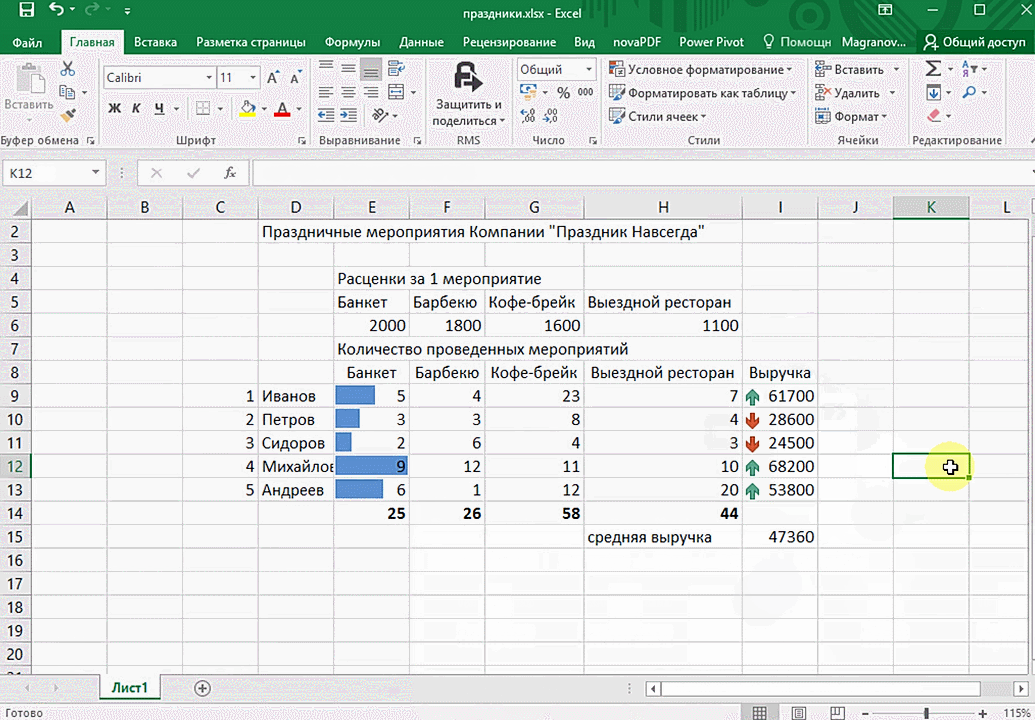
Итак, чтобы работать, нам надо надо открыть файл, в котором содержится тот набор данных, который надо анализировать и выделить соответствующий диапазон. После того, как мы его выделим, у нас автоматически появится кнопка, дающая возможность составить итоги или же выполнить набор других действий. Называется она быстрым анализом. Также мы можем определить суммы, которые автоматически будут проставлены внизу. Более наглядно посмотреть, как это работает, можете на этой анимации.
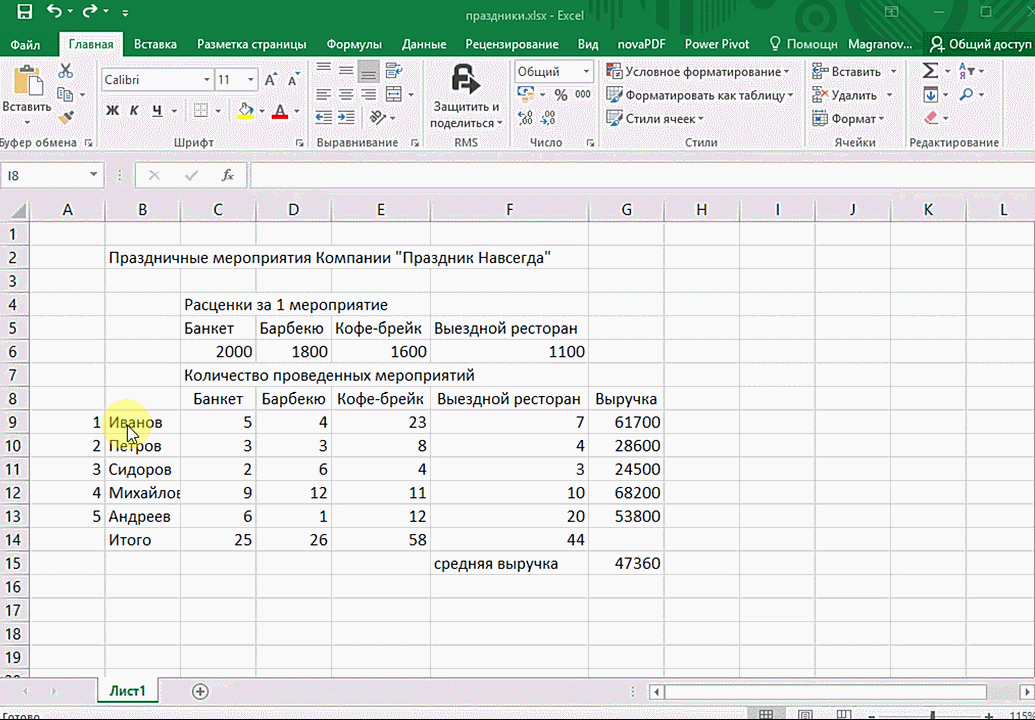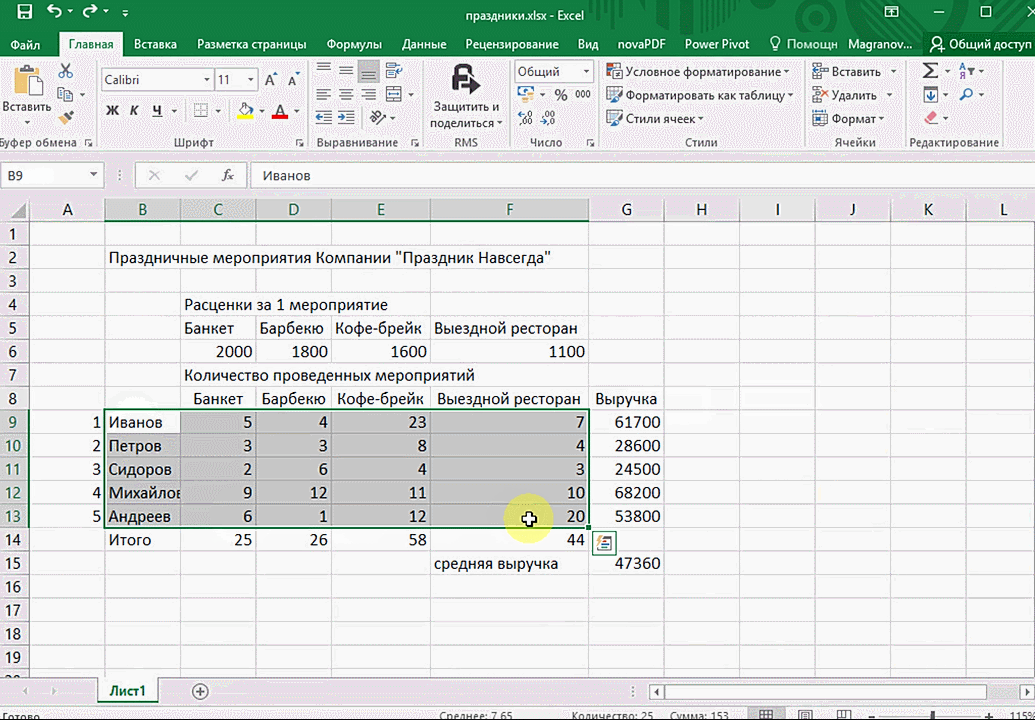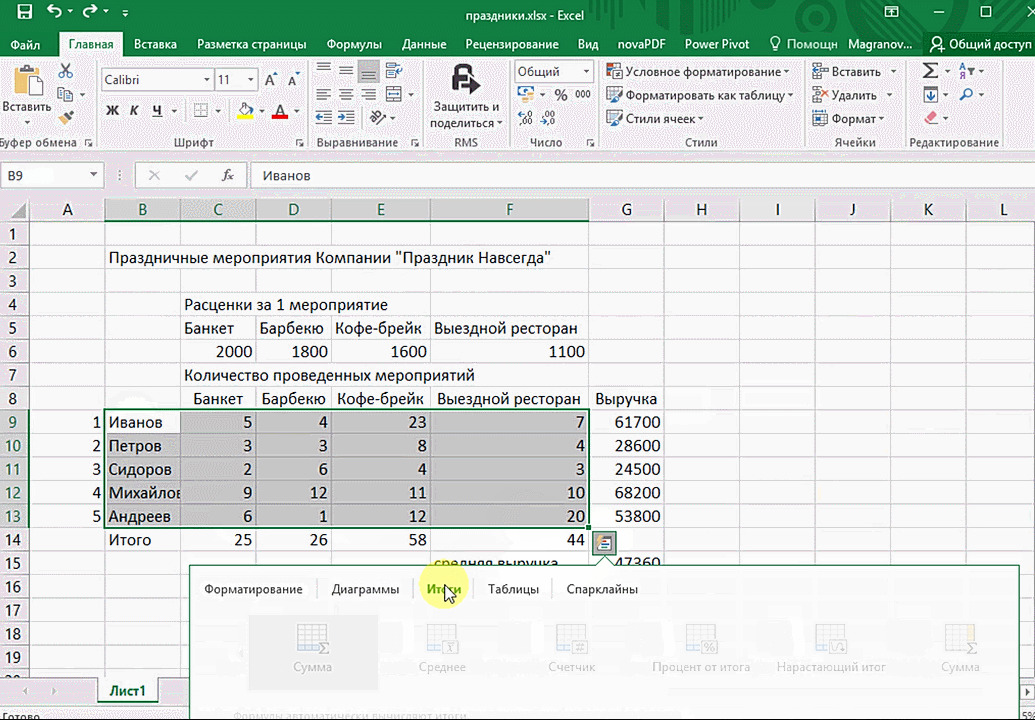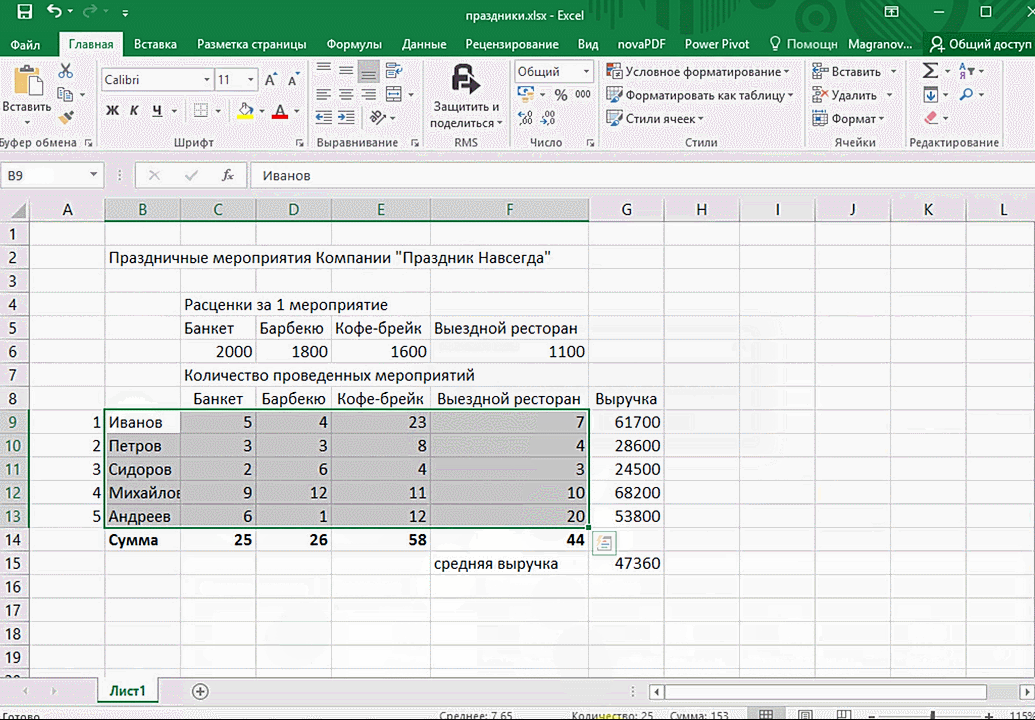
Функция быстрого анализа позволяет также по-разному форматировать получившиеся данные. А определить, какие значения больше или меньше, можно непосредственно в ячейках гистограммы, которая появляется после того, как мы настроим этот инструмент. 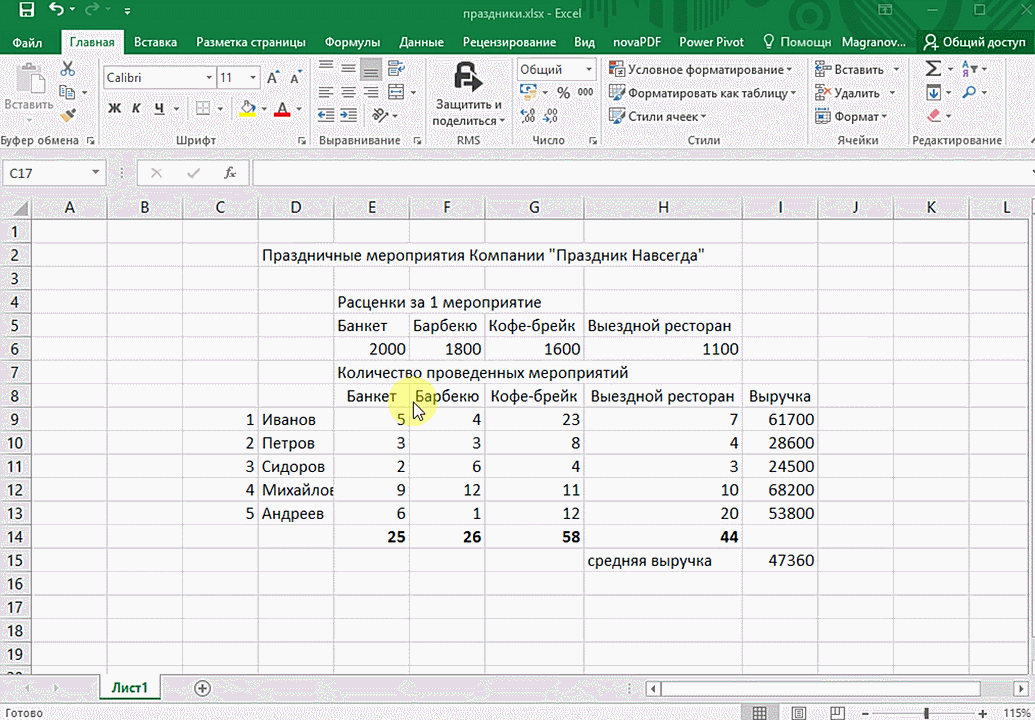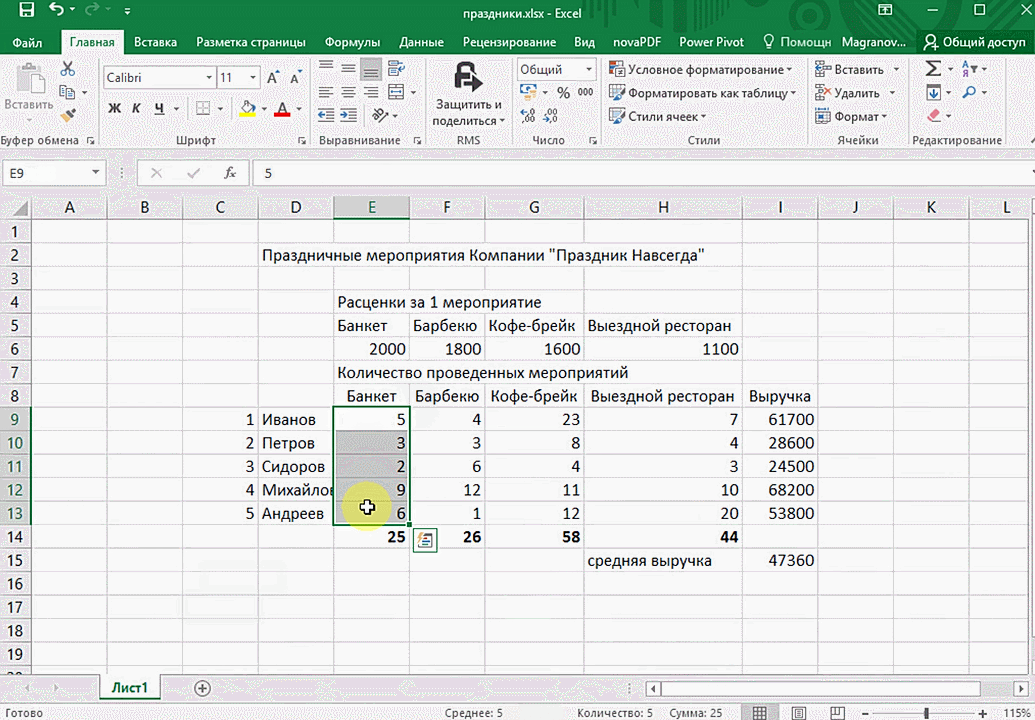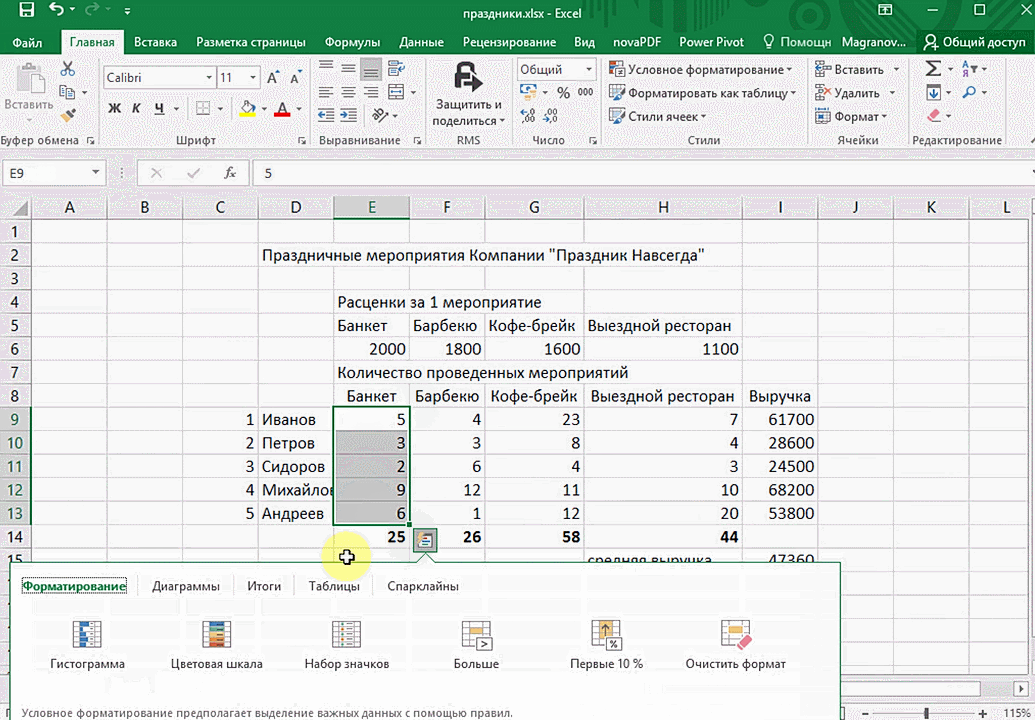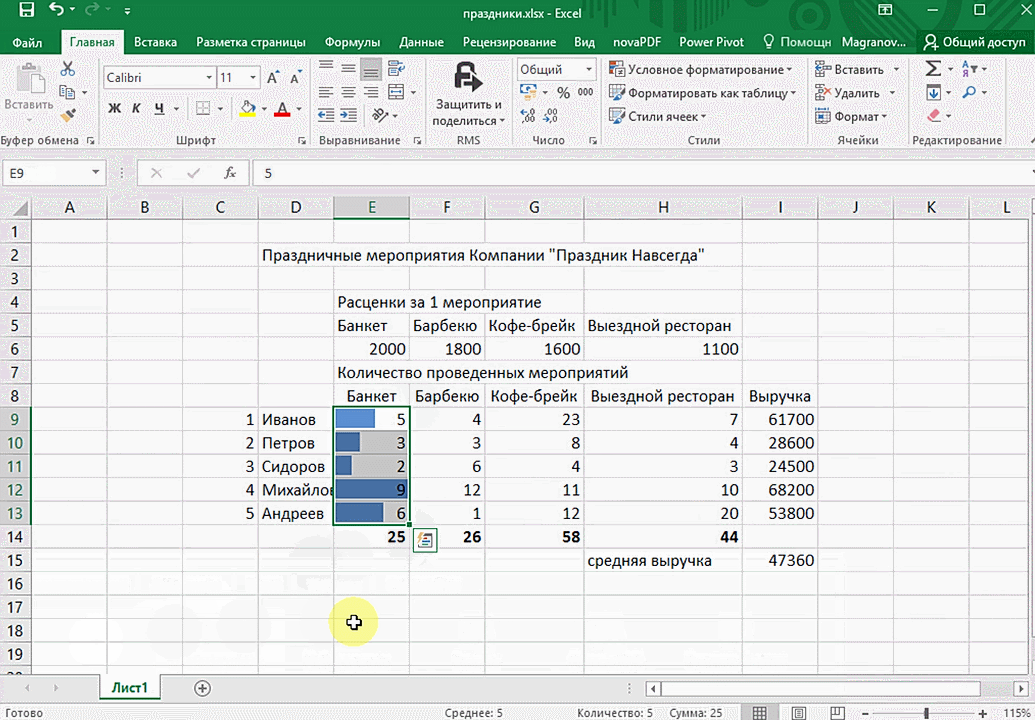
Также пользователь может поставить самые разные маркеры, которые обозначают большие и меньшие значения относительно тех, которые есть в выборке. Так, зеленым цветом будут показываться самые большие значения, а красным – наиболее маленькие.
Очень хочется верить, что эти приемы позволят вам значительно повысить эффективность вашей работы с электронными таблицами и максимально быстро добиться всего, что вы желаете. Как видим, эта программа для работы с электронными таблицами дает очень широкие возможности даже в стандартном функционале. А что уже говорить про дополнения, которых очень много на просторах интернета. Важно только обратить внимание, что все аддоны должны быть тщательно проверены на вирусы, потому что модули, написанные другими людьми, могут содержать вредоносный код. Если же надстройки разработаны компанией Майкрософт, то ее можно использовать смело.
Пакет анализа от Майкрософт – очень функциональная надстройка, которая делает пользователя настоящим профессионалом. Она позволяет выполнить почти любую обработку количественных данных, но она довольно сложная для начинающего пользователя. На официальном сайте справки Майкрософт есть детальная инструкция по тому, как использовать разные виды анализа с помощью этого пакета.
Оцените качество статьи. Нам важно ваше мнение:
Excel для Microsoft 365 Excel для Интернета Excel 2021 Excel 2019 Excel 2016 Excel 2013 Excel 2010 Excel 2007 Еще…Меньше
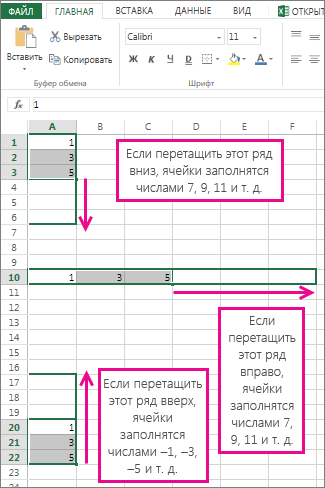
Если вам нужно спрогнозировать расходы на следующий год или проецировать ожидаемые результаты для ряда в научном эксперименте, вы можете использовать Microsoft Office Excel для автоматического создания будущих значений, основанных на существующих данных, или для автоматического получения экстраполированных значений, основанных на вычислениях линейного тренда или тренда роста.
Вы можете заполнить ряд значений, которые соответствуют простому линейному или экспоненциальному тренду роста, с помощью маркер заполнения или последовательности. Для расширения сложных и нелинейных данных можно использовать функции или регрессионный анализ в надстройке «Надстройка «Надстройка анализа».
В линейном ряду шаг или разница между первым и следующим значением добавляется к начальному значению, а затем добавляется к каждому последующему значению.
|
Начальное значение |
Расширенный линейный ряд |
|---|---|
|
1, 2 |
3, 4, 5 |
|
1, 3 |
5, 7, 9 |
|
100, 95 |
90, 85 |
Чтобы заполнить ряд для линейного тренда, сделайте следующее:
-
Выделите не менее двух ячеек, содержащих начальные значения для тренда.
Чтобы повысить точность ряда трендов, выберите дополнительные начальные значения.
-
Перетащите его в нужном направлении.
Например, если в ячейках C1:E1 выбраны начальные значения 3, 5 и 8, перетащите его вправо, чтобы заполнить значениями тенденций, или перетащите его влево, чтобы заполнить значениями убывания.
Совет: Чтобы вручную управлять тем, как создается ряд, или заполнить ряд с помощью клавиатуры, выберите команду Ряд(вкладкаГлавная, группа Редактирование, кнопка Заполнить).
В рядах роста начальное значение умножается на шаг, чтобы получить следующее значение в ряду. Результат и каждый последующий результат умножаются на шаг.
|
Начальное значение |
Расширенный ряд роста |
|---|---|
|
1, 2 |
4, 8, 16 |
|
1, 3 |
9, 27, 81 |
|
2, 3 |
4.5, 6.75, 10.125 |
Чтобы заполнить ряд для тенденции роста, сделайте следующее:
-
Выделите не менее двух ячеек, содержащих начальные значения для тренда.
Чтобы повысить точность ряда трендов, выберите дополнительные начальные значения.
-
Удерживая нажатой правую кнопку мыши, перетащите указатель заполнения в нужном направлении, отпустите кнопку мыши, а затем на ленте нажмите кнопку контекстное меню.
Например, если в ячейках C1:E1 выбраны начальные значения 3, 5 и 8, перетащите его вправо, чтобы заполнить значениями тенденций, или перетащите его влево, чтобы заполнить значениями убывания.
