
У нас есть последовательность чисел, состоящая из практически независимых элементов, которые подчиняются заданному распределению. Как правило, равномерному распределению.
Сгенерировать случайные числа в Excel можно разными путями и способами. Рассмотрим только лучше из них.
Функция случайного числа в Excel
- Функция СЛЧИС возвращает случайное равномерно распределенное вещественное число. Оно будет меньше 1, больше или равно 0.
- Функция СЛУЧМЕЖДУ возвращает случайное целое число.
Рассмотрим их использование на примерах.
Выборка случайных чисел с помощью СЛЧИС
Данная функция аргументов не требует (СЛЧИС()).
Чтобы сгенерировать случайное вещественное число в диапазоне от 1 до 5, например, применяем следующую формулу: =СЛЧИС()*(5-1)+1.

Возвращаемое случайное число распределено равномерно на интервале [1,10].
При каждом вычислении листа или при изменении значения в любой ячейке листа возвращается новое случайное число. Если нужно сохранить сгенерированную совокупность, можно заменить формулу на ее значение.
- Щелкаем по ячейке со случайным числом.
- В строке формул выделяем формулу.
- Нажимаем F9. И ВВОД.
Проверим равномерность распределения случайных чисел из первой выборки с помощью гистограммы распределения.
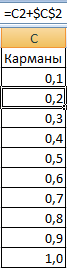
- Сформируем «карманы». Диапазоны, в пределах которых будут находиться значения. Первый такой диапазон – 0-0,1. Для следующих – формула =C2+$C$2.
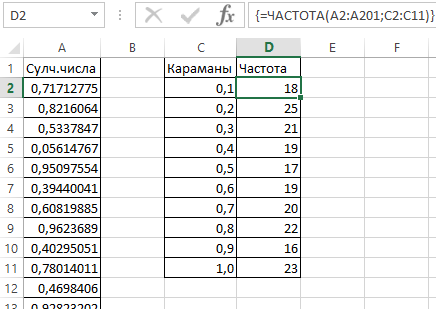
- Определим частоту для случайных чисел в каждом диапазоне. Используем формулу массива {=ЧАСТОТА(A2:A201;C2:C11)}.
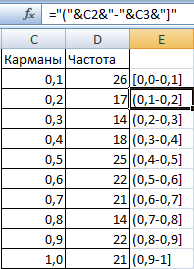
- Сформируем диапазоны с помощью знака «сцепления» (=»[0,0-«&C2&»]»).
- Строим гистограмму распределения 200 значений, полученных с помощью функции СЛЧИС ().
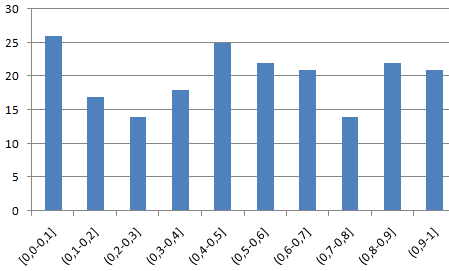
Диапазон вертикальных значений – частота. Горизонтальных – «карманы».
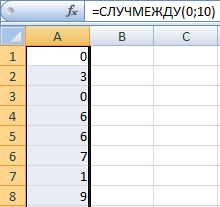
Функция СЛУЧМЕЖДУ
Синтаксис функции СЛУЧМЕЖДУ – (нижняя граница; верхняя граница). Первый аргумент должен быть меньше второго. В противном случае функция выдаст ошибку. Предполагается, что границы – целые числа. Дробную часть формула отбрасывает.
Пример использования функции:
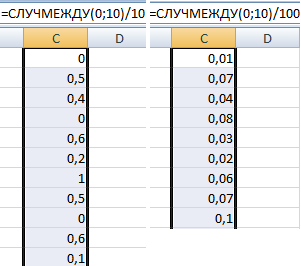
Случайные числа с точностью 0,1 и 0,01:
Как сделать генератор случайных чисел в Excel
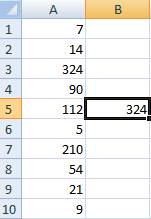
Сделаем генератор случайных чисел с генерацией значения из определенного диапазона. Используем формулу вида: =ИНДЕКС(A1:A10;ЦЕЛОЕ(СЛЧИС()*10)+1).
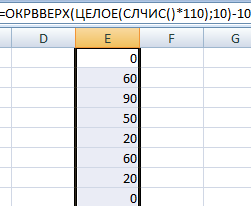
Сделаем генератор случайных чисел в диапазоне от 0 до 100 с шагом 10.
Из списка текстовых значений нужно выбрать 2 случайных. С помощью функции СЛЧИС сопоставим текстовые значения в диапазоне А1:А7 со случайными числами.
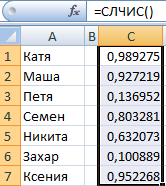
Воспользуемся функцией ИНДЕКС для выбора двух случайных текстовых значений из исходного списка.
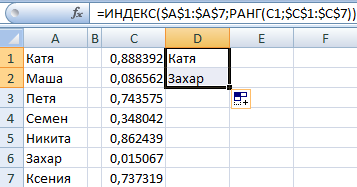
Чтобы выбрать одно случайное значение из списка, применим такую формулу: =ИНДЕКС(A1:A7;СЛУЧМЕЖДУ(1;СЧЁТЗ(A1:A7))).
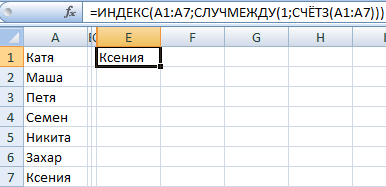
Генератор случайных чисел нормального распределения
Функции СЛЧИС и СЛУЧМЕЖДУ выдают случайные числа с единым распределением. Любое значение с одинаковой долей вероятности может попасть в нижнюю границу запрашиваемого диапазона и в верхнюю. Получается огромный разброс от целевого значения.
Нормальное распределение подразумевает близкое положение большей части сгенерированных чисел к целевому. Подкорректируем формулу СЛУЧМЕЖДУ и создадим массив данных с нормальным распределением.
Себестоимость товара Х – 100 рублей. Вся произведенная партия подчиняется нормальному распределению. Случайная переменная тоже подчиняется нормальному распределению вероятностей.
При таких условиях среднее значение диапазона – 100 рублей. Сгенерируем массив и построим график с нормальным распределением при стандартном отклонении 1,5 рубля.
Используем функцию: =НОРМОБР(СЛЧИС();100;1,5).
Программа Excel посчитала, какие значения находятся в диапазоне вероятностей. Так как вероятность производства товара с себестоимостью 100 рублей максимальная, формула показывает значения близкие к 100 чаще, чем остальные.
Перейдем к построению графика. Сначала нужно составить таблицу с категориями. Для этого разобьем массив на периоды:
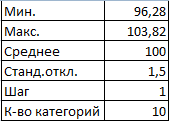
- Определим минимальное и максимальное значение в диапазоне с помощью функций МИН и МАКС.
- Укажем величину каждого периода либо шаг. В нашем примере – 1.
- Количество категорий – 10.
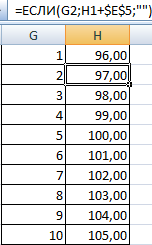
- Нижняя граница таблицы с категориями – округленное вниз ближайшее кратное число. В ячейку Н1 вводим формулу =ОКРВНИЗ(E1;E5).
- В ячейке Н2 и последующих формула будет выглядеть следующим образом: =ЕСЛИ(G2;H1+$E$5;»»). То есть каждое последующее значение будет увеличено на величину шага.
- Посчитаем количество переменных в заданном промежутке. Используем функцию ЧАСТОТА. Формула будет выглядеть так:
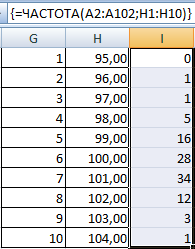
На основе полученных данных сможем сформировать диаграмму с нормальным распределением. Ось значений – число переменных в промежутке, ось категорий – периоды.
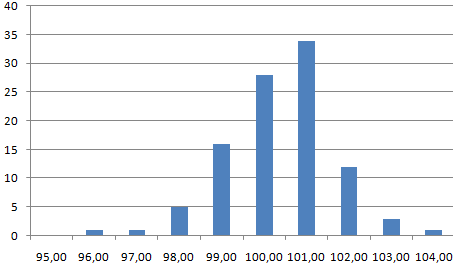
График с нормальным распределением готов. Как и должно быть, по форме он напоминает колокол.
Сделать то же самое можно гораздо проще. С помощью пакета «Анализ данных». Выбираем «Генерацию случайных чисел».
О том как подключить стандартную настройку «Анализ данных» читайте здесь.
Заполняем параметры для генерации. Распределение – «нормальное».
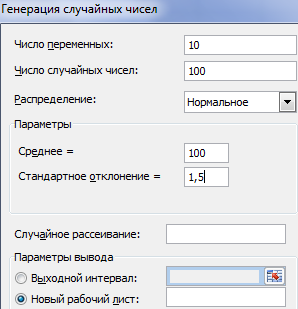
Жмем ОК. Получаем набор случайных чисел. Снова вызываем инструмент «Анализ данных». Выбираем «Гистограмма». Настраиваем параметры. Обязательно ставим галочку «Вывод графика».
Получаем результат:
Скачать генератор случайных чисел в Excel
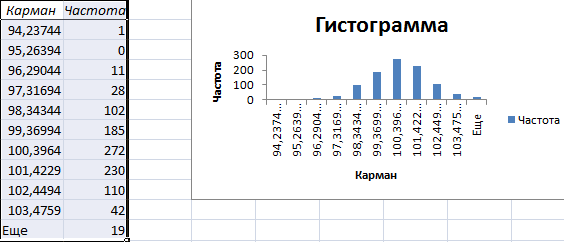
График с нормальным распределением в Excel построен.
Продолжаем рассказывать про неочевидные штуки в Экселе, которые могут пригодиться для работы с данными. Сегодня будет про аналитику — как собрать, подготовить или получить дополнительные данные, чтобы анализ получился более полный.
МИНЕСЛИ и МАКСЕСЛИ
В английской версии: MINIF, MAXIF.
Что делают: находят минимальное и максимальное значение по какому-то условию в заданных диапазонах.
Допустим, у нас есть таблица доходов и расходов, причём доходы получены из разных источников:

С помощью функций МИНЕСЛИ и МАКСЕСЛИ мы можем найти минимальные и максимальные значения по заданному параметру. Например, найдём минимальный доход, который мы получили с внешних заказов. Для этого напишем формулу:
=MINIFS(B2:B13;C2:C13;»заказ»)
Первый параметр — это диапазон, где ищем минимальное значение, второй — диапазон, по которому мы будем проверять наше условие, и третий — само условие. Получается, что формула возьмёт слово «заказ», найдёт в столбце C все совпадения с ним, а потом найдёт в столбце B минимальное значение:

Точно так же можно найти максимальный доход на работе — вдруг работать только с заказами выгоднее:

ВПР
В английской версии: VLOOKUP
Что делает: сопоставляет данные из одного столбца с другим.
Это одна из самых популярных функций при анализе данных в Экселе — с ней можно быстро находить данные в одном столбце и смотреть, чему они соответствуют в другом. Например, если мы хотим посмотреть, сколько потратили в марте, то используем такую формулу:
=VLOOKUP(«Март»;A2:D13;4;FALSE)
Функция возьмёт наш «Март», проверит весь диапазон, который мы указали, найдёт в нём наше слово и выведет результат из четвёртого столбца, который соответствует марту. Параметр FALSE означает, что нам нужно точное совпадение, — если хватит примерного, поставьте TRUE.
Это выглядит просто на нашей таблице — тут значения можно найти и без функций. Но когда у тебя не 12 строк, а 12 тысяч, то с формулами получается проще.


СУММЕСЛИМН
В английской версии: SUMIFS
Что делает: складывает значения, которые подходят сразу к нескольким параметрам.
Бывает так, что нам нужно найти сумму значений сразу по нескольким параметрам — когда они все выполняются, то мы складываем между собой те ячейки, где есть такое полное совпадение. Например, найдём, сколько мы заработали на удалёнке на основной работе — используем для этого формулу:
=SUMIFS(B2:B13;C2:C13;»работа»;E2:E13;»удалёнка»)
Здесь мы первым параметром задаём, из какого столбца будем брать числа для суммы, потом два параметра — фильтр по источнику, и последние два — выбираем только те, где вид стоит «удалёнка»:


СЧЁТЕСЛИМН
В английской версии: COUNTIFS
Что делает: то же самое, что и СУММЕСЛИМН, только не складывает значения, а считает совпадения.
Если нам нужно выяснить, сколько раз мы брались за внешние заказы и получали за это меньше ста тысяч рублей, то можем использовать такую формулу:
=COUNTIFS(C2:C13;»заказ»; B2:B13;»<100000″)
Здесь всё то же самое, что и в предыдущей формуле, только без первого столбца для суммы. Обратите внимание, что знак сравнения входит в кавычки.

СЦЕПИТЬ
В английской версии: CONCATENATE
Что делает: склеивает несколько ячеек в одну.
Если нам нужно подготовить данные для выгрузки или привести их в более понятный вид, иногда используют склейку ячеек. Смысл в том, что можно задать правила объединения на примере одной ячейки, потом протянуть её вниз, сколько нужно, а Эксель сам заполнит их новыми склеенными данными.
Допустим, нам нужно вывести для отчёта такую фразу для каждого месяца: «Январь: заработано столько-то рублей, потрачено столько-то, остаток вот такой». Чтобы не собирать это всё вручную, пишем формулу:
=CONCATENATE(A2;»: заработано «;B2;», потрачено «;D2;», остаток: «;E2)
Здесь мы просто через точку с запятой указываем как ячейки, так и текстовые значения, которые хотим добавить в итоговую строчку. Кроме текста, туда можно добавлять что угодно — например результаты вычислений или текст из других ячеек.


СЖПРОБЕЛЫ
В английской версии: TRIM
Что делает: убирает лишние пробелы между словами, оставляя по одному пробелу.
Иногда данные для анализа попадают в таблицу в непотребном виде — например, с кучей пробелов между словами. Если это наш случай, используем функцию СЖПРОБЕЛЫ — она удалит лишнее и сделает красивый текст:
=TRIM(A1:A4)
В функции можно указать сразу весь диапазон для обработки (и тогда она сама добавит нужные ячейки ниже) или указать только одну ячейку.

Вёрстка:
Кирилл Климентьев
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Еще…Меньше
Если вам нужно разработать сложный статистический или инженерный анализ, вы можете сэкономить время и этапы с помощью этого средства. Вы предоставляете данные и параметры для каждого анализа, а средство использует соответствующие статистические или инженерные функции для вычисления и отображения результатов в выходной таблице. Некоторые средства создают диаграммы в дополнение к выходным таблицам.
Функции анализа данных можно применять только на одном листе. Если анализ данных проводится в группе, состоящей из нескольких листов, то результаты будут выведены на первом листе, на остальных листах будут выведены пустые диапазоны, содержащие только форматы. Чтобы провести анализ данных на всех листах, повторите процедуру для каждого листа в отдельности.
Ниже описаны инструменты, включенные в пакет анализа. Для доступа к ним нажмите кнопкуАнализ данных в группе Анализ на вкладке Данные. Если команда Анализ данных недоступна, необходимо загрузить надстройку «Пакет анализа».
-
Откройте вкладку Файл, нажмите кнопку Параметры и выберите категорию Надстройки.
-
В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
Если вы используете Excel для Mac, в строке меню откройте вкладку Средства и в раскрывающемся списке выберите пункт Надстройки для Excel.
-
В диалоговом окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
-
Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
-
Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
-
Примечание: Чтобы включить Visual Basic для приложений (VBA) для надстройки «Надстройка анализа», вы можете загрузить надстройку VBA так же, как и надстройку «Надстройка анализа». В поле Доступные надстройки выберите «Надстройка анализа — VBA».
Существует несколько видов дисперсионного анализа. Нужный вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ
Этот инструмент выполняет простой анализ дисперсии данных для двух или более выборок. Анализ дает проверку гипотезы о том, что каждая выборка взята из одного и того же распределения вероятности на основе альтернативной гипотезы о том, что для всех выборок распределение вероятности не одно и то же. Если есть только два примера, можно использовать функцию T.ТЕСТ. В более чем двух примерах нет удобного обобщения T.ВМЕСТОэтого можно использовать модель Anova для одного фактора.
Двухфакторный дисперсионный анализ с повторениями
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам. Например, в эксперименте по измерению высоты растений последние обрабатывали удобрениями от различных изготовителей (например, A, B, C) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий {удобрение, температура}, имеется одинаковый набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы:
-
Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности. Температура в этом анализе не учитывается.
-
Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности. Марка удобрения в этом анализе не учитывается.
Извлечены ли шесть выборок, представляющих все пары значений {удобрение, температура}, используемые для оценки влияния различных марок удобрений (для первого пункта в списке) и уровней температуры (для второго пункта в списке), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар {удобрение, температура} превышает влияние отдельно удобрения и отдельно температуры.
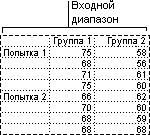
Двухфакторный дисперсионный анализ без повторений
Этот инструмент анализа применяется, если данные можно систематизировать по двум параметрам, как в случае двухфакторного дисперсионного анализа с повторениями. Однако в таком анализе предполагается, что для каждой пары параметров есть только одно измерение (например, для каждой пары параметров {удобрение, температура} из предыдущего примера).
Функции CORREL и PEARSON вычисляют коэффициент корреляции между двумя переменными измерения, если для каждой переменной наблюдаемы измерения по каждому из N-объектов. (Любые отсутствующие наблюдения по любой теме вызывают игнорирование в анализе.) Средство анализа корреляции особенно удобно использовать, если для каждого субъекта N имеется более двух переменных измерения. Она содержит выходную таблицу — матрицу корреляции, которая показывает значение CORREL (или PEARSON),примененного к каждой из возможных пар переменных измерения.
Коэффициент корреляции, как и ковариана, — это мера степени, в которой две единицы измерения «различаются». В отличие от ковариации коэффициент корреляции масштабирован таким образом, что его значение не зависит от единиц измерения, выраженных в двух переменных измерения. (Например, если двумя переменными измерения являются вес и высота, то значение коэффициента корреляции не изменяется, если вес преобразуется из фунта в фунты.) Значение любого коэффициента корреляции должно быть включительно от -1 до +1 включительно.
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Средства корреляции и коварианс могут использоваться в одном и том же параметре, если у вас есть N различных переменных измерения, наблюдаемые для набора людей. Каждый из инструментов корреляции и ковариции дает выходную таблицу — матрицу, которая показывает коэффициент корреляции или коварианс между каждой парой переменных измерения соответственно. Разница заключается в том, что коэффициенты корреляции масштабироваться в зависимости от -1 и +1 включительно. Соответствующие ковариансы не масштабироваться. Коэффициент корреляции и коварианс — это показатели степени, в которой две переменные «различаются».
Инструмент Ковариана вычисляет значение функции КОВАРИАНА. P для каждой пары переменных измерения. (Прямое использование КОВАРИАНА. P вместо ковариана является разумной альтернативой, если есть только две переменные измерения, то есть N=2.) Запись в диагонали выходной таблицы средства Коварица в строке i, столбце i — коварианс i-й переменной измерения. Это только дисперсия по численности населения для этой переменной, вычисляемая функцией ДИСПЕРС.P.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Инструмент анализа «Описательная статистика» применяется для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Инструмент анализа «Экспоненциальное сглаживание» применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, величина которой определяет степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание: Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
С помощью этого инструмента вычисляется значение f F-статистики (или F-коэффициент). Значение f, близкое к 1, показывает, что дисперсии генеральной совокупности равны. В таблице результатов, если f < 1, «P(F <= f) одностороннее» дает возможность наблюдения значения F-статистики меньшего f при равных дисперсиях генеральной совокупности и F критическом одностороннем выдает критическое значение меньше 1 для выбранного уровня значимости «Альфа». Если f > 1, «P(F <= f) одностороннее» дает возможность наблюдения значения F-статистики большего f при равных дисперсиях генеральной совокупности и F критическом одностороннем дает критическое значение больше 1 для «Альфа».
Инструмент «Анализ Фурье» применяется для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Этот инструмент поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.

Инструмент «Гистограмма» применяется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, можно получить распределение успеваемости по шкале оценок в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и групп студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто встречающийся уровень является модой диапазона данных.
Совет: В Excel 2016 теперь можно создавать гистограммы и диаграммы Парето.
Инструмент анализа «Скользящее среднее» применяется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других тенденций. Расчет прогнозируемых значений выполняется по следующей формуле:
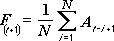
где
-
N — число предшествующих периодов, входящих в скользящее среднее;
-
A
j — фактическое значение в момент времени j; -
F
j — прогнозируемое значение в момент времени j.
Инструмент «Генерация случайных чисел» применяется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью этой процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей. Например, можно использовать нормальное распределение для моделирования совокупности данных по росту людей или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Средство анализа Ранг и процентиль создает таблицу, которая содержит порядковую и процентную ранг каждого значения в наборе данных. Можно проанализировать относительное положение значений в наборе данных. В этом средстве используются функции РАНГ. EQ и PERCENTRANK. INC. Если вы хотите учитывать связанные значения, используйте РАНГ. Функция EQ, которая обрабатывает связанные значения как имеющие одинаковый ранг или использует РАНГ.Функция AVG, которая возвращает средний ранг связанных значений.
Инструмент анализа «Регрессия» применяется для подбора графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или нескольких независимых переменных. Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Можно вычислить степень влияния каждого из этих трех факторов по результатам выступления спортсмена, а затем использовать полученные данные для предсказания выступления другого спортсмена.
В средстве регрессии используется функция LINEST.
Инструмент анализа «Выборка» создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла. Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Три вида этого теста допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для всех трех средств, перечисленных ниже, значение t вычисляется и отображается как «t-статистика» в выводимой таблице. В зависимости от данных это значение t может быть отрицательным или неотрицательным. Если предположить, что средние генеральной совокупности равны, при t < 0 «P(T <= t) одностороннее» дает вероятность того, что наблюдаемое значение t-статистики будет более отрицательным, чем t. При t >=0 «P(T <= t) одностороннее» делает возможным наблюдение значения t-статистики, которое будет более положительным, чем t. «t критическое одностороннее» дает пороговое значение, так что вероятность наблюдения значения t-статистики большего или равного «t критическое одностороннее» равно «Альфа».
«P(T <= t) двустороннее» дает вероятность наблюдения значения t-статистики, по абсолютному значению большего, чем t. «P критическое двустороннее» выдает пороговое значение, так что значение вероятности наблюдения значения t- статистики, по абсолютному значению большего, чем «P критическое двустороннее», равно «Альфа».
Парный двухвыборочный t-тест для средних
Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента. Этот инструмент анализа применяется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные.
Примечание: Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле:
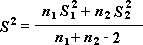
Двухвыборочный t-тест с одинаковыми дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных поступили из распределения с одинаковыми дисперсиями. Его называют гомике t-тестом. Этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения.
Двухвыборочный t-тест с различными дисперсиями
Этот инструмент анализа выполняет t-тест для двух образцов учащихся. В этой форме t-test предполагается, что два набора данных были полученными из распределения с неравными дисперсиями. Его называют гетероскестическими t-тестами. Как и в предыдущем примере с равными дисперсиями, этот t-тест можно использовать для определения вероятности того, что эти две выборки взяты из распределения с равными средствами распределения. Этот тест можно использовать, если в двух примерах есть отдельные объекты. Используйте тест Парный, описанный в примере, если существует один набор тем и две выборки представляют измерения по каждой теме до и после обработки.
Для определения тестовой величины t используется следующая формула.
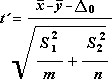
Следующая формула используется для вычисления степеней свободы (df). Так как результат вычисления обычно не является integer, значение df округлится до ближайшего другого, чтобы получить критическое значение из таблицы t. Функция Excel T .Test использует вычисляемую величину df без округлений, так как можно вычислить значение для T.ТЕСТ с неинтегрированной df. Из-за этих разных подходов к определению степеней свободы результаты T.Тест и этот t-тест будут отличаться в случае неравных дисперсий.
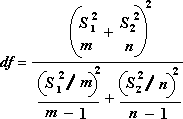
Z-тест. Средство анализа «Две выборки для середины» выполняет два примера z-теста для средств со известными дисперсиями. Этот инструмент используется для проверки гипотезы NULL о том, что между двумя значениями численности населения нет различий между односторонними или двухбокльными альтернативными гипотезами. Если дисперсии не известны, функция Z .Вместо этого следует использовать тест.
При использовании этого инструмента следует внимательно просматривать результат. «P(Z <= z) одностороннее» на самом деле есть P(Z >= ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. «P(Z <= z) двустороннее» на самом деле есть P(Z >= ABS(z) или Z <= -ABS(z)), вероятность z-значения, удаленного от 0 в том же направлении, что и наблюдаемое z-значение при одинаковых средних значениях генеральной совокупности. Двусторонний результат является односторонним результатом, умноженным на 2. Инструмент «z-тест» можно также применять для гипотезы об определенном ненулевом значении разницы между двумя средними генеральных совокупностей. Например, этот тест можно использовать для определения разницы выступлений на соревнованиях двух автомобилей разных марок.
Дополнительные сведения
Вы всегда можете задать вопрос специалисту Excel Tech Community или попросить помощи в сообществе Answers community.
См. также
Создание гистограммы в Excel 2016
Создание диаграммы Парето в Excel 2016
Загрузка средства анализа в Excel
Инженерные функции (справка)
Общие сведения о формулах в Excel
Рекомендации, позволяющие избежать появления неработающих формул
Поиск ошибок в формулах
Сочетания клавиш и горячие клавиши в Excel
Функции Excel (по алфавиту)
Функции Excel (по категориям)
Нужна дополнительная помощь?
Если вам по работе или учёбе приходится погружаться в океан цифр и искать в них подтверждение своих гипотез, вам определённо пригодятся эти техники работы в Microsoft Excel. Как их применять — показываем с помощью гифок.

Юлия Перминова
Тренер Учебного центра Softline с 2008 года.
1. Сводные таблицы
Базовый инструмент для работы с огромным количеством неструктурированных данных, из которых можно быстро сделать выводы и не возиться с фильтрацией и сортировкой вручную. Сводные таблицы можно создать с помощью нескольких действий и быстро настроить в зависимости от того, как именно вы хотите отобразить результаты.
Полезное дополнение. Вы также можете создавать сводные диаграммы на основе сводных таблиц, которые будут автоматически обновляться при их изменении. Это полезно, если вам, например, нужно регулярно создавать отчёты по одним и тем же параметрам.
Как работать
Исходные данные могут быть любыми: данные по продажам, отгрузкам, доставкам и так далее.
- Откройте файл с таблицей, данные которой надо проанализировать.
- Выделите диапазон данных для анализа.
- Перейдите на вкладку «Вставка» → «Таблица» → «Сводная таблица» (для macOS на вкладке «Данные» в группе «Анализ»).
- Должно появиться диалоговое окно «Создание сводной таблицы».
- Настройте отображение данных, которые есть у вас в таблице.
Перед нами таблица с неструктурированными данными. Мы можем их систематизировать и настроить отображение тех данных, которые есть у нас в таблице. «Сумму заказов» отправляем в «Значения», а «Продавцов», «Дату продажи» — в «Строки». По данным разных продавцов за разные годы тут же посчитались суммы. При необходимости можно развернуть каждый год, квартал или месяц — получим более детальную информацию за конкретный период.
Набор опций будет зависеть от количества столбцов. Например, у нас пять столбцов. Их нужно просто правильно расположить и выбрать, что мы хотим показать. Скажем, сумму.
Можно её детализировать, например, по странам. Переносим «Страны».
Можно посмотреть результаты по продавцам. Меняем «Страну» на «Продавцов». По продавцам результаты будут такие.
2. 3D-карты
Этот способ визуализации данных с географической привязкой позволяет анализировать данные, находить закономерности, имеющие региональное происхождение.
Полезное дополнение. Координаты нигде прописывать не нужно — достаточно лишь корректно указать географическое название в таблице.
Как работать
- Откройте файл с таблицей, данные которой нужно визуализировать. Например, с информацией по разным городам и странам.
- Подготовьте данные для отображения на карте: «Главная» → «Форматировать как таблицу».
- Выделите диапазон данных для анализа.
- На вкладке «Вставка» есть кнопка 3D-карта.
Точки на карте — это наши города. Но просто города нам не очень интересны — интересно увидеть информацию, привязанную к этим городам. Например, суммы, которые можно отобразить через высоту столбика. При наведении курсора на столбик показывается сумма.
Также достаточно информативной является круговая диаграмма по годам. Размер круга задаётся суммой.
3. Лист прогнозов
Зачастую в бизнес-процессах наблюдаются сезонные закономерности, которые необходимо учитывать при планировании. Лист прогноза — наиболее точный инструмент для прогнозирования в Excel, чем все функции, которые были до этого и есть сейчас. Его можно использовать для планирования деятельности коммерческих, финансовых, маркетинговых и других служб.
Полезное дополнение. Для расчёта прогноза потребуются данные за более ранние периоды. Точность прогнозирования зависит от количества данных по периодам — лучше не меньше, чем за год. Вам требуются одинаковые интервалы между точками данных (например, месяц или равное количество дней).
Как работать
- Откройте таблицу с данными за период и соответствующими ему показателями, например, от года.
- Выделите два ряда данных.
- На вкладке «Данные» в группе нажмите кнопку «Лист прогноза».
- В окне «Создание листа прогноза» выберите график или гистограмму для визуального представления прогноза.
- Выберите дату окончания прогноза.