Совет: Чтобы вручную управлять тем, как создается ряд, или заполнить ряд с помощью клавиатуры, выберите команду Ряд(вкладкаГлавная, группа Редактирование, кнопка Заполнить).
При нажатии кнопки Ряд можно вручную управлять тем, как создается линейный тренд или тенденция роста, а затем заполнять значения с помощью клавиатуры.
-
В линейном ряду начальные значения применяются к алгоритму наименьших квадратов (y=mx+b), который создает ряд.
-
В рядах роста начальные значения применяются к алгоритму экспоненциальной кривой (y=b*m^x), который создает ряд.
В обоих случаях шаг игнорируется. Созданный ряд эквивалентен значениям, возвращенным функцией ТЕНДЕНЦИЯ или функцией РОСТ.
Чтобы заполнить значения вручную, сделайте следующее:
-
Вы выберите ячейку, в которой нужно начать ряд. Ячейка должна содержать первое значение ряда.
При выборе команды Ряд итоговые ряды заменяют исходные выбранные значения. Если вы хотите сохранить исходные значения, скопируйте их в другую строку или столбец, а затем создайте ряд, выбирая скопированные значения.
-
На вкладке Главная в группе Редактирование нажмите кнопку Заполнить и выберите пункт Прогрессия.
-
Выполните одно из указанных ниже действий.
-
Чтобы заполнить ряд вниз по worksheet, щелкните Столбцы.
-
Чтобы заполнить ряд по всему ряду, щелкните Строки.
-
-
В поле Шаг введите значение, на которое вы хотите увеличить ряд.
|
Тип ряда |
Результат шага |
|---|---|
|
Линейная |
Значение шага добавляется к первому начальному значению, а затем к каждому последующему значению. |
|
Геометрическая |
Первое начальное значение умножается на шаг. Результат и каждый последующий результат умножаются на шаг. |
-
В области Типвыберите линейный или Рост.
-
В поле Остановить значение введите значение, на которое нужно остановить ряд.
Примечание: Если ряд имеет несколько начальных значений и Excel создать тенденцию, выберите значение Тренд.
Если у вас есть данные, для которых вы хотите спрогнозировать тенденцию, можно создать линия тренда на диаграмме. Например, если в Excel есть диаграмма с данными о продажах за первые несколько месяцев года, вы можете добавить на нее линию тренда, которая отображает общий тренд продаж (увеличение или уменьшение или снижение), а также прогнозируемый тренд на месяцы вперед.
Предполагается, что вы уже создали диаграмму, основанную на существующих данных. Если это не так, см. раздел Создание диаграммы.
-
Щелкните диаграмму.
-
Щелкните ряд данных, в который вы хотите добавить линия тренда или скользящее среднее.
-
На вкладке Макет в группе Анализ нажмите кнопку Линия тренда ивыберите нужный тип линии тренда или скользящего среднего.
-
Чтобы настроить параметры и отформатирование линии тренда или скользящего среднего, щелкните линию тренда правой кнопкой мыши и выберите в меню пункт Формат линии тренда.
-
Выберите нужные параметры линии тренда, линии и эффекты.
-
При выборе параметра Полиномиальная, введите в поле Порядок наивысшую мощность для независимой переменной.
-
Если выбрано значение Скользящегосреднего , введите в поле Период количество периодов, используемых для расчета лино-среднего.
-
Примечания:
-
В поле На основе ряда перечислены все ряды данных на диаграмме, которые поддерживают линии тренда. Чтобы добавить линию тренда к другому ряду, щелкните имя в поле и выберите нужные параметры.
-
При добавлении скользящего среднего на точечная диаграмма скользящие средние значения основаны на порядке, за исключением значений X, относящегося к диаграмме. Чтобы получить нужный результат, перед добавлением скользящего среднего может потребоваться отсортировать значения x.
Важно: Начиная с Excel 2005 г., Excel способ вычисления значенияR2 для линейных линий тренда на диаграммах, где для перехваченной линии тренда установлено значение нуля (0). Эта корректировка исправит вычисления, которые дают неправильные значения R2,и выровняет вычислениеR2 с функцией LINEST. В результате на диаграммах, созданных в предыдущих версиях Excel, могут отображаться разные значения R2. Дополнительные сведения см. в таблице Изменения внутренних вычислений линейных линий тренда на диаграмме.
Если вам нужно выполнить более сложный регрессионный анализ, в том числе вычислить и отсчитывать остаточные данные, используйте средство регрессионного анализа в надстройке «Надстройка «Надстройка анализа». Дополнительные сведения см. в окне Загрузка средства анализа.
В Excel в Интернете, вы можете проецировать значения в ряду с помощью функций или щелкнуть и перетащить его, чтобы создать линейный тренд чисел. Однако создать тенденцию роста с помощью ручки заполнения нельзя.
Вот как можно использовать его для создания линейного тренда чисел в Excel в Интернете:
-
Выделите не менее двух ячеек, содержащих начальные значения для тренда.
Чтобы повысить точность ряда трендов, выберите дополнительные начальные значения.
-
Перетащите его в нужном направлении.