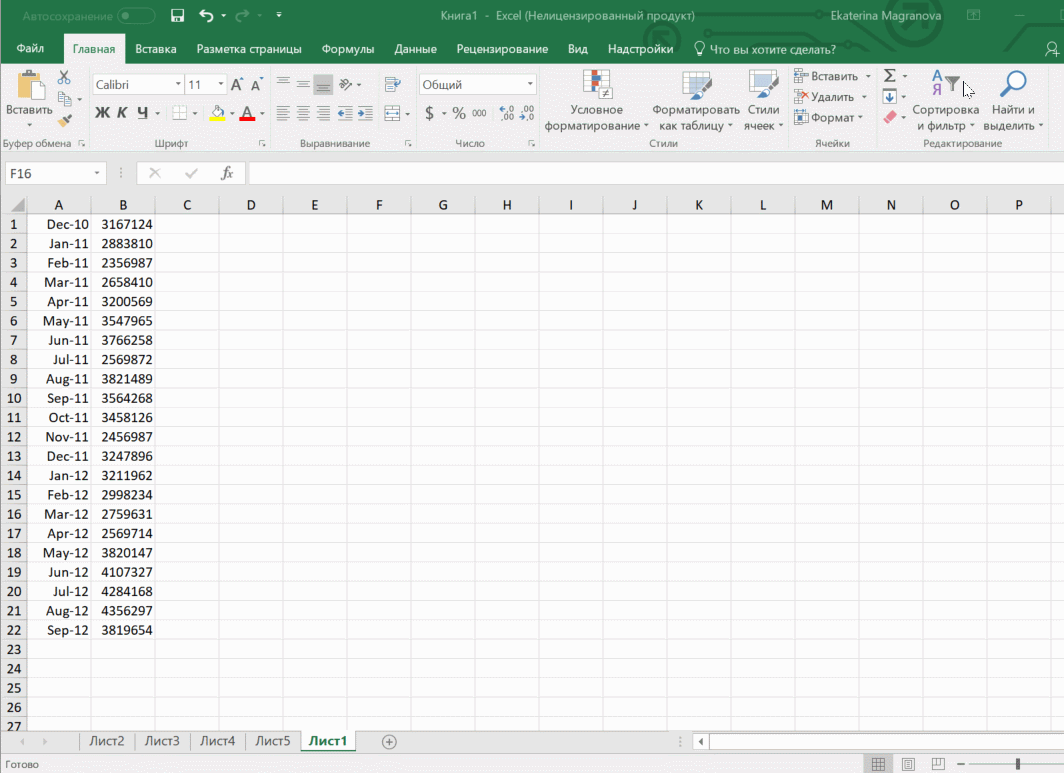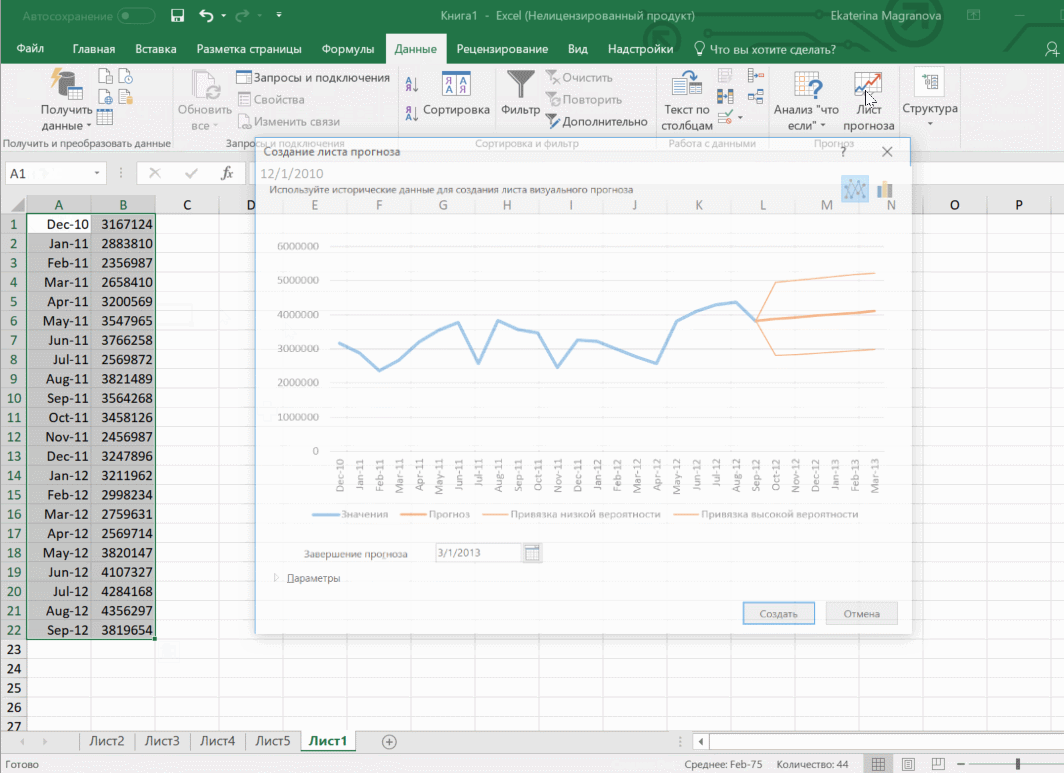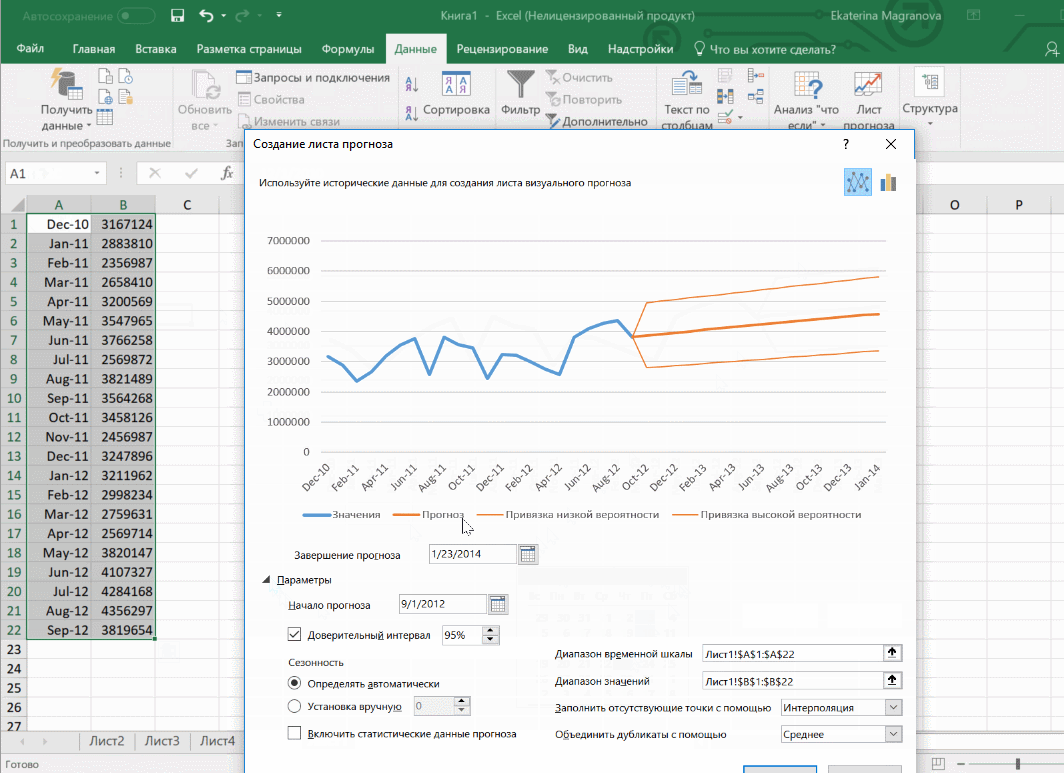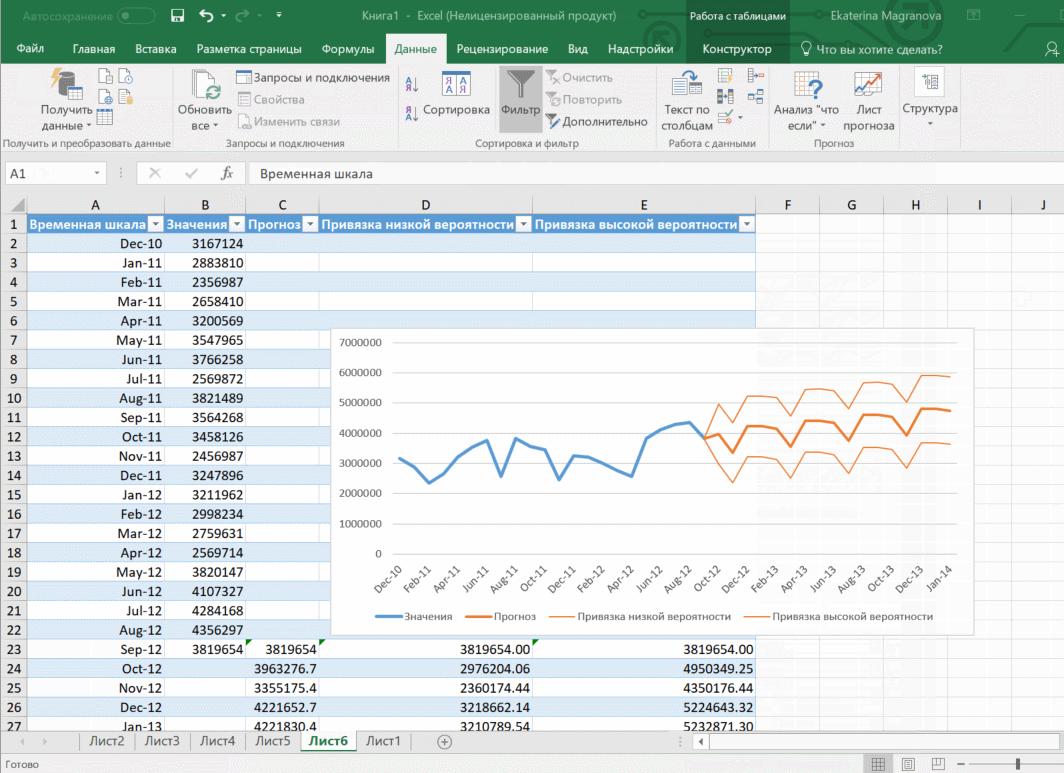
В примере ниже у нас есть данные за 2011, 2012 и 2013 годы. Важно указывать не числа, а именно временные периоды (то есть не 5 марта 2013 года, а март 2013-го).
Для прогноза на 2014 год вам потребуются два ряда данных: даты и соответствующие им значения показателей. Выделяем оба ряда данных.
На вкладке «Данные» в группе «Прогноз» нажимаем на «Лист прогноза». В появившемся окне «Создание листа прогноза» выбираем формат представления прогноза — график или гистограмму. В поле «Завершение прогноза» выбираем дату окончания, а затем нажимаем кнопку «Создать». Оранжевая линия — это и есть прогноз.
4. Быстрый анализ
Эта функциональность, пожалуй, первый шаг к тому, что можно назвать бизнес-анализом. Приятно, что эта функциональность реализована наиболее дружественным по отношению к пользователю способом: желаемый результат достигается буквально в несколько кликов. Ничего не нужно считать, не надо записывать никаких формул. Достаточно выделить нужный диапазон и выбрать, какой результат вы хотите получить.
Полезное дополнение. Мгновенно можно создавать различные типы диаграмм или спарклайны (микрографики прямо в ячейке).
Как работать
- Откройте таблицу с данными для анализа.
- Выделите нужный для анализа диапазон.