Использование функции ПРОГНОЗ Функция ПРЕДСПРОС вычисляет или предсказывает будущее значение с использованием существующих значений. Предсказываемое значение — это значение y, соответствующее заданному значению x. Значения x и y известны; новое значение предсказывается с использованием линейной регрессии. Эта функция используется для предсказания будущих продаж, требований к запасам и потребительских тенденций.
Использование функции ТЕНДЕНЦИЯ или ФУНКЦИИ РОСТ Функции ТЕНДЕНЦИЯ и РОСТ могут выполнять экстраполяцию будущих значений y,которые расширяют прямую или экспоненциальный кривую, наилучшим образом описывающую существующие данные. Они также могут возвращать только значения yна основе известных значений x-длянаиболее подходящих строк или кривой. Для отстройки линии или кривой, описывающую существующие данные, используйте существующие значения x-value и y-value,возвращаемые функцией ТЕНДЕНЦИЯ или РОСТ.
Использование функции ЛИНИИСТОЛ или ФУНКЦИИ ЛОГЕСТ Функцию ЛИННЕФ или LOGEST можно использовать для вычисления прямой или экспоненциальной кривой из существующих данных. Функции LINEST и LOGEST возвращают различные статистические данные о регрессии, включая наклон и отступ линии, которая лучше всего подходит.
В следующей таблице содержатся ссылки на дополнительные сведения об этих функциях.
|
Функция |
Описание |
|---|---|
|
Прогноз |
Project значения |
|
Тенденция |
Project значения, которые соответствуют прямой линии тренда |
|
Роста |
Project, которые соответствуют экспоненциальной кривой |
|
Линейн |
Расчет прямой линии из существующих данных |
|
LOGEST |
Расчет экспоненциальной кривой из существующих данных |
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
Нужна дополнительная помощь?
Предположим, у вас есть длинный список порядковых номеров для маркировки элементов, таких как номера чеков в выписках по счету, обычно мы прокручиваем и находим недостающие порядковые номера вручную. Иногда это довольно сложно и требует много времени. Вы можете придумать хитрые способы справиться с этим. Да, есть несколько простых способов быстро и удобно определить и найти последовательность отсутствующих чисел в Excel 2007, Excel 2010 и Excel 2013.
Определите последовательность отсутствующих чисел с помощью формулы ЕСЛИ
Определить последовательность отсутствующих чисел с помощью формулы массива
Определить последовательность отсутствующих чисел с помощью Kutools for Быстро Excel
Найдите и выделите отсутствующие числа в последовательности:
Kutools for Excel Функция «Найти отсутствующий порядковый номер может помочь вам быстро и легко найти недостающую последовательность и вставить недостающие числа или пустые строки в существующую последовательность данных или заполнить цвет фона при обнаружении отсутствующей последовательности.

Kutools for Excel : с более чем 200 удобными надстройками Excel, можно бесплатно попробовать без ограничений в течение 60 дней. Скачать и бесплатную пробную версию прямо сейчас!
->
Содержание
- Определите последовательность пропущенных чисел с помощью формулы ЕСЛИ
- С помощью формула массива
- Быстрое определение последовательности отсутствующих чисел с помощью Kutools for Excel
- Быстрое определение последовательности отсутствующих чисел с помощью Kutools for Excel
Определите последовательность пропущенных чисел с помощью формулы ЕСЛИ
 Определите последовательность пропущенных чисел с помощью формулы ЕСЛИ
Определите последовательность пропущенных чисел с помощью формулы ЕСЛИ Как мы все знаем, большинство порядковых номеров имеют фиксированное приращение из 1, например 1, 2, 3,…, N. Следовательно, если вы можете определить, что число не меньше 1, чем следующее за ним число, это означает отсутствие числа.
Мы покажем вам представлены учебные пособия с примером, показанным на следующем снимке экрана:

1. В пустой ячейке введите формулу = IF (A3-A2 = 1, “”, “Отсутствует”) и нажмите клавишу Enter . В этом случае мы вводим формулу в ячейку B2.

Если нет пропущенных чисел, эта формула ничего не вернет; если пропущенные числа существуют, он вернет текст «Отсутствует» в активной ячейке.
2. Выделите ячейку B2 и перетащите маркер заполнения над диапазоном ячеек, который вы хотите содержать эту формулу. Теперь он идентифицирует отсутствующие числа с текстом «Отсутствует» в соответствующих ячейках столбца B. См. Следующий снимок экрана:

С помощью формула массива
Иногда требуется не только определить последовательность пропущенных чисел, но и перечислить отсутствующие числа. Вы можете справиться с этим, выполнив следующие шаги:
1. в соседней ячейке введите формулу = SMALL (IF (ISNA (MATCH (ROW (A $ 1: A $ 30), A $ 1: A $ 30,0)), ROW (A $ 1: A $ 30) ), СТРОКА (A1))
A1: A30 = диапазон чисел, последовательность для проверки против – от 1 до 30
2. Одновременно нажмите клавиши Ctrl + Shift + Enter , чтобы завершить формулу. Скопируйте формулу, пока не получите # ЧИСЛО! ошибки, означающие, что были перечислены все отсутствующие числа. См. Снимок экрана:

Быстрое определение последовательности отсутствующих чисел с помощью Kutools for Excel
Только указанные выше методы могут Определите отсутствующую чистую числовую последовательность, если у вас есть такая последовательность, как AA-1001-BB, AA-1002-BB, они могут не работать успешно. Но не волнуйтесь, мощная функция Kutools for Excel – Найти отсутствующий порядковый номер может помочь вам быстро определить недостающую последовательность.
Примечание. Чтобы применить этот Найти отсутствующий порядковый номер , во-первых, вы должны загрузить Kutools для Excel , а затем быстро и легко примените эту функцию.
После установки Kutools for Excel сделайте следующее:
1. Выберите последовательность данных, в которой вы хотите найти недостающую последовательность.
2. Нажмите Kutools > Вставить > Найти отсутствующий порядковый номер , см. Снимок экрана:

3. В диалоговом окне Найти отсутствующий порядковый номер :
(1.) Если вы выбрали Вставить новый столбец со следующим отсутствующим маркером вариант, все отсутствующие порядковые номера были отмечены текстом Missing в новом столбце рядом с вашими данными. См. Снимок экрана:
(2.) Если вы выберете Вставка отсутствующего порядкового номера , все недостающие номера были вставлены в список последовательностей. См. Снимок экрана:

(3.) Если вы выберете Вставка пустых строк при включении отсутствующих порядковых номеров , все пустые строки вставляются, если отсутствуют номера. См. Снимок экрана:

(4.) Если вы выберете Заполнить цвет фона , расположение недостающих чисел будет выделено сразу. См. Снимок экрана:

Быстрое определение последовательности отсутствующих чисел с помощью Kutools for Excel
Kutools for Excel : с более чем 300 удобными надстройками Excel, попробуйте бесплатно без ограничений в течение 30 дней. Загрузите и бесплатную пробную версию прямо сейчас!
Содержание
- Использование описательной статистики
- Подключение «Пакета анализа»
- Размах вариации
- Вычисление коэффициента вариации
- Шаг 1: расчет стандартного отклонения
- Шаг 2: расчет среднего арифметического
- Шаг 3: нахождение коэффициента вариации
- Простая формула для расчета объема выборки
- Пример расчета объема выборки
- Задачи о генеральной доле
- По части судить о целом
- Как рассчитать объем выборки
- Как определить статистические выбросы и сделать выборку для их удаления в Excel
- Способ 1: применение расширенного автофильтра
- Способ 2: применение формулы массива
- СРЗНАЧ()
- СРЗНАЧЕСЛИ()
- МАКС()
- МИН()
Использование описательной статистики
Под описательной статистикой понимают систематизацию эмпирических данных по целому ряду основных статистических критериев. Причем на основе полученного результата из этих итоговых показателей можно сформировать общие выводы об изучаемом массиве данных.
В Экселе существует отдельный инструмент, входящий в «Пакет анализа», с помощью которого можно провести данный вид обработки данных. Он так и называется «Описательная статистика». Среди критериев, которые высчитывает данный инструмент следующие показатели:
- Медиана;
- Мода;
- Дисперсия;
- Среднее;
- Стандартное отклонение;
- Стандартная ошибка;
- Асимметричность и др.
Рассмотрим, как работает данный инструмент на примере Excel 2010, хотя данный алгоритм применим также в Excel 2007 и в более поздних версиях данной программы.
Подключение «Пакета анализа»
Как уже было сказано выше, инструмент «Описательная статистика» входит в более широкий набор функций, который принято называть Пакет анализа. Но дело в том, что по умолчанию данная надстройка в Экселе отключена. Поэтому, если вы до сих пор её не включили, то для использования возможностей описательной статистики, придется это сделать.
- Переходим во вкладку «Файл». Далее производим перемещение в пункт «Параметры».
- В активировавшемся окне параметров перемещаемся в подраздел «Надстройки». В самой нижней части окна находится поле «Управление». Нужно в нем переставить переключатель в позицию «Надстройки Excel», если он находится в другом положении. Вслед за этим жмем на кнопку «Перейти…».
- Запускается окно стандартных надстроек Excel. Около наименования «Пакет анализа» ставим флажок. Затем жмем на кнопку «OK».



После вышеуказанных действий надстройка Пакет анализа будет активирована и станет доступной во вкладке «Данные» Эксель. Теперь мы сможем использовать на практике инструменты описательной статистики.
Размах вариации
Размах вариации – разница между максимальным и минимальным значением:
![]()
Ниже приведена графическая интерпретация размаха вариации.

Видно максимальное и минимальное значение, а также расстояние между ними, которое и соответствует размаху вариации.
С одной стороны, показатель размаха может быть вполне информативным и полезным. К примеру, максимальная и минимальная стоимость квартиры в городе N, максимальная и минимальная зарплата по профессии в регионе и проч. С другой стороны, размах может быть очень широким и не иметь практического смысла, т.к. зависит лишь от двух наблюдений. Таким образом, размах вариации очень неустойчивая величина.
Вычисление коэффициента вариации
Этот показатель представляет собой отношение стандартного отклонения к среднему арифметическому. Полученный результат выражается в процентах.
В Экселе не существует отдельно функции для вычисления этого показателя, но имеются формулы для расчета стандартного отклонения и среднего арифметического ряда чисел, а именно они используются для нахождения коэффициента вариации.
Шаг 1: расчет стандартного отклонения
Стандартное отклонение, или, как его называют по-другому, среднеквадратичное отклонение, представляет собой квадратный корень из дисперсии. Для расчета стандартного отклонения используется функция СТАНДОТКЛОН. Начиная с версии Excel 2010 она разделена, в зависимости от того, по генеральной совокупности происходит вычисление или по выборке, на два отдельных варианта: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В.
Синтаксис данных функций выглядит соответствующим образом:
= СТАНДОТКЛОН(Число1;Число2;…)
= СТАНДОТКЛОН.Г(Число1;Число2;…)
= СТАНДОТКЛОН.В(Число1;Число2;…)
- Для того, чтобы рассчитать стандартное отклонение, выделяем любую свободную ячейку на листе, которая удобна вам для того, чтобы выводить в неё результаты расчетов. Щелкаем по кнопке «Вставить функцию». Она имеет внешний вид пиктограммы и расположена слева от строки формул.

Выполняется активация Мастера функций, который запускается в виде отдельного окна с перечнем аргументов. Переходим в категорию «Статистические» или «Полный алфавитный перечень». Выбираем наименование «СТАНДОТКЛОН.Г» или «СТАНДОТКЛОН.В», в зависимости от того, по генеральной совокупности или по выборке следует произвести расчет. Жмем на кнопку «OK».

Открывается окно аргументов данной функции. Оно может иметь от 1 до 255 полей, в которых могут содержаться, как конкретные числа, так и ссылки на ячейки или диапазоны. Ставим курсор в поле «Число1». Мышью выделяем на листе тот диапазон значений, который нужно обработать. Если таких областей несколько и они не смежные между собой, то координаты следующей указываем в поле «Число2» и т.д. Когда все нужные данные введены, жмем на кнопку «OK»


Шаг 2: расчет среднего арифметического
Среднее арифметическое является отношением общей суммы всех значений числового ряда к их количеству. Для расчета этого показателя тоже существует отдельная функция – СРЗНАЧ. Вычислим её значение на конкретном примере.
- Выделяем на листе ячейку для вывода результата. Жмем на уже знакомую нам кнопку «Вставить функцию».