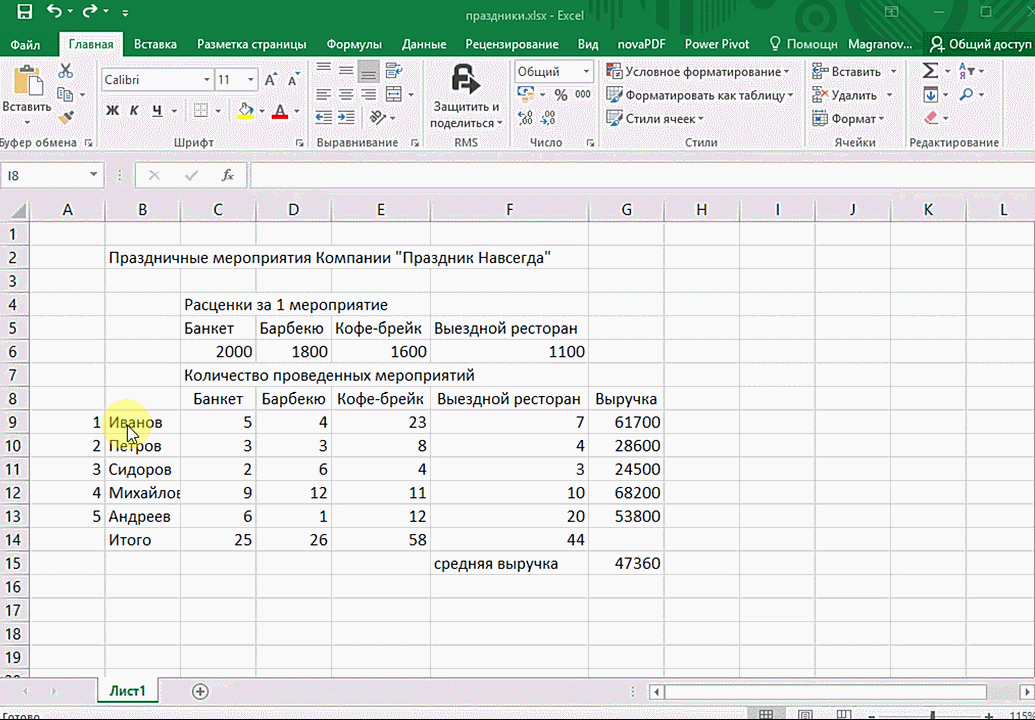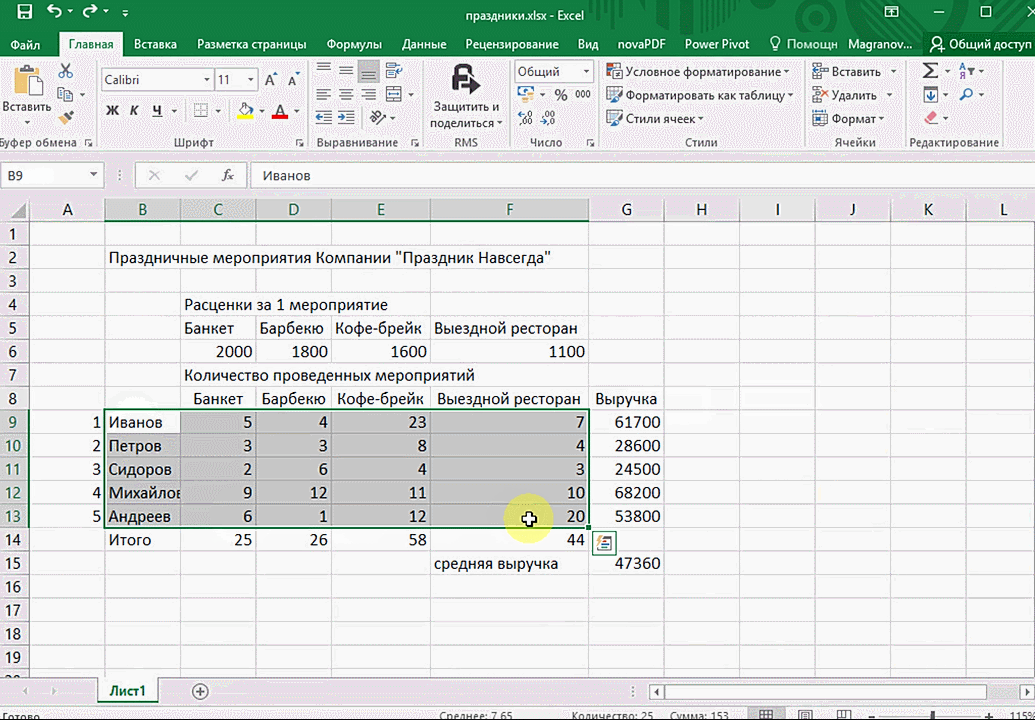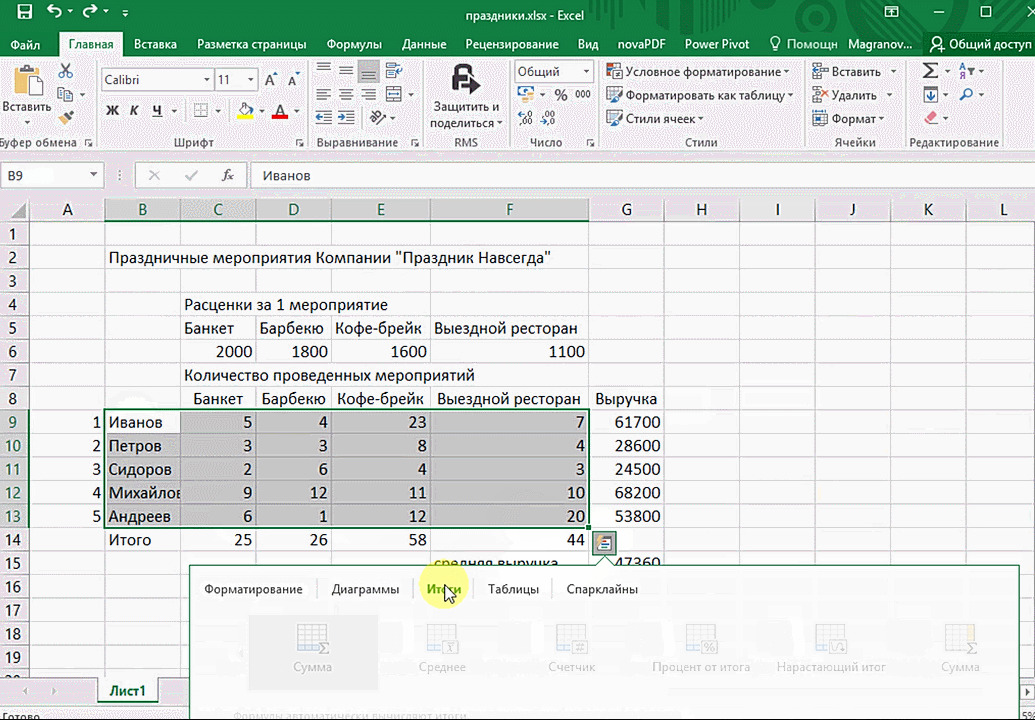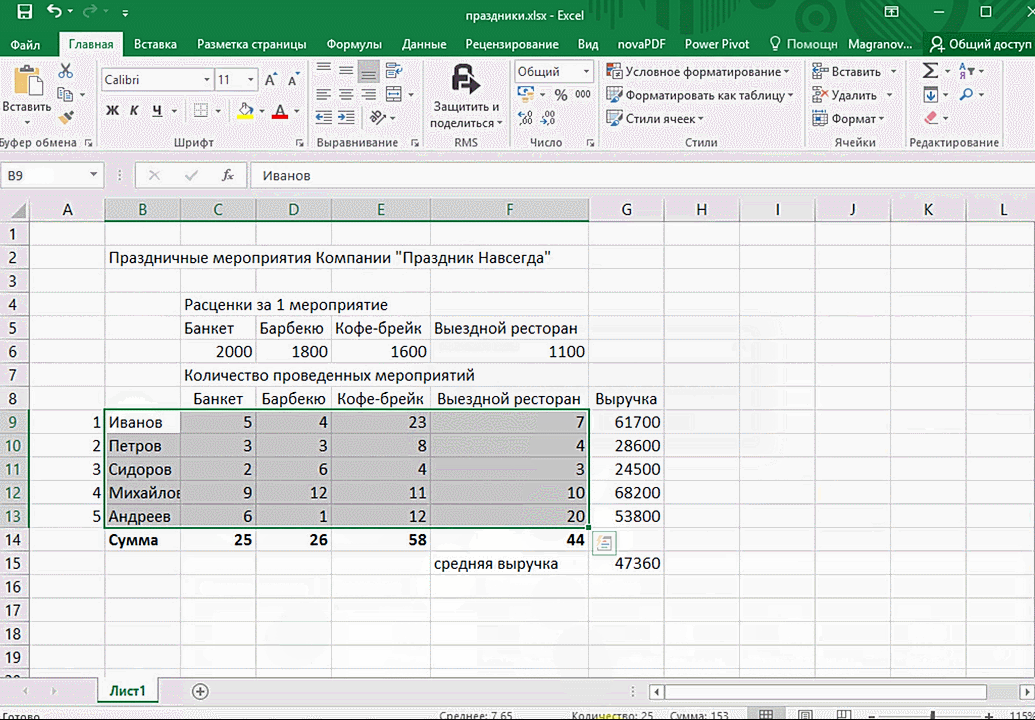
- При выделении диапазона внизу всегда появляется кнопка «Быстрый анализ». Она сразу предлагает совершить с данными несколько возможных действий. Например, найти итоги. Мы можем узнать суммы, они проставляются внизу.
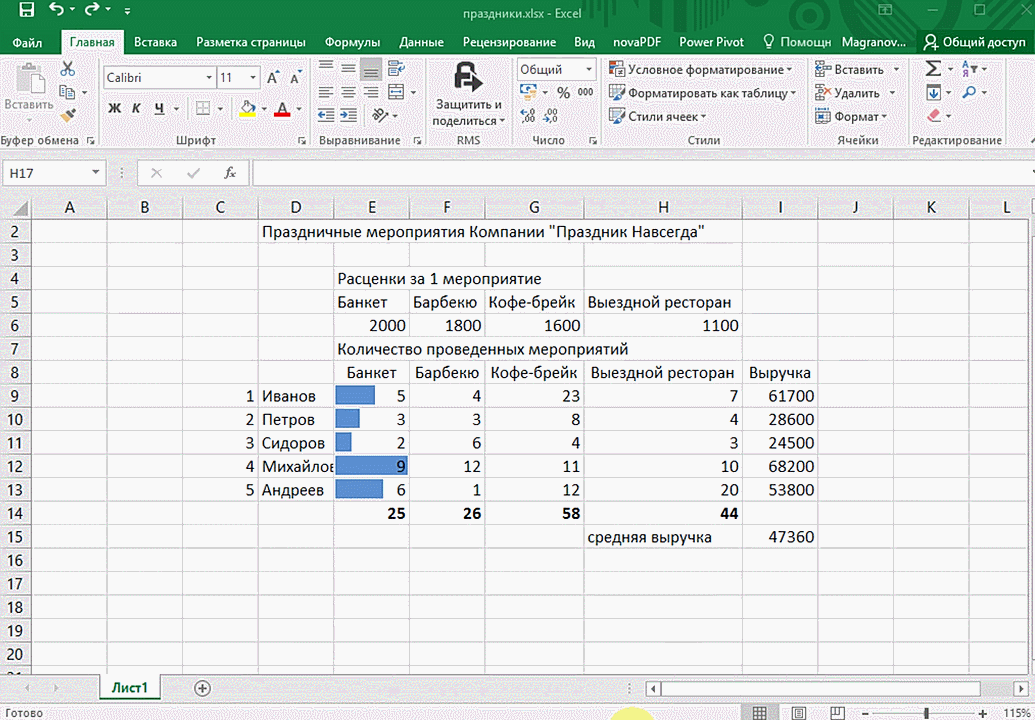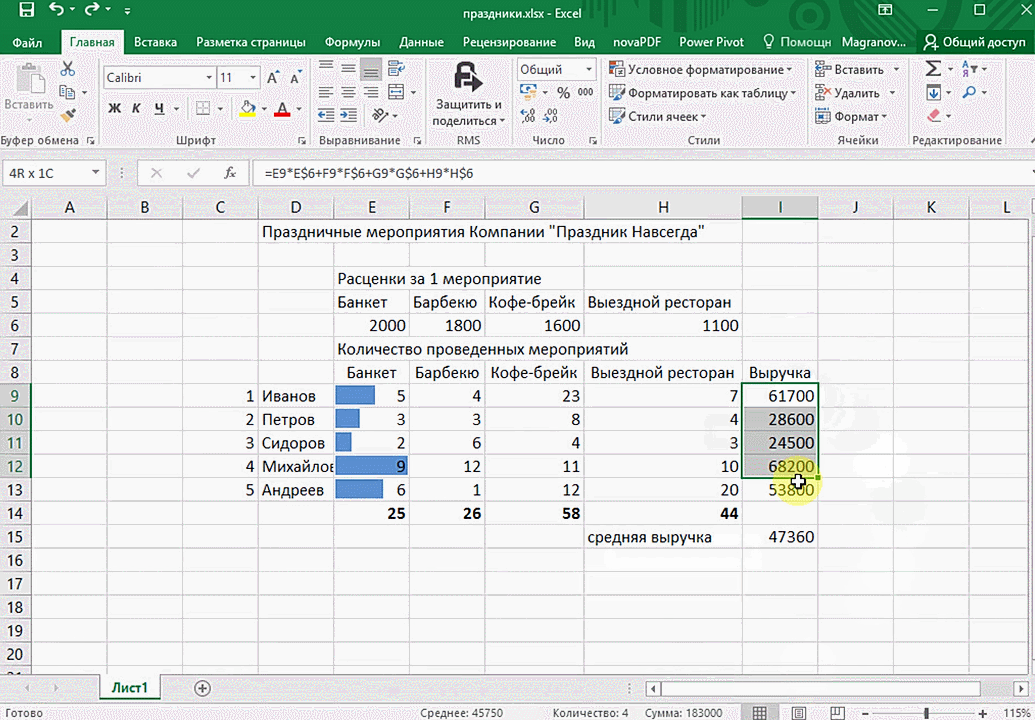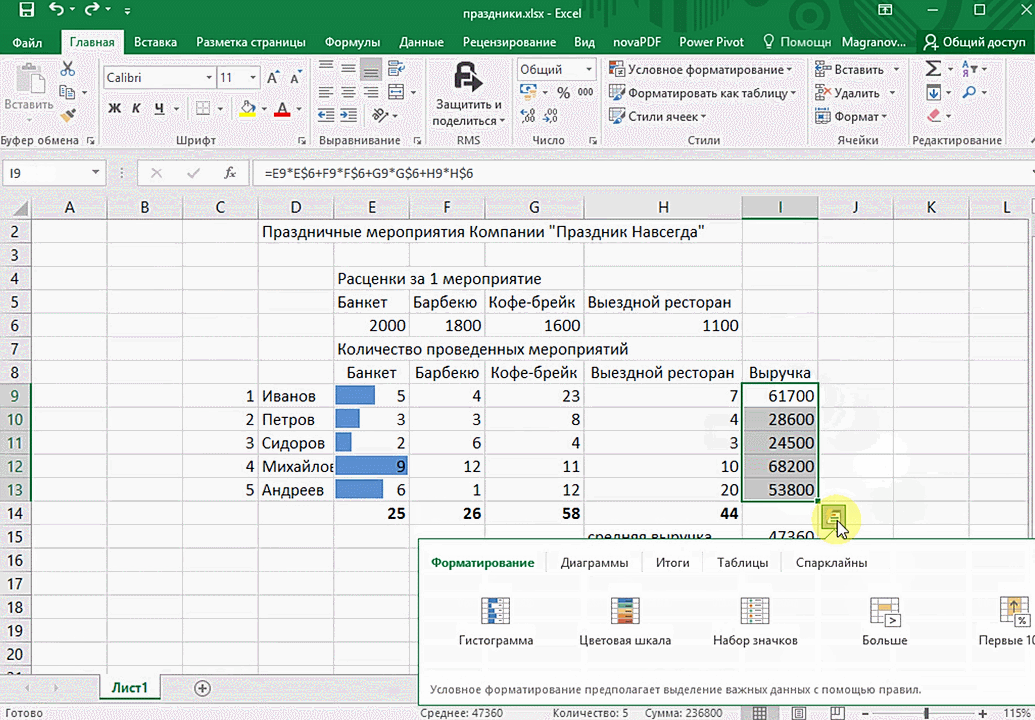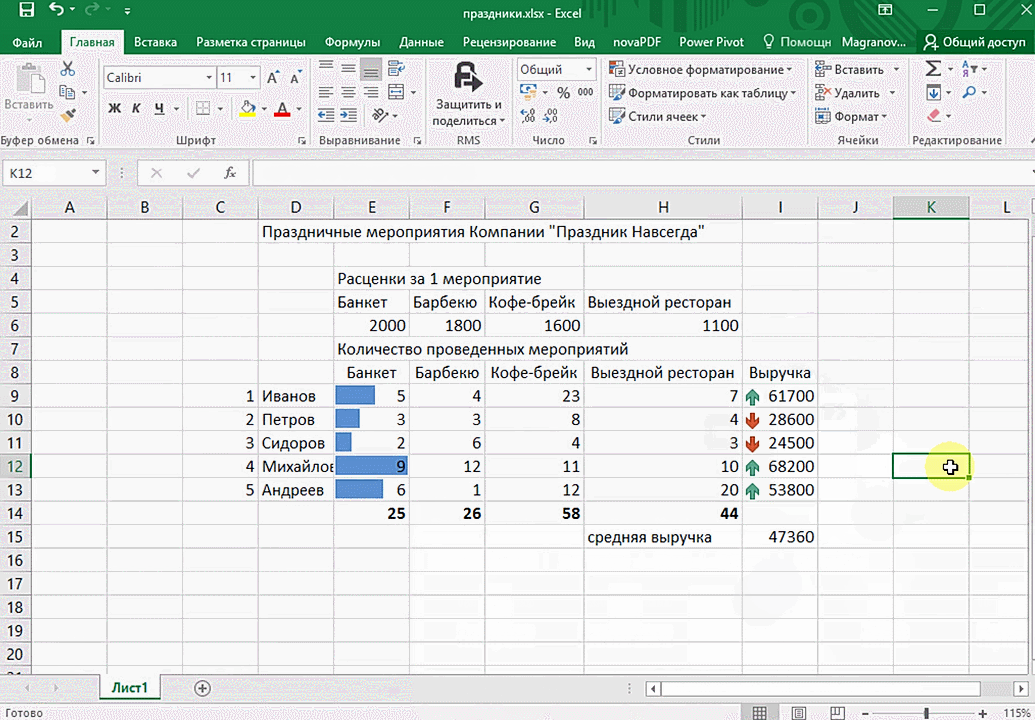
В быстром анализе также есть несколько вариантов форматирования. Посмотреть, какие значения больше, а какие меньше, можно в самих ячейках гистограммы.