В статистической категории Мастера функций ищем наименование «СРЗНАЧ». После его выделения жмем на кнопку «OK».

Запускается окно аргументов СРЗНАЧ. Аргументы полностью идентичны тем, что и у операторов группы СТАНДОТКЛОН. То есть, в их качестве могут выступать как отдельные числовые величины, так и ссылки. Устанавливаем курсор в поле «Число1». Так же, как и в предыдущем случае, выделяем на листе нужную нам совокупность ячеек. После того, как их координаты были занесены в поле окна аргументов, жмем на кнопку «OK».


Шаг 3: нахождение коэффициента вариации
Теперь у нас имеются все необходимые данные для того, чтобы непосредственно рассчитать сам коэффициент вариации.
- Выделяем ячейку, в которую будет выводиться результат. Прежде всего, нужно учесть, что коэффициент вариации является процентным значением. В связи с этим следует поменять формат ячейки на соответствующий. Это можно сделать после её выделения, находясь во вкладке «Главная». Кликаем по полю формата на ленте в блоке инструментов «Число». Из раскрывшегося списка вариантов выбираем «Процентный». После этих действий формат у элемента будет соответствующий.

Снова возвращаемся к ячейке для вывода результата. Активируем её двойным щелчком левой кнопки мыши. Ставим в ней знак «=». Выделяем элемент, в котором расположен итог вычисления стандартного отклонения. Кликаем по кнопке «разделить» (/) на клавиатуре. Далее выделяем ячейку, в которой располагается среднее арифметическое заданного числового ряда. Для того, чтобы произвести расчет и вывести значение, щёлкаем по кнопке Enter на клавиатуре.


Таким образом мы произвели вычисление коэффициента вариации, ссылаясь на ячейки, в которых уже были рассчитаны стандартное отклонение и среднее арифметическое. Но можно поступить и несколько по-иному, не рассчитывая отдельно данные значения.
- Выделяем предварительно отформатированную под процентный формат ячейку, в которой будет выведен результат. Прописываем в ней формулу по типу:
Вместо наименования «Диапазон значений» вставляем реальные координаты области, в которой размещен исследуемый числовой ряд. Это можно сделать простым выделением данного диапазона. Вместо оператора СТАНДОТКЛОН.В, если пользователь считает нужным, можно применять функцию СТАНДОТКЛОН.Г.


Существует условное разграничение. Считается, что если показатель коэффициента вариации менее 33%, то совокупность чисел однородная. В обратном случае её принято характеризовать, как неоднородную.
Как видим, программа Эксель позволяет значительно упростить расчет такого сложного статистического вычисления, как поиск коэффициента вариации. К сожалению, в приложении пока не существует функции, которая высчитывала бы этот показатель в одно действие, но при помощи операторов СТАНДОТКЛОН и СРЗНАЧ эта задача очень упрощается. Таким образом, в Excel её может выполнить даже человек, который не имеет высокого уровня знаний связанных со статистическими закономерностями.
Разделы: Математика
- Совершенствование умений и навыков нахождения статистических характеристик случайной величины, работа с расчетами в Excel;
- применение информационно коммутативных технологий для анализа данных; работа с различными информационными носителями.
- Сегодня мы научимся рассчитывать статистические характеристики для больших по объему выборок, используя возможности современных компьютерных технологий.
- Для начала вспомним:
– что называется случайной величиной? (Случайной величиной называют переменную величину, которая в зависимости от исхода испытания принимает одно значение из множества возможных значений.)
– Какие виды случайных величин мы знаем? (Дискретные, непрерывные.)
– Приведите примеры непрерывных случайных величин (рост дерева), дискретных случайных величин (количество учеников в классе).
– Какие статистические характеристики случайных величин мы знаем (мода, медиана, среднее выборочное значение, размах ряда).
– Какие приемы используются для наглядного представления статистических характеристик случайной величины (полигон частот, круговые и столбчатые диаграммы, гистограммы).
- Рассмотрим, применение инструментов Excel для решения статистических задач на конкретном примере.
Пример. Проведена проверка в 100 компаниях. Даны значения количества работающих в компании (чел.):
| 23 25 24 25 30 24 30 26 28 26 32 33 31 31 25 33 25 29 30 28 23 30 29 24 33 30 30 28 26 25 26 29 27 29 26 28 27 26 29 28 29 30 27 30 28 32 28 26 30 26 31 27 30 27 33 28 26 30 31 29 27 30 30 29 27 26 28 31 29 28 33 27 30 33 26 31 34 28 32 22 29 30 27 29 34 29 32 29 29 30 29 29 36 29 29 34 23 28 24 28 |
рассчитать числовые характеристики:
|
1. Занести данные в EXCEL, каждое число в отдельную ячейку.
| 23 | 25 | 24 | 25 | 30 | 24 | 30 | 26 | 28 | 26 |
| 32 | 33 | 31 | 31 | 25 | 33 | 25 | 29 | 30 | 28 |
| 23 | 30 | 29 | 24 | 33 | 30 | 30 | 28 | 26 | 25 |
| 26 | 29 | 27 | 29 | 26 | 28 | 27 | 26 | 29 | 28 |
| 29 | 30 | 27 | 30 | 28 | 32 | 28 | 26 | 30 | 26 |
| 31 | 27 | 30 | 27 | 33 | 28 | 26 | 30 | 31 | 29 |
| 27 | 30 | 30 | 29 | 27 | 26 | 28 | 31 | 29 | 28 |
| 33 | 27 | 30 | 33 | 26 | 31 | 34 | 28 | 32 | 22 |
| 29 | 30 | 27 | 29 | 34 | 29 | 32 | 29 | 29 | 30 |
| 29 | 29 | 36 | 29 | 29 | 34 | 23 | 28 | 24 | 28 |
2. Для расчета числовых характеристик используем опцию Вставка – Функция. И в появившемся окне в строке категория выберем – статистические, в списке: МОДА

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Мо = 29 (чел) – Фирм у которых в штате 29 человек больше всего.
Используя тот же путь вычисляем медиану.
Вставка – Функция – Статистические – Медиана.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили Ме = 29 (чел) – среднее значение сотрудников в фирме.
Размах ряда чисел – разница между наименьшим и наибольшим возможным значением случайной величины. Для вычисления размаха ряда нужно найти наибольшее и наименьшее значения нашей выборки и вычислить их разность.
Вставка – Функция – Статистические – МАКС.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наибольшее значение = 36.
Вставка – Функция – Статистические – МИН.

В поле Число 1 ставим курсор и мышкой выделяем нашу таблицу:

Нажимаем клавишу ОК. Получили наименьшее значение = 22.
36 – 22 = 14 (чел) – разница между фирмой с наибольшим штатом сотрудников и фирмой с наименьшим штатом сотрудников.
Для построения диаграммы и полигона частот необходимо задать закон распределения, т.е. составить таблицу значений случайной величины и соответствующих им частот. Мы ухе знаем, что наименьшее число сотрудников в фирме = 22, а наибольшее = 36. Составим таблицу, в которой значения xi случайной величины меняются от 22 до 36 включительно шагом 1.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni |
Чтобы сосчитать частоту каждого значения воспользуемся
Вставка – Функция – Статистические – СЧЕТЕСЛИ.
В окне Диапазон ставим курсор и выделяем нашу выборку, а в окне Критерий ставим число 22

Нажимаем клавишу ОК, получаем значение 1, т.е. число 22 в нашей выборке встречается 1 раз и его частота =1. Аналогичным образом заполняем всю таблицу.
| xi | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| ni | 1 | 3 | 4 | 5 | 11 | 9 | 13 | 18 | 16 | 6 | 4 | 6 | 3 | 0 | 1 |
Для проверки вычисляем объем выборки, сумму частот (Вставка – Функция – Математические – СУММА). Должно получиться 100 (количество всех фирм).
Чтобы построить полигон частот выделяем таблицу – Вставка – Диаграмма – Стандартные – Точечная (точечная диаграмма на которой значения соединены отрезками)

Нажимаем клавишу Далее, в Мастере диаграмм указываем название диаграммы (Полигон частот), удаляем легенду, редактируем шкалу и характеристики диаграммы для наибольшей наглядности.


Для построения столбчатой и круговой диаграмм используем тот же путь (выбирая нужный нам тип диаграммы).
Диаграмма – Стандартные – Круговая.

Диаграмма – Стандартные – Гистограмма.

4. Сегодня на уроке мы научились применять компьютерные технологии для анализа и обработки статистической информации.
Простая формула для расчета объема выборки

где: n – объем выборки;
z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности. Этот показатель характеризует возможность, вероятность попадания ответов в специальный – доверительный интервал. На практике уровень доверительности часто принимают за 95% или 99%. Тогда значения z будут соответственно 1,96 и 2,58;
p – вариация для выборки, в долях. По сути, p – это вероятность того, что респонденты выберут той или иной вариант ответа. Допустим, если мы считаем, что четверть опрашиваемых выберут ответ «Да», то p будет равно 25%, то есть p = 0,25;
q = (1 – p);
e – допустимая ошибка, в долях.
Пример расчета объема выборки
Компания планирует провести социологическое исследование с целью выявить долю курящих лиц в населении города. Для этого сотрудники компании будут задавать прохожим один вопрос: «Вы курите?». Возможных вариантов ответа, таким образом, только два: «Да» и «Нет».
Объем выборки в этом случае рассчитывается следующим образом. Уровень доверительности принимается за 95%, тогда нормированное отклонение z = 1,96. Вариацию принимаем за 50%, то есть условно считаем, что половина респондентов может ответить на вопрос о том, курят ли они – «Да». Тогда p = 0,5. Отсюда находим q = 1 – p = 1 – 0,5 = 0,5. Допустимую ошибку выборки принимаем за 10%, то есть e = 0,1.
Подставляем эти данные в формулу и считаем:

Получаем объем выборки n = 96 человек.
Задачи о генеральной доле
На вопрос «Накрывает ли доверительный интервал заданное значение p0?» — можно ответить, проверив статистическую гипотезу H0:p=p0. При этом предполагается, что опыты проводятся по схеме испытаний Бернулли (независимы, вероятность p появления события А постоянна). По выборке объема n определяют относительную частоту p* появления события A:![]() где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
где m — количество появлений события А в серии из n испытаний. Для проверки гипотезы H0 используется статистика, имеющая при достаточно большом объеме выборки стандартное нормальное распределение (табл. 1).
Таблица 1 – Гипотезы о генеральной доле
|
Гипотеза |
H0:p=p0 | H0:p1=p2 |
| Предположения | Схема испытаний Бернулли | Схема испытаний Бернулли |
| Оценки по выборке |  |
|
| Статистика K |  |
 |
| Распределение статистики K | Стандартное нормальное N(0,1) | Стандартное нормальное N(0,1) |
Пример №1. С помощью случайного повторного отбора руководство фирмы провело выборочный опрос 900 своих служащих. Среди опрошенных оказалось 270 женщин. Постройте доверительный интервал, с вероятностью 0.95 накрывающий истинную долю женщин во всем коллективе фирмы.
Решение. По условию выборочная доля женщин составляет ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле ![]() (относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
(относительная частота женщин среди всех опрошенных). Так как отбор является повторным, и объем выборки велик (n=900) предельная ошибка выборки определяется по формуле
Значение uкр находим по таблице функции Лапласа из соотношения 2Ф(uкр)=γ, т.е. ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка ![]() Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка и искомый доверительный интервал
Функция Лапласа (приложение 1) принимает значение 0.475 при uкр=1.96. Следовательно, предельная ошибка и искомый доверительный интервал
(p – ε, p + ε) = (0.3 – 0.18; 0.3 + 0.18) = (0.12; 0.48)
Итак, с вероятностью 0.95 можно гарантировать, что доля женщин во всем коллективе фирмы находится в интервале от 0.12 до 0.48.
Пример №2. Владелец автостоянки считает день «удачным», если автостоянка заполнена более, чем на 80 %. В течение года было проведено 40 проверок автостоянки, из которых 24 оказались «удачными». С вероятностью 0.98 найдите доверительный интервал для оценки истинной доли «удачных» дней в течение года.
Решение. Выборочная доля «удачных» дней составляет ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности ![]()
По таблице функции Лапласа найдем значение uкр при заданной
доверительной вероятности
Ф(2.23) = 0.49, uкр = 2.33.
Считая отбор бесповторным (т.е. две проверки в один день не проводилось), найдем предельную ошибку: ![]()
где n=40, N = 365 (дней). Отсюда ![]()
где n=40, N = 365 (дней). Отсюда
и доверительный интервал для генеральной доли: (p – ε, p + ε) = (0.6 – 0.17; 0.6 + 0.17) = (0.43; 0.77)
С вероятностью 0.98 можно ожидать, что доля «удачных» дней в течение года находится в интервале от 0.43 до 0.77.
Пример №3. Проверив 2500 изделий в партии, обнаружили, что 400 изделий высшего сорта, а n–m – нет. Сколько надо проверить изделий, чтобы с уверенностью 95% определить долю высшего сорта с точностью до 0.01?
Решение ищем по формуле определения численности выборки для повторного отбора.
Ф(t) = γ/2 = 0.95/2 = 0.475 и этому значению по таблице Лапласа соответствует t=1.96
Выборочная доля w = 0.16; ошибка выборки ε = 0.01
Пример №4. Партия изделий принимается, если вероятность того, что изделие окажется соответствующим стандарту, составляет не менее 0.97. Среди случайно отобранных 200 изделий проверяемой партии оказалось 193 соответствующих стандарту. Можно ли на уровне значимости α=0,02 принять партию?
Решение. Сформулируем основную и альтернативную гипотезы.
H0:p=p0=0,97 — неизвестная генеральная доля p равна заданному значению p0=0,97. Применительно к условию — вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, равна 0.97; т.е. партию изделий можно принять.
H1:p<0,97 – вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдаемое значение статистики K (таблица) вычислим при заданных значениях p0=0,97, n=200, m=193

Критическое значение находим по таблице функции Лапласа из равенства
![]()
По условию α=0,02 отсюда Ф(Ккр)=0,48 и Ккр=2,05. Критическая область левосторонняя, т.е. является интервалом (-∞;-Kkp)= (-∞;-2,05). Наблюдаемое значение Кнабл=-0,415 не принадлежит критической области, следовательно, на данном уровне значимости нет оснований отклонять основную гипотезу. Партию изделий принять можно.
Пример №5. Два завода изготавливают однотипные детали. Для оценки их качества сделаны выборки из продукции этих заводов и получены следующие результаты. Среди 200 отобранных изделий первого завода оказалось 20 бракованных, среди 300 изделий второго завода — 15 бракованных.
На уровне значимости 0.025 выяснить, имеется ли существенное различие в качестве изготавливаемых этими заводами деталей.
Решение. Это задача о сравнении генеральных долей двух совокупностей. Сформулируем основную и альтернативную гипотезы.
H0:p1=p2 — генеральные доли равны. Применительно к условию — вероятность появления бракованного изделия в продукции первого завода равна вероятности появления бракованного изделия в продукции второго завода (качество продукции одинаково).
H0:p1≠p2 — заводы изготавливают детали разного качества.
Для вычисления наблюдаемого значения статистики K (таблица) рассчитаем оценки по выборке.
![]()
![]()
Наблюдаемое значение равно

Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства ![]()
Так как альтернативная гипотеза двусторонняя, то критическое значение статистики K≈ N(0,1) находим по таблице функции Лапласа из равенства
По условию α=0,025 отсюда Ф(Ккр)=0,4875 и Ккр=2,24. При двусторонней альтернативе область допустимых значений имеет вид (-2,24;2,24). Наблюдаемое значение Kнабл=2,15 попадает в этот интервал, т.е. на данном уровне значимости нет оснований отвергать основную гипотезу. Заводы изготавливают изделия одинакового качества.
По части судить о целом
О возможности судить о целом по части миру рассказал российский математик П.Л. Чебышев. «Закон больших чисел» простым языком можно сформулировать так: количественные закономерности массовых явлений проявляются только при
достаточном числе наблюдений
. Чем больше выборка, тем лучше случайные отклонения компенсируют друг друга и проявляется общая тенденция.
А.М. Ляпунов чуть позже сформулировал центральную предельную теорему. Она стала фундаментом для создания формул, которые позволяют рассчитать вероятность ошибки (при оценке среднего по выборке) и размер выборки, необходимый для достижения заданной точности.
Строгие формулировки:
С увеличением числа случайных величин их среднее арифметическое стремится к среднему арифметическому математических ожиданий и перестает быть случайным. Общий смысл закона больших чисел — совместное действие большого числа случайных факторов приводит к результату, почти не зависящему от случая.
Таким образом з.б.ч. гарантирует устойчивость для средних значений некоторых случайных событий при достаточно длинной серии экспериментов.
Распределение случайной величины, которая получена в результате сложения большого числа независимых случайных величин (ни одно из которых не доминирует, не вносит в сумму определяющего вклада и имеет дисперсию значительно меньшею по сравнению с дисперсией суммы) имеет распределение, близкое к нормальному.
Из ц.п.т. следует, что ошибки выборки также подчиняется нормальному распределению.
Еще раз: чтобы корректно оценивать популяцию по выборке, нам нужна не обычная выборка, а репрезентативная выборка достаточного размера. Начнем с определения этого самого размера.
Как рассчитать объем выборки
Достаточный размер выборки зависит от следующих составляющих:
- изменчивость признака (чем разнообразней показания, тем больше наблюдений нужно, чтобы это уловить);
- размер эффекта (чем меньшие эффекты мы стремимся зафиксировать, тем больше наблюдений необходимо);
- уровень доверия (уровень вероятности при который мы готовы отвергнуть нулевую гипотезу)
ЗАПОМНИТЕ
Объем выборки зависит от изменчивости признака и планируемой строгости эксперимента
Формулы для расчета объема выборки:

Формулы расчета объема выборки
Ошибка выборки значительно возрастает, когда наблюдений меньше ста. Для исследований в которых используется 30-100 объектов применяется особая статистическая методология: критерии, основанные на распределении Стьюдента или бутстрэп-анализ. И наконец, статистика совсем слаба, когда наблюдений меньше 30.

График зависимости ошибки выборки от ее объема при оценке доли признака в г.с.
Чем больше неопределенность, тем больше ошибка. Максимальная неопределенность при оценке доли — 50% (например, 50% респондентов считают концепцию хорошей, а другие 50% плохой). Если 90% опрошенных концепция понравится — это, наоборот, пример согласованности. В таких случаях оценить долю признака по выборке проще.
Для экспонирования и выделения цветом значений статистических выбросов от медианы можно использовать несколько простых формул и условное форматирование.
Первым шагом в поиске значений выбросов статистики является определение статистического центра диапазона данных. С этой целью необходимо сначала определить границы первого и третьего квартала. Определение границ квартала – значит разделение данных на 4 равные группы, которые содержат по 25% данных каждая. Группа, содержащая 25% наибольших значений, называется первым квартилем.
Границы квартилей в Excel можно легко определить с помощью простой функции КВАРТИЛЬ. Данная функция имеет 2 аргумента: диапазон данных и номер для получения желаемого квартиля.
В примере показанному на рисунке ниже значения в ячейках E1 и E2 содержат показатели первого и третьего квартиля данных в диапазоне ячеек B2:B19:

Вычитая от значения первого квартиля третьего, можно определить набор 50% статистических данных, который называется межквартильным диапазоном. В ячейке E3 определен размер межквартильного диапазона.
В этом месте возникает вопрос, как сильно данное значение может отличаться от среднего значения 50% данных и оставаться все еще в пределах нормы? Статистические аналитики соглашаются с тем, что для определения нижней и верхней границы диапазона данных можно смело использовать коэффициент расширения 1,5 умножив на значение межквартильного диапазона. То есть:
- Нижняя граница диапазона данных равна: значение первого квартиля – межкваритльный диапазон * 1,5.
- Верхняя граница диапазона данных равна: значение третьего квартиля + расширенных диапазон * 1,5.
Как показано на рисунке ячейки E5 и E6 содержат вычисленные значения верхней и нижней границы диапазона данных. Каждое значение, которое больше верхней границы нормы или меньше нижней границы нормы считается значением статистического выброса.
Чтобы выделить цветом для улучшения визуального анализа данных можно создать простое правило для условного форматирования.
Способ 1: применение расширенного автофильтра
Наиболее простым способом произвести отбор является применение расширенного автофильтра. Рассмотрим, как это сделать на конкретном примере.
- Выделяем область на листе, среди данных которой нужно произвести выборку. Во вкладке «Главная» щелкаем по кнопке «Сортировка и фильтр». Она размещается в блоке настроек «Редактирование». В открывшемся после этого списка выполняем щелчок по кнопке «Фильтр».