Также можно проставить в ячейках разноцветные значки: зелёные — наибольшие значения, красные — наименьшие.
Надеемся, что эти приёмы помогут ускорить работу с анализом данных в Microsoft Excel и быстрее покорить вершины этого сложного, но такого полезного с точки зрения работы с цифрами приложения.
Читайте также:
- 10 быстрых трюков с Excel →
- 20 секретов Excel, которые помогут упростить работу →
- 10 шаблонов Excel, которые будут полезны в повседневной жизни →
Excel – одна из лучших программ для аналитика данных. А почти каждому человеку на том или ином этапе жизни приходилось иметь дело с цифрами и текстовыми данными и обрабатывать их в условиях жестких дедлайнов. Если вам и сейчас нужно это делать, то мы опишем техники, которые помогут существенно улучшить вам жизнь. А чтобы было более наглядно, покажем, как их воплощать, с помощью анимаций.
Содержание
- Анализ данных через сводные таблицы Excel
- Как работать со сводными таблицами
- Анализ данных с помощью 3D-карт
- Как работать с 3D-картами в Excel
- Лист прогноза в Excel
- Как работать с листом прогноза
- Быстрый анализ в Excel
- Как работать
Анализ данных через сводные таблицы Excel
Сводные таблицы – один из самых простых способов автоматизировать обработку информации. Он позволяет свести в кучу огромный массив данных, которые абсолютно не структурированы. Если его использовать, можно почти навсегда забыть о том, что такое фильтр и ручная сортировка. А чтобы их создать, достаточно нажать буквально пару кнопок и внести несколько несложных параметров в зависимости от того, какой способ представления результатов нужен конкретно вам в определенной ситуации.
Существует множество способов автоматизации анализа данных в Excel. Это как встроенные инструменты, так и дополнения, которые можно скачать на просторах интернета. Также есть дополнение «Пакет анализа», которое было разработано компанией Майкрософт. Она имеет все необходимые возможности, чтобы вы могли получать все необходимые результаты в одном файле Excel.
Пакет анализа данных, разработанный Майкрософт, можно использовать исключительно на едином листе в одну единицу времени. Если он будет обрабатывать информацию, расположенную на нескольких, то итоговая информация будет отображаться исключительно на одном. В других же будут показываться диапазоны без какой-либо значений, в которых есть исключительно форматы. Чтобы осуществить проанализировать информацию на нескольких листах, нужно использовать этот инструмент по отдельности. Это очень большой модуль, который поддерживает огромное количество возможностей, в частности, позволяет выполнять следующие типы обработки:
- Дисперсионный анализ.
- Корреляционный анализ.
- Ковариация.
- Вычисление скользящего среднего. Очень популярный метод в статистике и в трейдинге.
- Получать случайные числа.
- Выполнять операции с выборкой.
Эта надстройка не активирована по умолчанию, но входит в стандартный пакет. Чтобы ею воспользоваться, необходимо ее включить. Для этого сделайте следующие шаги:
- Перейдите в меню «Файл», и там найдите кнопку «Параметры». После этого перейдите в «Надстройки». Если же вы установили 2007 версию Эксель, то нужно нажать на кнопку «Параметры Excel», которая находится в меню Office.
- Далее появляется всплывающее меню, озаглавленное словом «Управление». Там находим пункт «Надстройки Excel», нажимаем на него, а потом – на кнопку «Перейти». Если же вы используете компьютер Apple, то достаточно открыть вкладку «Средства» в меню, а потом в раскрывающемся перечне найти пункт «Надстройки для Excel».
- В том диалоге, который появился после этого, нужно поставить галочку возле пункта «Пакет анализа», после чего подтвердить свои действия, нажав кнопку «ОК».
В некоторых ситуациях может оказаться так, что этого дополнения найти не удалось. В этом случае его не будет в перечне аддонов. Для этого надо нажать на кнопку «Обзор». Может также появиться информация о том, что пакет полностью отсутствует на этом компьютере. В этом случае необходимо его установить. Для этого нужно нажать на кнопку «Да».
Перед тем, как включить пакет анализа, необходимо сначала активировать VBA. Для этого его нужно загрузить таким же способом, как и саму надстройку.
Как работать со сводными таблицами
Первоначальная информация может быть какой-угодно. Это могут быть сведения о продажах, доставке, отгрузках продукции и так далее. Независимо от этого, последовательность шагов будет всегда одинаковой:
- Откройте файл, в котором содержится таблица.
- Выделите диапазон ячеек, которые мы будем анализировать с помощью сводной таблицы.
- Откройте вкладку «Вставка, и там надо найти группу «Таблицы», где есть кнопка «Сводная таблица». Если же используется компьютер под операционной системой Mac OS, то нужно открыть вкладку «Данные», и эта кнопка будет находиться во вкладке «Анализ».
- После этого откроется диалог с заголовком «Создание сводной таблицы».
- Затем выставите такое отображение данных, которое соответствует выделенному диапазону.
Мы открыли таблицу, информация в которой никоим образом не структурирована. Чтобы это сделать, можно воспользоваться настройками полей сводной таблицы в правой стороне экрана. Например, отправим в поле «Значения» «Сумму заказов», а информацию про продавцов и дату продажи – в строки таблицы. Исходя из данных, которые содержатся в этой таблице, автоматически определились суммы. Если есть необходимость, можно открыть информацию по каждому году, кварталу или месяцу. Это позволит получить детальную информацию, которая надо в конкретный момент.
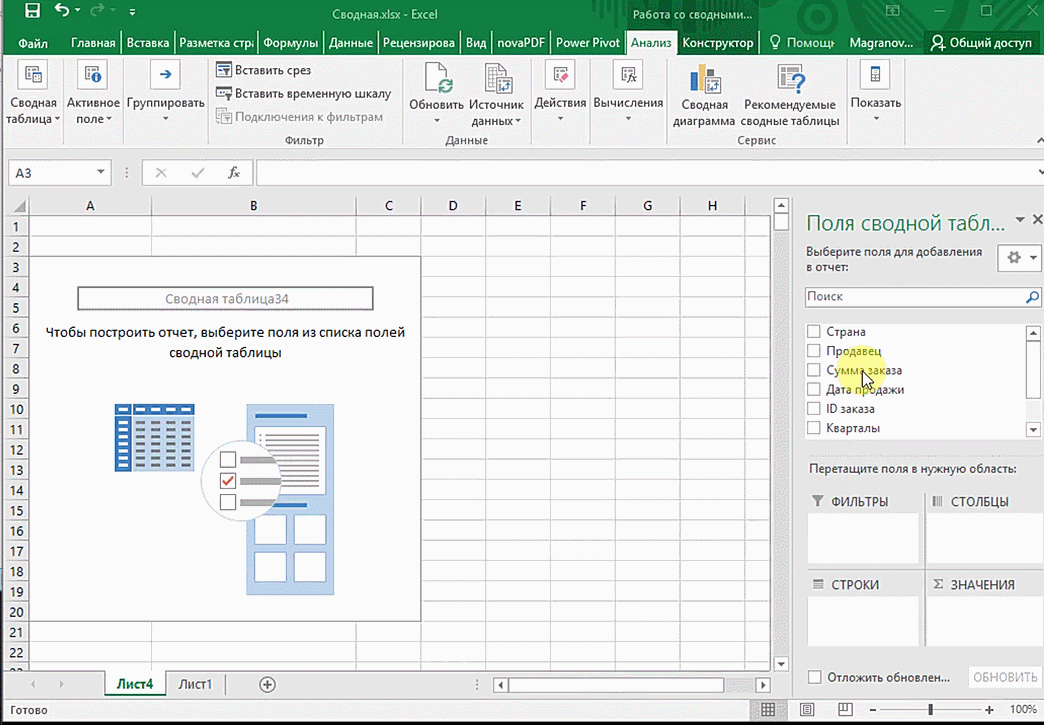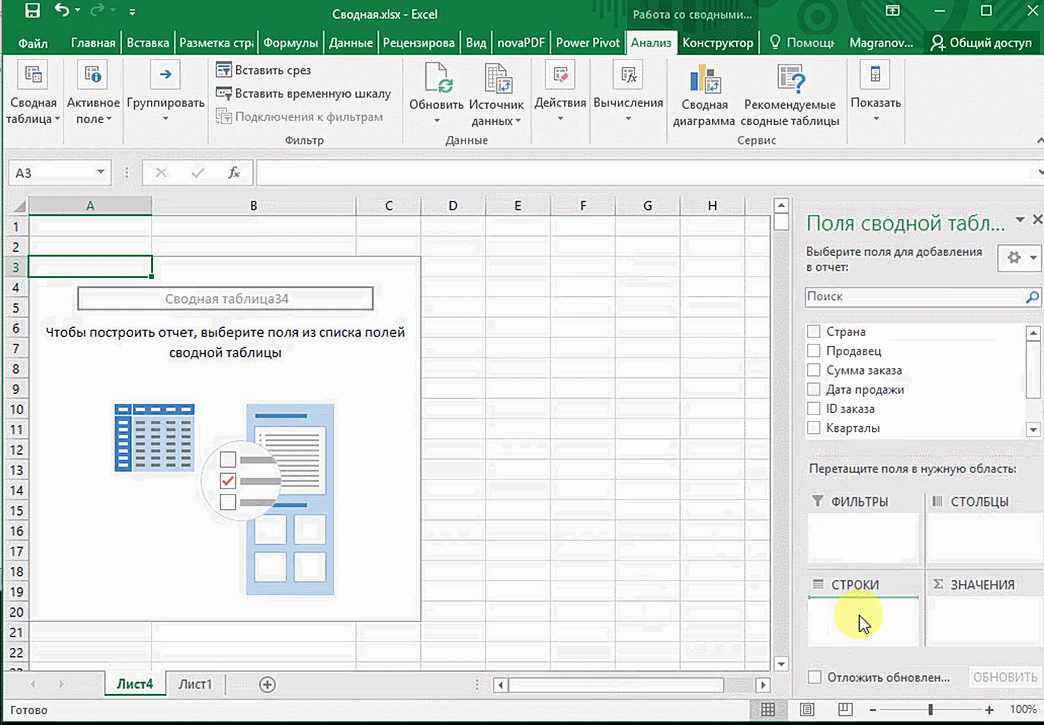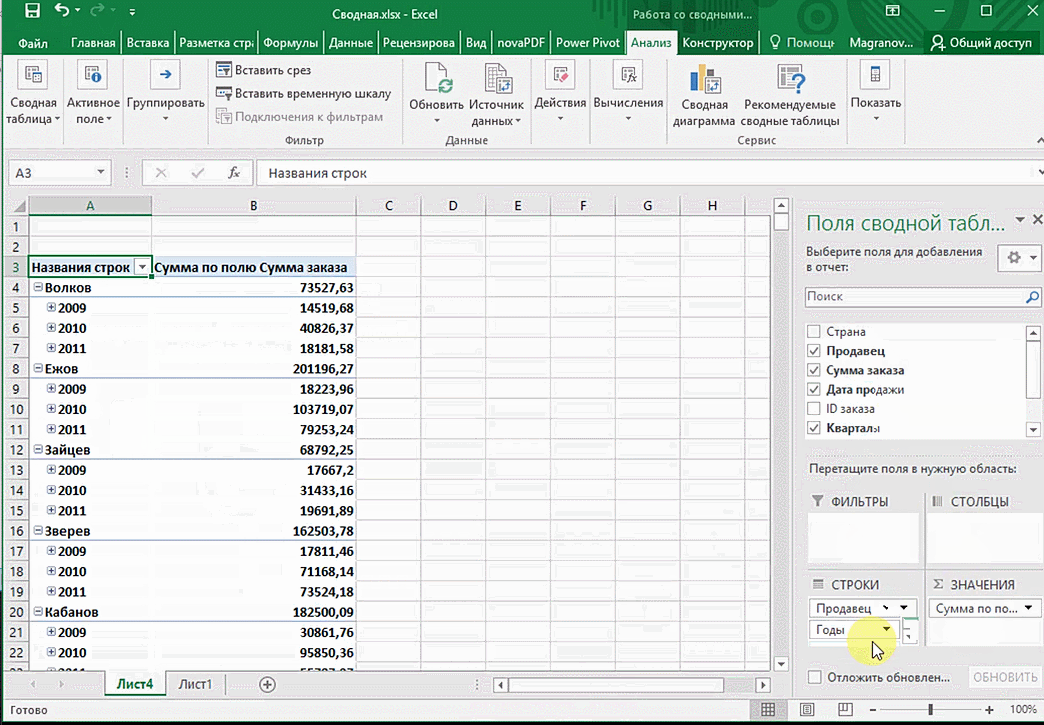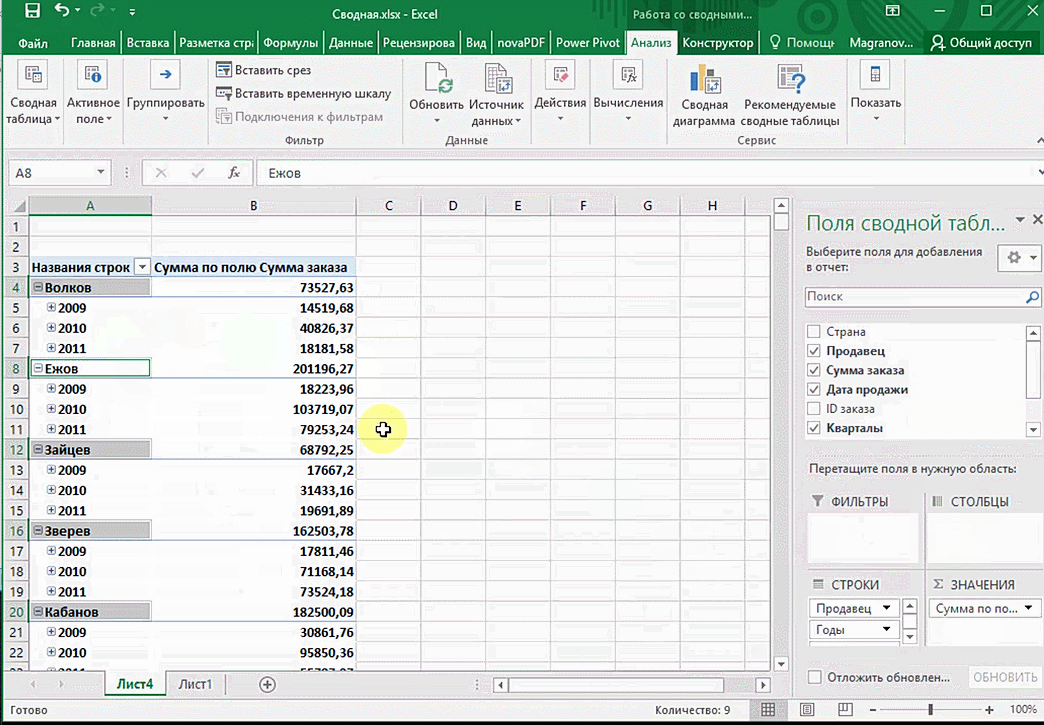
От того, сколько колонок есть, будет отличаться и набор имеющихся параметров. Например, общее число столбцов – 5. И нам надо просто разместить и выбрать их верным образом, а показать сумму. В таком случае выполняем действия, показанные на этой анимации.