Есть возможность поступить и по-другому. Для этого после выделения области на листе перемещаемся во вкладку «Данные». Щелкаем по кнопке «Фильтр», которая размещена на ленте в группе «Сортировка и фильтр».
- После этого действия в шапке таблицы появляются пиктограммы для запуска фильтрования в виде перевернутых острием вниз небольших треугольников на правом краю ячеек. Кликаем по данному значку в заглавии того столбца, по которому желаем произвести выборку. В запустившемся меню переходим по пункту «Текстовые фильтры». Далее выбираем позицию «Настраиваемый фильтр…».
- Активируется окно пользовательской фильтрации. В нем можно задать ограничение, по которому будет производиться отбор. В выпадающем списке для столбца содержащего ячейки числового формата, который мы используем для примера, можно выбрать одно из пяти видов условий:
- равно;
- не равно;
- больше;
- больше или равно;
- меньше.
Давайте в качестве примера зададим условие так, чтобы отобрать только значения, по которым сумма выручки превышает 10000 рублей. Устанавливаем переключатель в позицию «Больше». В правое поле вписываем значение «10000». Чтобы произвести выполнение действия, щелкаем по кнопке «OK».
- Как видим, после фильтрации остались только строчки, в которых сумма выручки превышает 10000 рублей.
- Но в этом же столбце мы можем добавить и второе условие. Для этого опять возвращаемся в окно пользовательской фильтрации. Как видим, в его нижней части есть ещё один переключатель условия и соответствующее ему поле для ввода. Давайте установим теперь верхнюю границу отбора в 15000 рублей. Для этого выставляем переключатель в позицию «Меньше», а в поле справа вписываем значение «15000».
Кроме того, существует ещё переключатель условий. У него два положения «И» и «ИЛИ». По умолчанию он установлен в первом положении. Это означает, что в выборке останутся только строчки, которые удовлетворяют обоим ограничениям. Если он будет выставлен в положение «ИЛИ», то тогда останутся значения, которые подходят под любое из двух условий. В нашем случае нужно выставить переключатель в положение «И», то есть, оставить данную настройку по умолчанию. После того, как все значения введены, щелкаем по кнопке «OK».
- Теперь в таблице остались только строчки, в которых сумма выручки не меньше 10000 рублей, но не превышает 15000 рублей.
- Аналогично можно настраивать фильтры и в других столбцах. При этом имеется возможность сохранять также фильтрацию и по предыдущим условиям, которые были заданы в колонках. Итак, посмотрим, как производится отбор с помощью фильтра для ячеек в формате даты. Кликаем по значку фильтрации в соответствующем столбце. Последовательно кликаем по пунктам списка «Фильтр по дате» и «Настраиваемый фильтр».
- Снова запускается окно пользовательского автофильтра. Выполним отбор результатов в таблице с 4 по 6 мая 2016 года включительно. В переключателе выбора условий, как видим, ещё больше вариантов, чем для числового формата. Выбираем позицию «После или равно». В поле справа устанавливаем значение «04.05.2016». В нижнем блоке устанавливаем переключатель в позицию «До или равно». В правом поле вписываем значение «06.05.2016». Переключатель совместимости условий оставляем в положении по умолчанию – «И». Для того, чтобы применить фильтрацию в действии, жмем на кнопку «OK».
- Как видим, наш список ещё больше сократился. Теперь в нем оставлены только строчки, в которых сумма выручки варьируется от 10000 до 15000 рублей за период с 04.05 по 06.05.2016 включительно.
- Мы можем сбросить фильтрацию в одном из столбцов. Сделаем это для значений выручки. Кликаем по значку автофильтра в соответствующем столбце. В выпадающем списке щелкаем по пункту «Удалить фильтр».
- Как видим, после этих действий, выборка по сумме выручки будет отключена, а останется только отбор по датам (с 04.05.2016 по 06.05.2016).
- В данной таблице имеется ещё одна колонка – «Наименование». В ней содержатся данные в текстовом формате. Посмотрим, как сформировать выборку с помощью фильтрации по этим значениям.
Кликаем по значку фильтра в наименовании столбца. Последовательно переходим по наименованиям списка «Текстовые фильтры» и «Настраиваемый фильтр…».
- Опять открывается окно пользовательского автофильтра. Давайте сделаем выборку по наименованиям «Картофель» и «Мясо». В первом блоке переключатель условий устанавливаем в позицию «Равно». В поле справа от него вписываем слово «Картофель». Переключатель нижнего блока так же ставим в позицию «Равно». В поле напротив него делаем запись – «Мясо». И вот далее мы выполняем то, чего ранее не делали: устанавливаем переключатель совместимости условий в позицию «ИЛИ». Теперь строчка, содержащая любое из указанных условий, будет выводиться на экран. Щелкаем по кнопке «OK».
- Как видим, в новой выборке существуют ограничения по дате (с 04.05.2016 по 06.05.2016) и по наименованию (картофель и мясо). По сумме выручки ограничений нет.
- Полностью удалить фильтр можно теми же способами, которые использовались для его установки. Причем неважно, какой именно способ применялся. Для сброса фильтрации, находясь во вкладке «Данные» щелкаем по кнопке «Фильтр», которая размещена в группе «Сортировка и фильтр».

Второй вариант предполагает переход во вкладку «Главная». Там выполняем щелчок на ленте по кнопке «Сортировка и фильтр» в блоке «Редактирование». В активировавшемся списке нажимаем на кнопку «Фильтр».

















При использовании любого из двух вышеуказанных методов фильтрация будет удалена, а результаты выборки – очищены. То есть, в таблице будет показан весь массив данных, которыми она располагает.

Способ 2: применение формулы массива
Сделать отбор можно также применив сложную формулу массива. В отличие от предыдущего варианта, данный метод предусматривает вывод результата в отдельную таблицу.
- На том же листе создаем пустую таблицу с такими же наименованиями столбцов в шапке, что и у исходника.
- Выделяем все пустые ячейки первой колонки новой таблицы. Устанавливаем курсор в строку формул. Как раз сюда будет заноситься формула, производящая выборку по указанным критериям. Отберем строчки, сумма выручки в которых превышает 15000 рублей. В нашем конкретном примере, вводимая формула будет выглядеть следующим образом:
=ИНДЕКС(A2:A29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Естественно, в каждом конкретном случае адрес ячеек и диапазонов будет свой. На данном примере можно сопоставить формулу с координатами на иллюстрации и приспособить её для своих нужд.
- Так как это формула массива, то для того, чтобы применить её в действии, нужно нажимать не кнопку Enter, а сочетание клавиш Ctrl+Shift+Enter. Делаем это.
- Выделив второй столбец с датами и установив курсор в строку формул, вводим следующее выражение:
=ИНДЕКС(B2:B29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Жмем сочетание клавиш Ctrl+Shift+Enter.
- Аналогичным образом в столбец с выручкой вписываем формулу следующего содержания:
=ИНДЕКС(C2:C29;НАИМЕНЬШИЙ(ЕСЛИ(15000<=C2:C29;СТРОКА(C2:C29);"");СТРОКА()-СТРОКА($C$1))-СТРОКА($C$1))Опять набираем сочетание клавиш Ctrl+Shift+Enter.
Во всех трех случаях меняется только первое значение координат, а в остальном формулы полностью идентичны.
- Как видим, таблица заполнена данными, но внешний вид её не совсем привлекателен, к тому же, значения даты заполнены в ней некорректно. Нужно исправить эти недостатки. Некорректность даты связана с тем, что формат ячеек соответствующего столбца общий, а нам нужно установить формат даты. Выделяем весь столбец, включая ячейки с ошибками, и кликаем по выделению правой кнопкой мыши. В появившемся списке переходим по пункту «Формат ячейки…».
- В открывшемся окне форматирования открываем вкладку «Число». В блоке «Числовые форматы» выделяем значение «Дата». В правой части окна можно выбрать желаемый тип отображения даты. После того, как настройки выставлены, жмем на кнопку «OK».
- Теперь дата отображается корректно. Но, как видим, вся нижняя часть таблицы заполнена ячейками, которые содержат ошибочное значение «#ЧИСЛО!». По сути, это те ячейки, данных из выборки для которых не хватило. Более привлекательно было бы, если бы они отображались вообще пустыми. Для этих целей воспользуемся условным форматированием. Выделяем все ячейки таблицы, кроме шапки. Находясь во вкладке «Главная» кликаем по кнопке «Условное форматирование», которая находится в блоке инструментов «Стили». В появившемся списке выбираем пункт «Создать правило…».
- В открывшемся окне выбираем тип правила «Форматировать только ячейки, которые содержат». В первом поле под надписью «Форматировать только ячейки, для которых выполняется следующее условие» выбираем позицию «Ошибки». Далее жмем по кнопке «Формат…».
- В запустившемся окне форматирования переходим во вкладку «Шрифт» и в соответствующем поле выбираем белый цвет. После этих действий щелкаем по кнопке «OK».
- На кнопку с точно таким же названием жмем после возвращения в окно создания условий.











Теперь у нас имеется готовая выборка по указанному ограничению в отдельной надлежащим образом оформленной таблице.

СРЗНАЧ()
Статистическая функция СРЗНАЧ возвращает среднее арифметическое своих аргументов.

Данная функция может принимать до 255 аргументов и находить среднее сразу в нескольких несмежных диапазонах и ячейках:

Если в рассчитываемом диапазоне встречаются пустые или содержащие текст ячейки, то они игнорируются. В примере ниже среднее ищется по четырем ячейкам, т.е. (4+15+11+22)/4 = 13

Если необходимо вычислить среднее, учитывая все ячейки диапазона, то можно воспользоваться статистической функцией СРЗНАЧА. В следующем примере среднее ищется уже по 6 ячейкам, т.е. (4+15+11+22)/6 = 8,6(6).

Статистическая функция СРЗНАЧ может использовать в качестве своих аргументов математические операторы и различные функции Excel:

СРЗНАЧЕСЛИ()
Если необходимо вернуть среднее арифметическое значений, которые удовлетворяют определенному условию, то можно воспользоваться статистической функцией СРЗНАЧЕСЛИ. Следующая формула вычисляет среднее чисел, которые больше нуля:

В данном примере для подсчета среднего и проверки условия используется один и тот же диапазон, что не всегда удобно. На этот случай у функции СРЗНАЧЕСЛИ существует третий необязательный аргумент, по которому можно вычислять среднее. Т.е. по первому аргументу проверяем условие, по третьему – находим среднее.
Допустим, в таблице ниже собрана статистика по стоимости лекарств в городе. В одной аптеке лекарство стоит дороже, в другой дешевле. Чтобы посчитать стоимость анальгина в среднем по городу, воспользуемся следующей формулой:

Если требуется соблюсти несколько условий, то всегда можно применить статистическую функцию СРЗНАЧЕСЛИМН, которая позволяет считать среднее арифметическое ячеек, удовлетворяющих двум и более критериям.
МАКС()
Статистическая функция МАКС возвращает наибольшее значение в диапазоне ячеек:

МИН()
Статистическая функция МИН возвращает наименьшее значение в диапазоне ячеек:

Источники
- https://lumpics.ru/descriptive-statistics-in-excel/
- https://statanaliz.info/statistica/opisanie-dannyx/variatsiya-razmakh-srednee-linejnoe-otklonenie/
- https://www.hd01.ru/info/kak-poschitat-razmah-v-excel/
- http://galyautdinov.ru/post/formula-vyborki-prostaya
- https://math.semestr.ru/group/interval-estimation-share.php
- https://tidydata.ru/sample-size
- https://exceltable.com/formuly/raschet-statisticheskih-vybrosov
- https://lumpics.ru/how-to-make-a-sample-in-excel/
- https://office-guru.ru/excel/statisticheskie-funkcii-excel-kotorye-neobhodimo-znat-96.html
Необходимое предисловие
Эта статья является логическим продолжением предыдущего материала про новые динамические массивы
(ДМ), появившиеся в Excel в Office 365. Если вы ещё с не ознакомились (кому лень читать — там есть видео), то очень советую сделать это сейчас, чтобы понимать о чём, собственно, идёт речь и как заполучить все эти радости в вашем Excel.
Обновление Office 365, которое подарило Microsoft Excel новый вычислительный движок с поддержкой динамических массивов, также добавило к нашему арсеналу 7 новых функций, заточенных специально для работы с массивами. Про три самых важных функции: СОРТ (SORT), ФИЛЬТР (FILTER) и УНИК (UNIQUE) я уже писал, а в этой статье хотел разобрать ещё одну весьма приятную обнову — функцию ПОСЛЕД (SEQUENCE).
Обманчивая простота
Эта функция предназначена для совершенно, на первый взгляд, банальной задачи — генерации числовых последовательностей (рядов, арифметических прогрессий) с определённым шагом и от заданного стартового значения. Синтаксис функции предельно прост:
=ПОСЛЕД(строки; [столбцы]; [начало]; [шаг])
где
- строки — число строк в диапазоне, который надо заполнить числовой последовательностью — это единственный обязательный аргумент;
- столбцы — число столбцов в диапазоне (если нужно сгенерить двумерный массив)
- начало — стартовое значение (если не задано, то 1)
- шаг — шаг изменения ряда (если не задан, то 1)
Последние два аргумента могут быть и дробными, и отрицательными числами при необходимости.
Да, я знаю — выглядит это все как-то скучновато, но не доверяйте первому обманчивому впечатлению. У этой функции есть масса практических вариантов применения — давайте рассмотрим несколько случаев, чтобы вы ухватили идею.
Пример 1. Посимвольный разбор текста
Уверен, вы не раз встречались при заполнении бланков и всевозможных анкет с необходимостью «распатронить» текст на отдельные символы по отдельным ячейкам. С нашей функцией ПОСЛЕД эта задача решается в два счёта:

В английской версии это будет
=MID(A1;SEQUENCE(1;LEN(A1));1)
Логика тут простая:
- Сначала функция ПОСЛЕД формирует простой числовой ряд 1, 2, 3 … N, где N — длина исходного текста, определяемая функцией ДЛСТР (LEN).
- Затем функция ПСТР (MID) выдёргивает из исходного текста символы по очереди, используя сгенерированную последовательность как порядковый номер извлекаемого символа.
Для аналогичного разбора даты по ячейкам, придется добавить ещё функцию ТЕКСТ (TEXT) для преобразования даты в текст — иначе на выходе мы получим код даты, а не её саму в привычном виде. Ну, а длину в этом случае мы знаем заранее — 10 символов:

Пример 2. Сумма каждой N-ой ячейки
Классическая задача про суммирование ячеек с заданным шагом, несколько способов решения которой я уже описывал. С помощью нашей новой функции ПОСЛЕД решается просто и изящно:

Функция ПОСЛЕД (SEQUENCE) здесь генерит числовую последовательность номеров строк, откуда нам нужно взять данные: 5, 9, 13, 17, 21.
Затем функция ИНДЕКС (INDEX) вытаскивает значения по этим номерам из столбца А, и затем мы их суммируем с помощью СУММ (SUM).
Пример 3. Трансформация столбца в таблицу
Самый красивый пример — преобразование столбца с данными в двумерную таблицу одной короткой формулой:

Здесь функция ПОСЛЕД сначала формирует двумерную последовательность, где каждое число — это, по сути, номер строки из нашей таблицы данных, откуда нужно взять значение для данной ячейки:

Чтобы не привязываться к жёстко прописанному количеству блоков (людей) в таблице — мы используем функцию СЧЁТЗ (COUNTA), чтобы вычислить их количество.
А затем мы извлекаем данные из левой таблицы по номеру строки с помощью функции ИНДЕКС (INDEX). (Если вы с ней ещё, не дай бог, не знакомы, то обязательно посмотрите эту статью).
Ну, и для полной картины, преобразование исхдной таблицы в динамическую «умную» даёт нам возможность не думать про её размеры — при добавлении новых данных к ней в будущем они автоматически попадут и в результаты.
Красота!
Пример 4. Многоуровневая нумерация
Это пример на перезапускающиеся числовые последовательности. В реальной жизни такое часто встречается, например, во вложенной нумерации пунктов 1.1 — 1.2 — 1.3 и т.д.
Допустим, что нам необходимо создать шаблон для заполнения посменного расписания. Причем количество смен и количество сотрудников в смене — величины переменные и должны браться из соответствующих ячеек:

Для столбца с номером смены нам нужна последовательность с повторениями каждого числа ряда (номер смены) заданное количество раз (число сотрудников в смене). Это можно легко реализовать формулой:

В английской версии это, соответственно:
=ROUNDUP(SEQUENCE(B2*B4)/B4;0)
Здесь:
- Функция ПОСЛЕД сначала генерирует числовую последовательность 1, 2, 3 .. 15 (общее число строк, равное произведению количества смен на количество людей в каждой смене)
- Мы делим эти числа на число людей в каждой смене и получаем последовательность дробных чисел: 0.2, 0.4, 0.6, 0.8, 1, 1.2 и т.д.
- Затем мы округляем эти дробные числа до ближайшего целого функцией ОКРУГЛВВЕРХ (ROUNDUP).
Для столбца с номерами сотрудников внутри смены нам нужна формула чуть сложнее — с перезапускающейся каждые 5 ячеек заново последовательностью:

Здесь мы сначала вычисляем остаток от деления нашей последовательности 1,2,3…15 на 5 с помощью функции ОСТАТ (MOD):

А затем заменяем нули на 5 — значение из ячейки B4 с помощью функции ЕСЛИ (IF).
Дополнительно, можно подтянуть к нашему графику еще и имена сотрудников из списка с помощью уже знакомой нам функции ИНДЕКС (INDEX):

Заключение и выводы
Надеюсь, я донёс до вас мысль, что эта функция не такая бессмысленная, как многим кажется на первый взгляд, а разобранные примеры станут достаточным импульсом для самостоятельных ваших экспериментов в этом направлении. Интересными найденными вариантами применения можно делиться тут же в комментариях, если что.
Если же вы пока ещё не получили обновление, которое добавляет в ваш Excel динамические массивы и эти новые функции, то когда придет время — вы будете готовы 
Ссылки по теме
- Динамические массивы — тихая революция в Excel
- Функции СОРТ, ФИЛЬТР и УНИК в последнем обновлении Excel
- Функция ПРОСМОТРХ — наследник ВПР
Продолжаем рассказывать про неочевидные штуки в Экселе, которые могут пригодиться для работы с данными. Сегодня будет про аналитику — как собрать, подготовить или получить дополнительные данные, чтобы анализ получился более полный.
МИНЕСЛИ и МАКСЕСЛИ
В английской версии: MINIF, MAXIF.
Что делают: находят минимальное и максимальное значение по какому-то условию в заданных диапазонах.
Допустим, у нас есть таблица доходов и расходов, причём доходы получены из разных источников:

С помощью функций МИНЕСЛИ и МАКСЕСЛИ мы можем найти минимальные и максимальные значения по заданному параметру. Например, найдём минимальный доход, который мы получили с внешних заказов. Для этого напишем формулу:
=MINIFS(B2:B13;C2:C13;»заказ»)
Первый параметр — это диапазон, где ищем минимальное значение, второй — диапазон, по которому мы будем проверять наше условие, и третий — само условие. Получается, что формула возьмёт слово «заказ», найдёт в столбце C все совпадения с ним, а потом найдёт в столбце B минимальное значение:

Точно так же можно найти максимальный доход на работе — вдруг работать только с заказами выгоднее:

ВПР
В английской версии: VLOOKUP
Что делает: сопоставляет данные из одного столбца с другим.
Это одна из самых популярных функций при анализе данных в Экселе — с ней можно быстро находить данные в одном столбце и смотреть, чему они соответствуют в другом. Например, если мы хотим посмотреть, сколько потратили в марте, то используем такую формулу:
=VLOOKUP(«Март»;A2:D13;4;FALSE)
Функция возьмёт наш «Март», проверит весь диапазон, который мы указали, найдёт в нём наше слово и выведет результат из четвёртого столбца, который соответствует марту. Параметр FALSE означает, что нам нужно точное совпадение, — если хватит примерного, поставьте TRUE.
Это выглядит просто на нашей таблице — тут значения можно найти и без функций. Но когда у тебя не 12 строк, а 12 тысяч, то с формулами получается проще.


СУММЕСЛИМН
В английской версии: SUMIFS
Что делает: складывает значения, которые подходят сразу к нескольким параметрам.
Бывает так, что нам нужно найти сумму значений сразу по нескольким параметрам — когда они все выполняются, то мы складываем между собой те ячейки, где есть такое полное совпадение. Например, найдём, сколько мы заработали на удалёнке на основной работе — используем для этого формулу:
=SUMIFS(B2:B13;C2:C13;»работа»;E2:E13;»удалёнка»)
Здесь мы первым параметром задаём, из какого столбца будем брать числа для суммы, потом два параметра — фильтр по источнику, и последние два — выбираем только те, где вид стоит «удалёнка»:


СЧЁТЕСЛИМН
В английской версии: COUNTIFS
Что делает: то же самое, что и СУММЕСЛИМН, только не складывает значения, а считает совпадения.
Если нам нужно выяснить, сколько раз мы брались за внешние заказы и получали за это меньше ста тысяч рублей, то можем использовать такую формулу:
=COUNTIFS(C2:C13;»заказ»; B2:B13;»<100000″)
Здесь всё то же самое, что и в предыдущей формуле, только без первого столбца для суммы. Обратите внимание, что знак сравнения входит в кавычки.

СЦЕПИТЬ
В английской версии: CONCATENATE
Что делает: склеивает несколько ячеек в одну.
Если нам нужно подготовить данные для выгрузки или привести их в более понятный вид, иногда используют склейку ячеек. Смысл в том, что можно задать правила объединения на примере одной ячейки, потом протянуть её вниз, сколько нужно, а Эксель сам заполнит их новыми склеенными данными.
Допустим, нам нужно вывести для отчёта такую фразу для каждого месяца: «Январь: заработано столько-то рублей, потрачено столько-то, остаток вот такой». Чтобы не собирать это всё вручную, пишем формулу:
=CONCATENATE(A2;»: заработано «;B2;», потрачено «;D2;», остаток: «;E2)
Здесь мы просто через точку с запятой указываем как ячейки, так и текстовые значения, которые хотим добавить в итоговую строчку. Кроме текста, туда можно добавлять что угодно — например результаты вычислений или текст из других ячеек.


СЖПРОБЕЛЫ
В английской версии: TRIM
Что делает: убирает лишние пробелы между словами, оставляя по одному пробелу.
Иногда данные для анализа попадают в таблицу в непотребном виде — например, с кучей пробелов между словами. Если это наш случай, используем функцию СЖПРОБЕЛЫ — она удалит лишнее и сделает красивый текст:
=TRIM(A1:A4)
В функции можно указать сразу весь диапазон для обработки (и тогда она сама добавит нужные ячейки ниже) или указать только одну ячейку.

Вёрстка:
Кирилл Климентьев