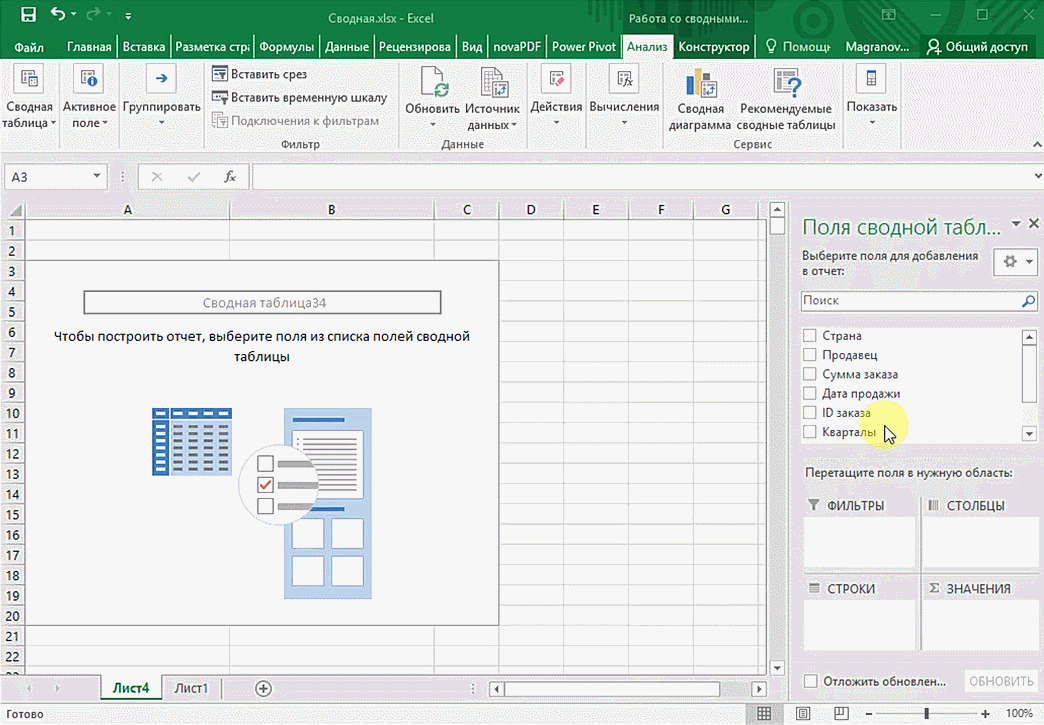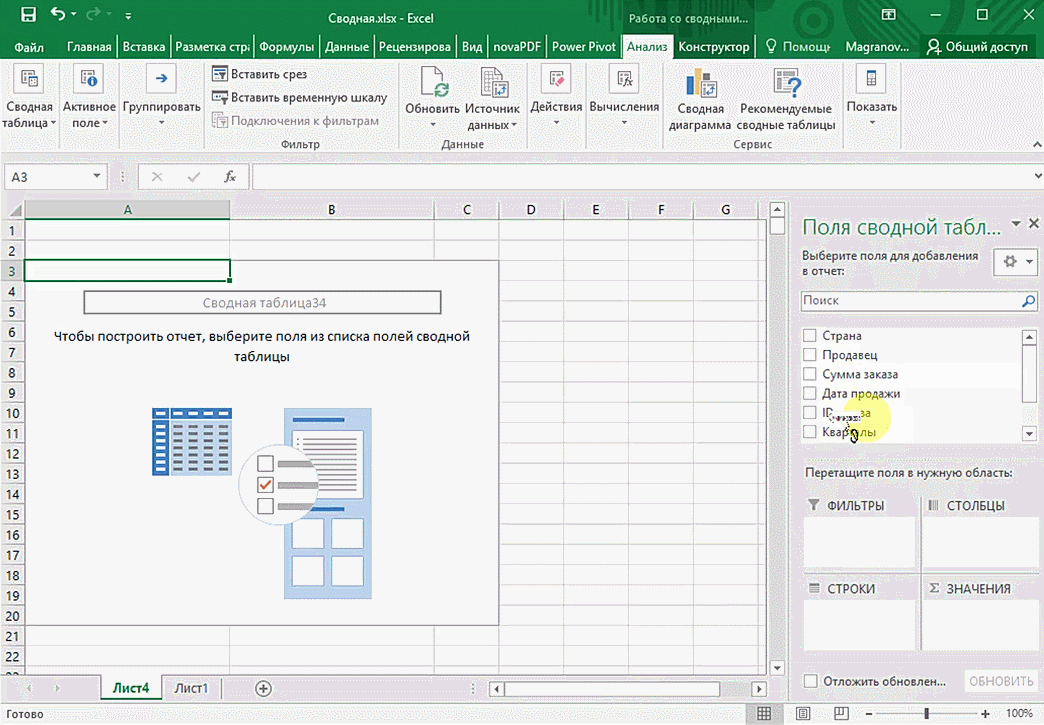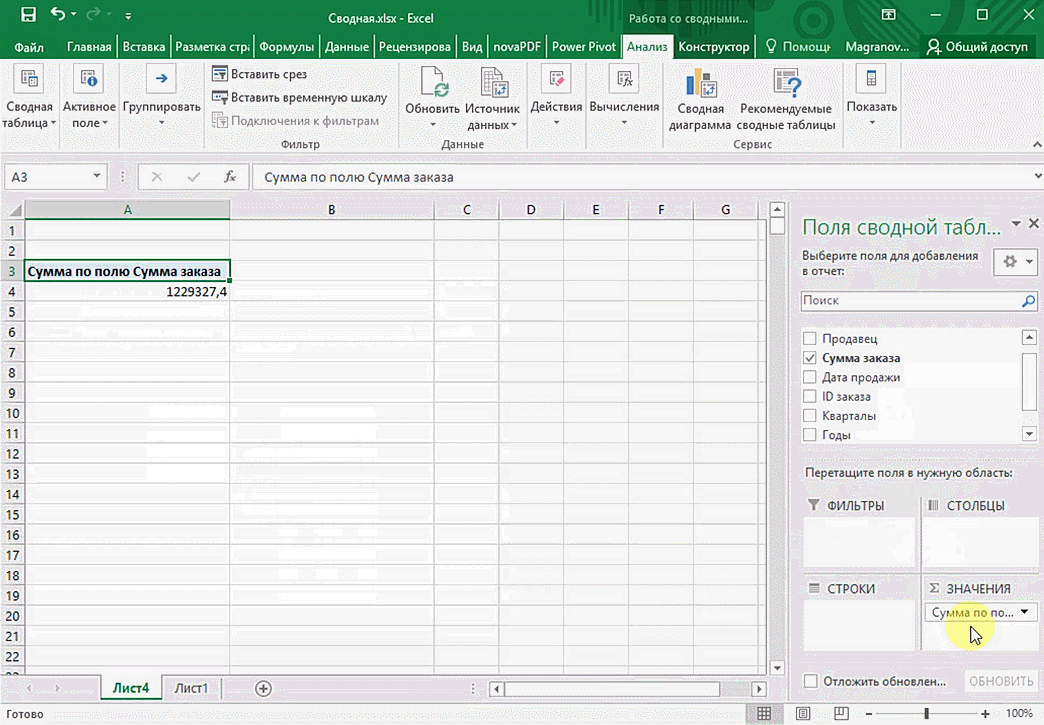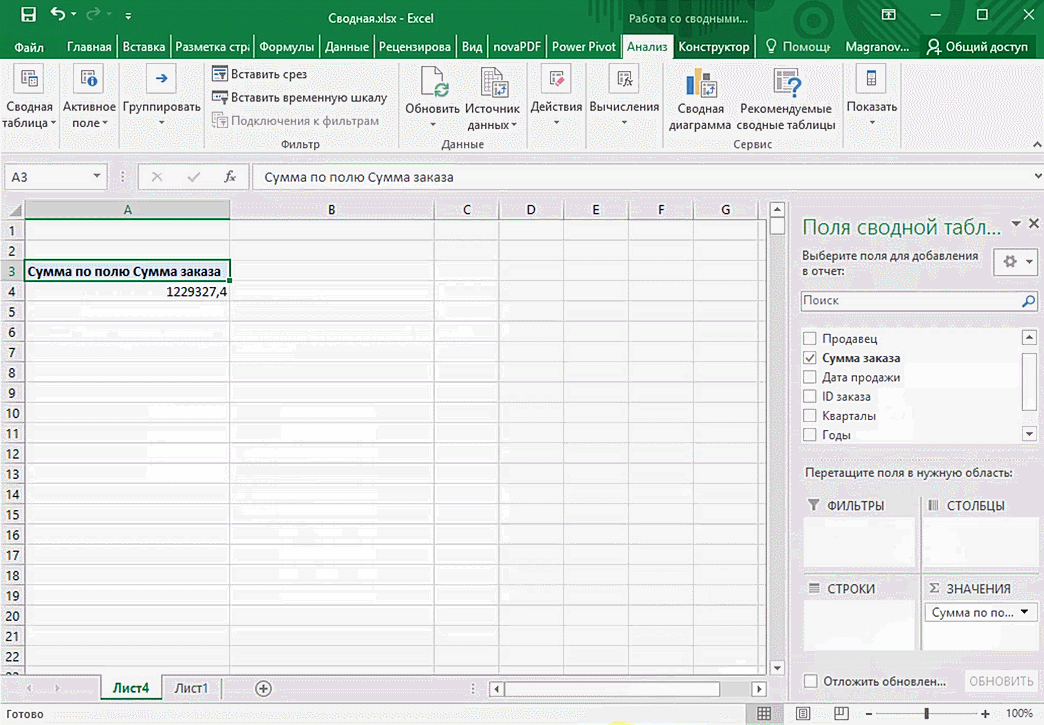
Можно сводную таблицу конкретизировать, указав, например, страну. Для этого мы включаем пункт «Страна».
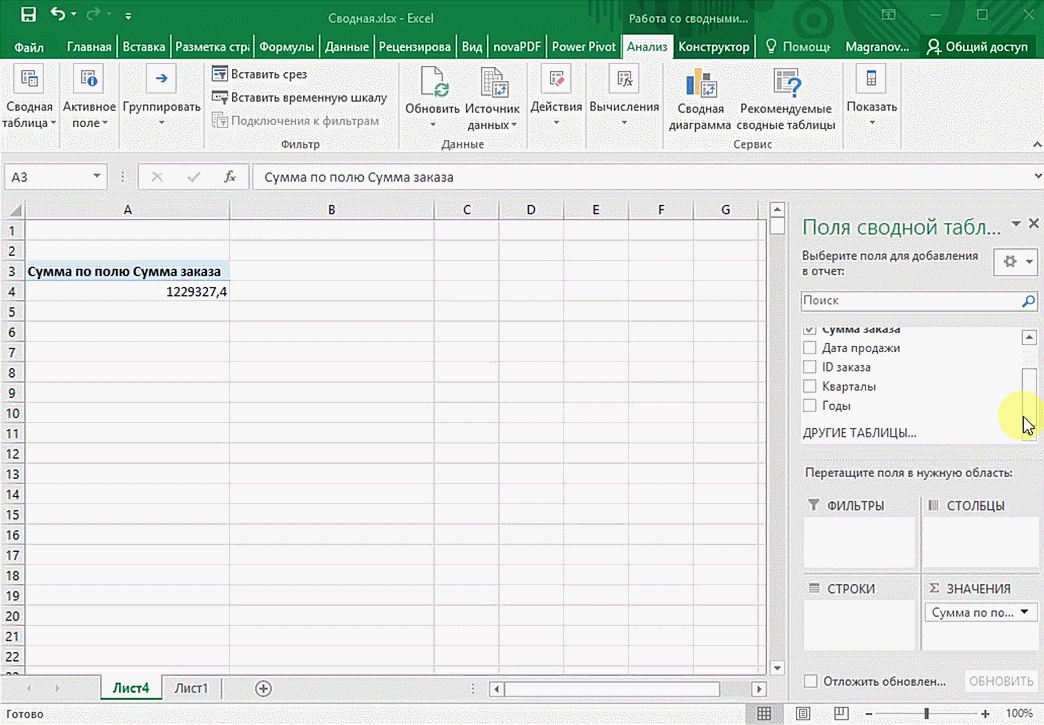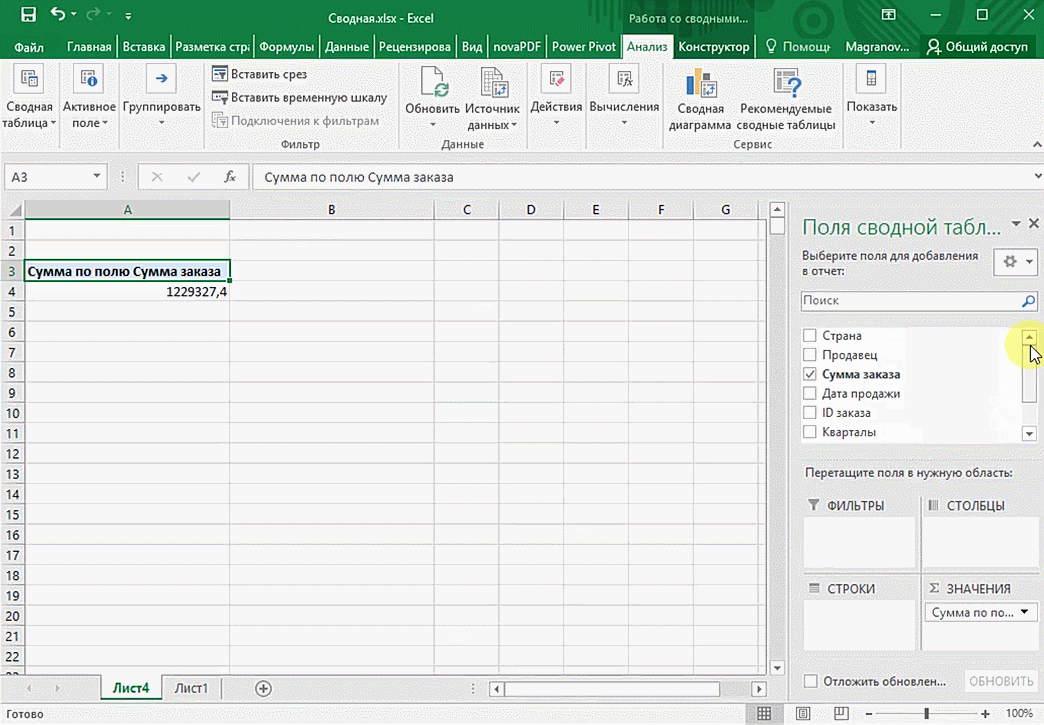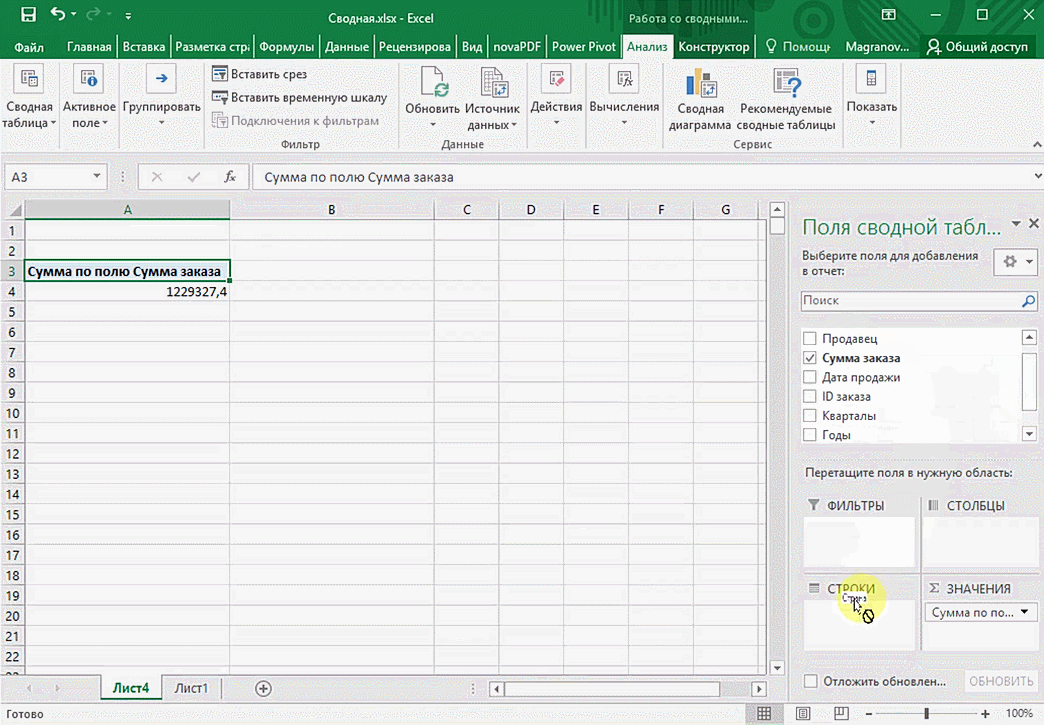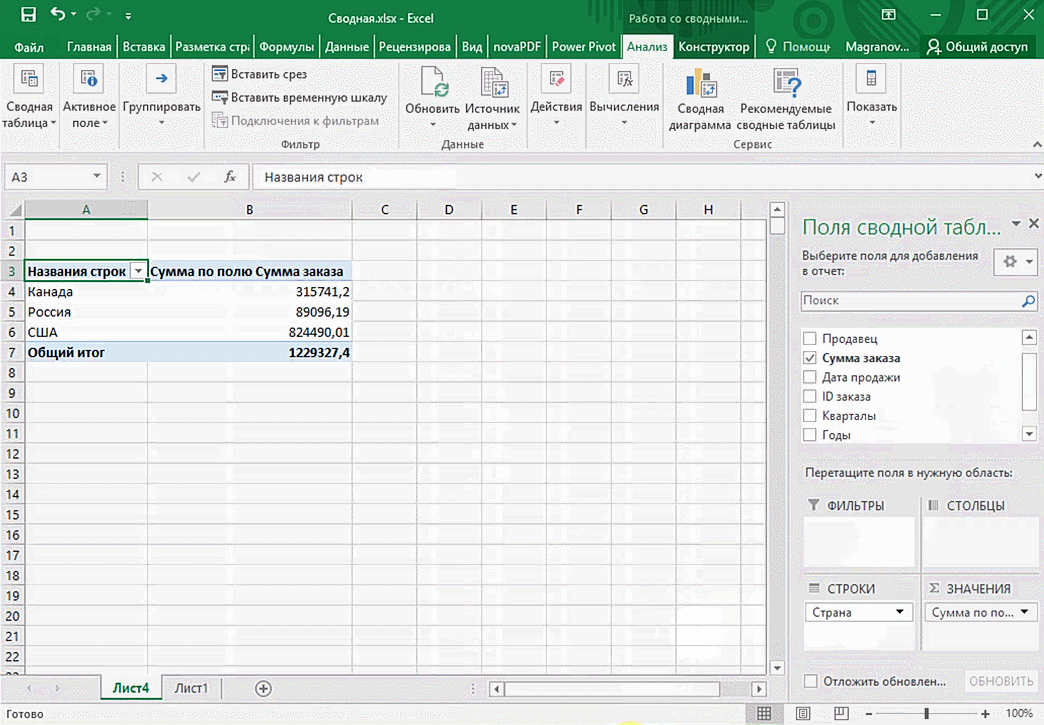
Можно также посмотреть информацию про продавцов. Для этого мы заменяем колонку «Страна» на «Продавец». Результат получится следующий.
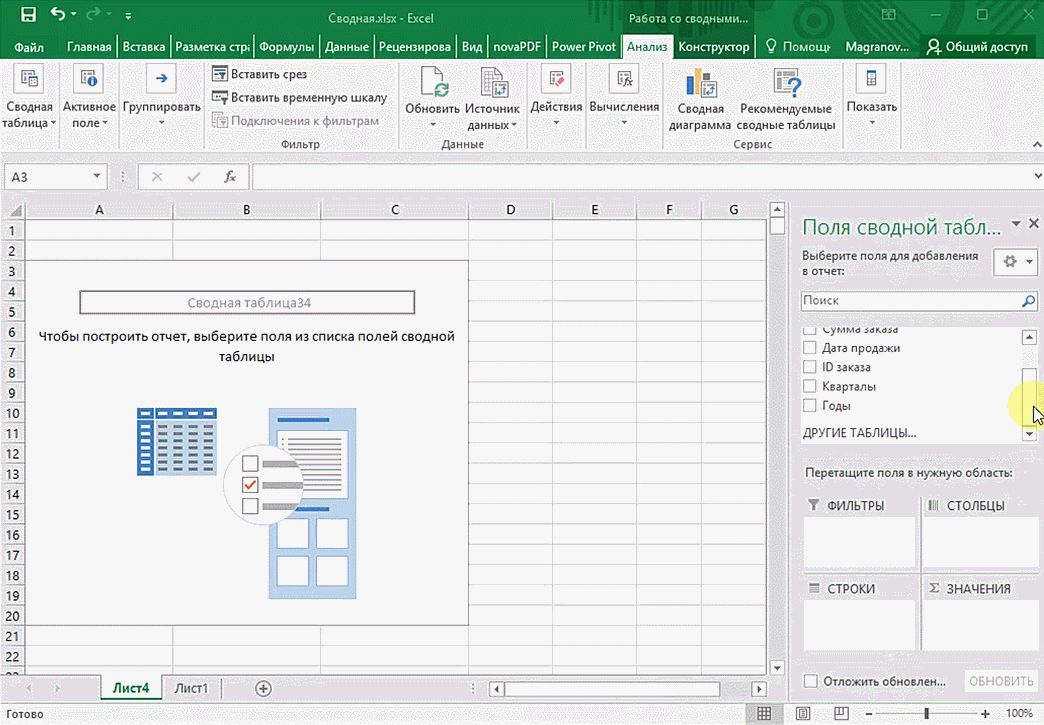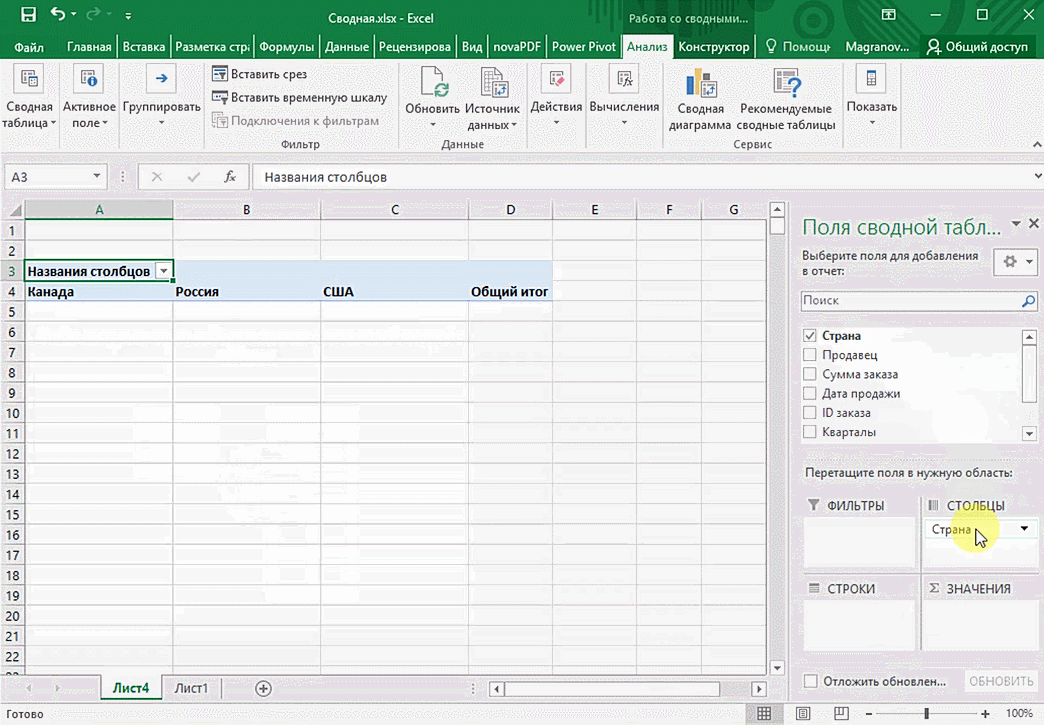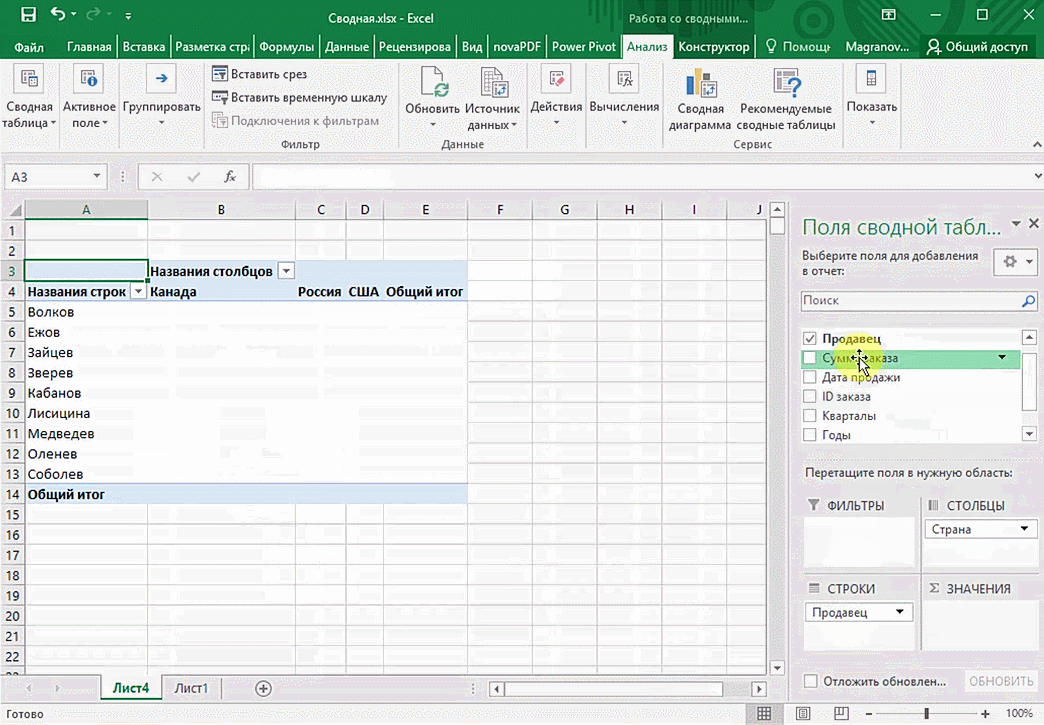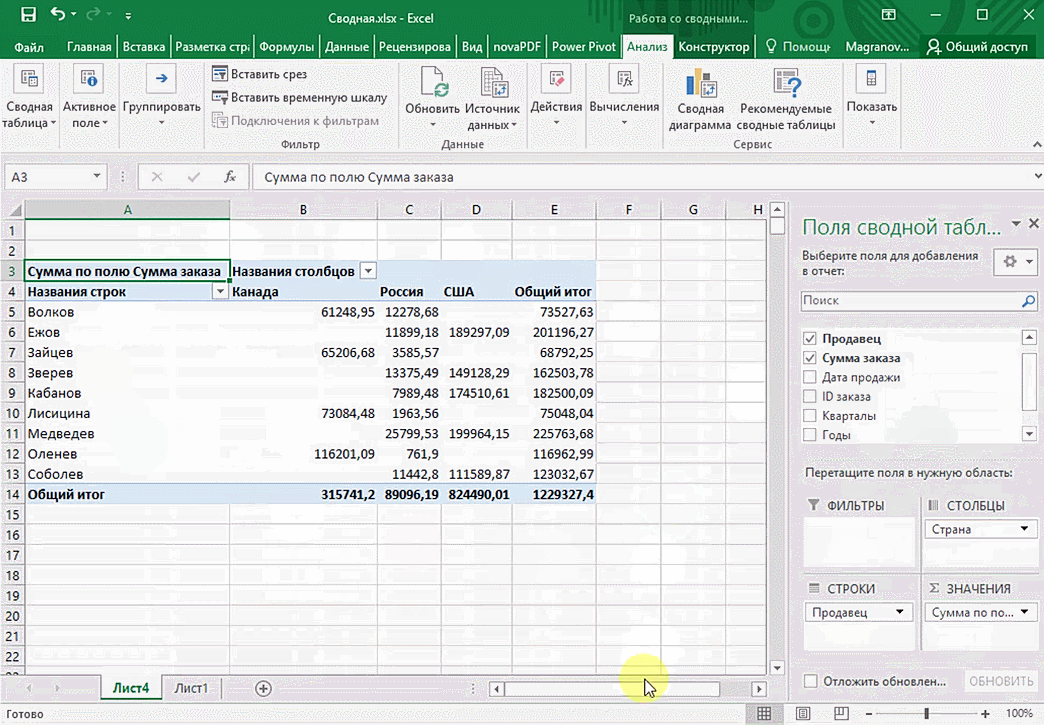
Анализ данных с помощью 3D-карт
Данный метод визуального представления с географической привязкой дает возможность искать закономерности, привязанные к регионам, а также анализировать информацию этого типа.
Преимущество этого способа в том, что нет необходимости отдельно прописывать координаты. Необходимо просто правильно написать географическое положение в таблице.
Как работать с 3D-картами в Excel
Последовательность действий, которую вам необходимо выполнить, чтобы работать с 3Д-картами, следующая:
- Откройте файл, в котором есть интересующий диапазон данных. Например, таблица, где есть колонка «Страна» или «Город».
- Информацию, которая будет показываться на карте, нужно сначала отформатировать, как таблицу. Для этого надо найти соответствующий пункт на вкладке «Главная».
- Выделите те ячейки, которые будут анализироваться.
- После этого переходим на вкладку «Вставка», и там находим кнопку «3Д-карта».
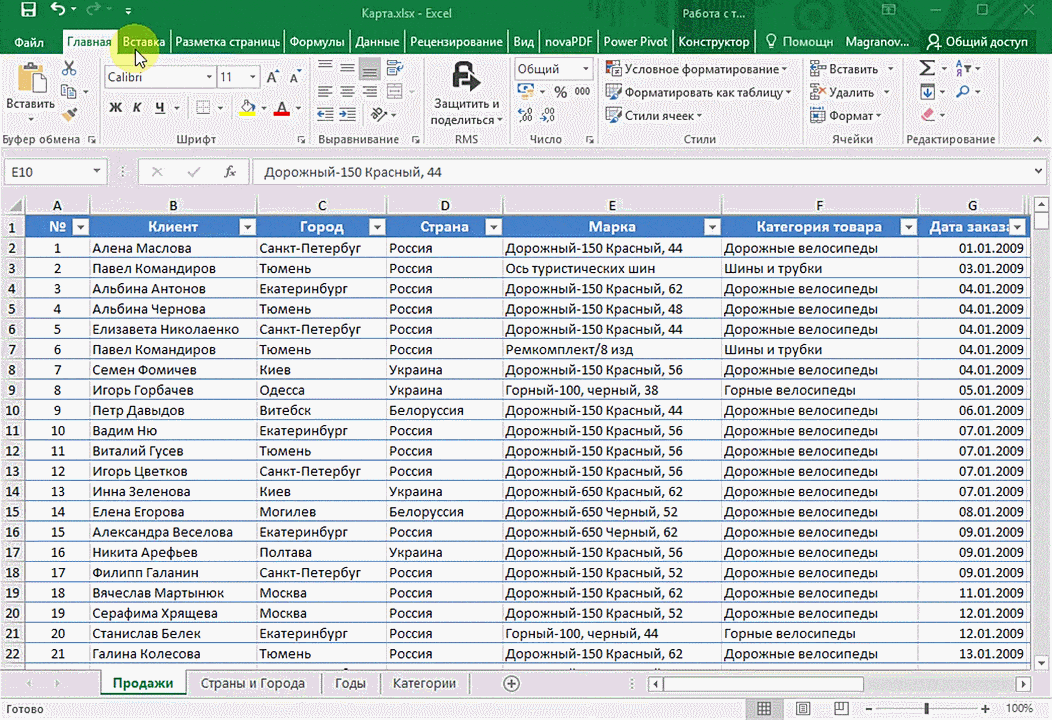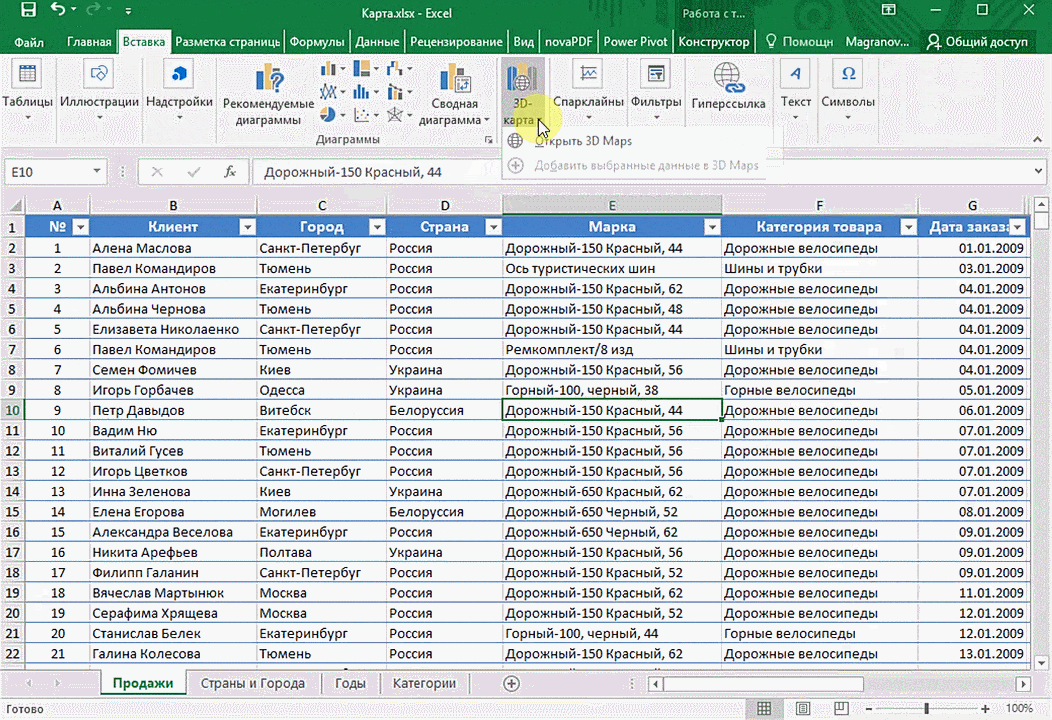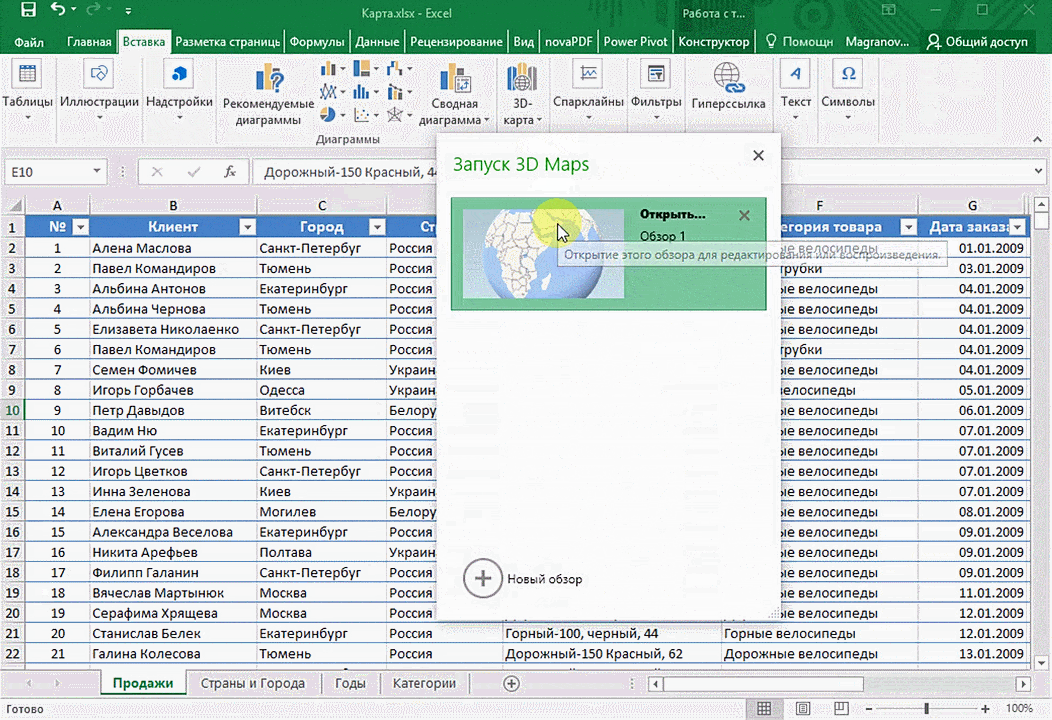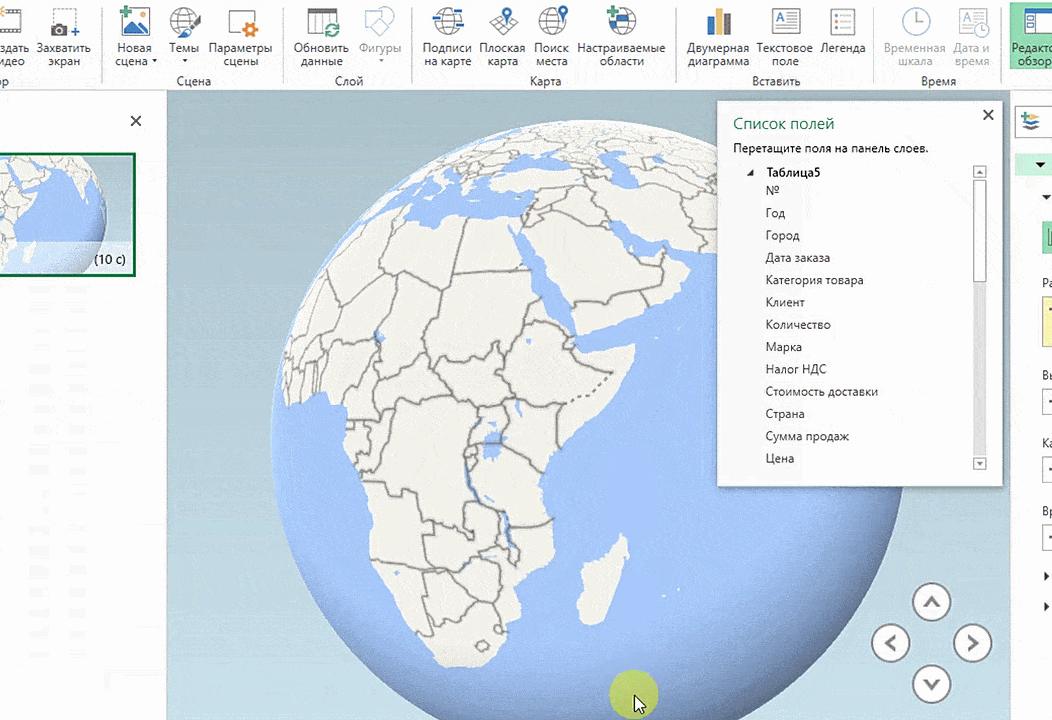
Затем показывается наша карта, где города в таблице представлены в виде точек. Но нам не особо нужно просто наличие информации о населенных пунктах на карте. Нам гораздо важнее видеть ту информацию, которая привязана к ним. Например, те суммы, которые можно показать, как высоту столбика. После того, как мы выполним действия, указанные на этой анимации, при наведении курсора на соответствующий столбик будут отображаться привязанные к нему данные.
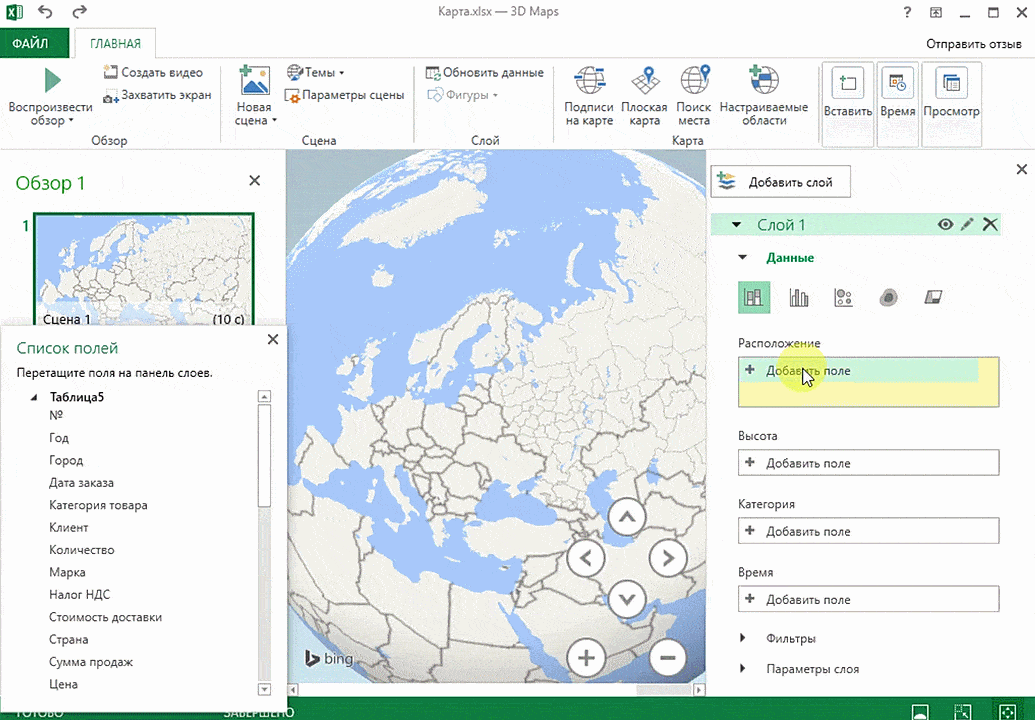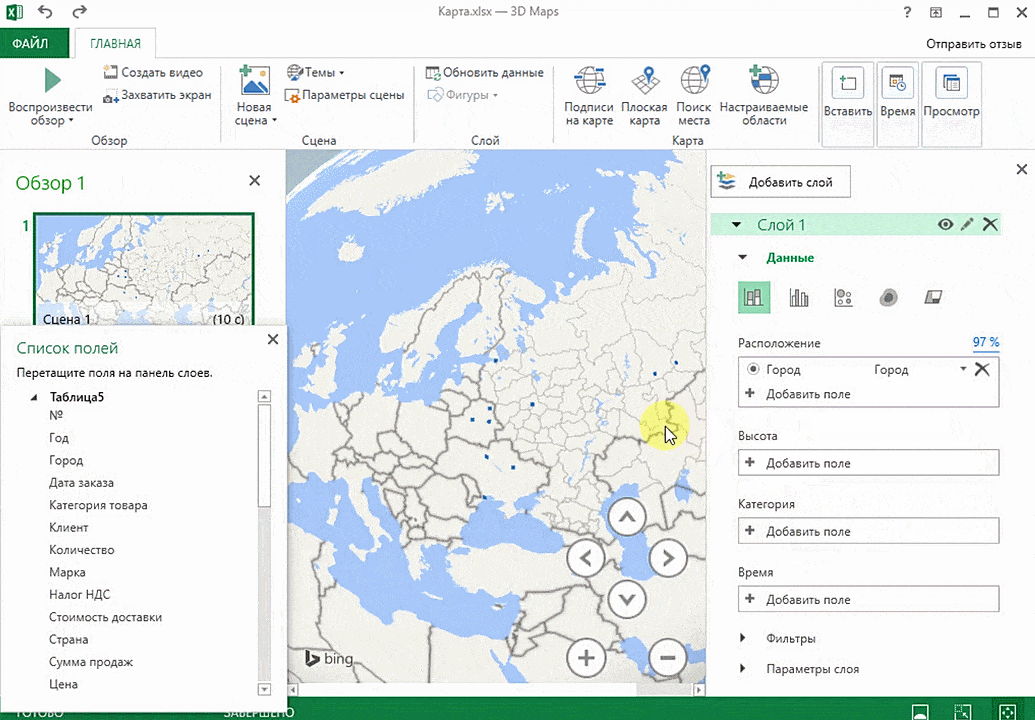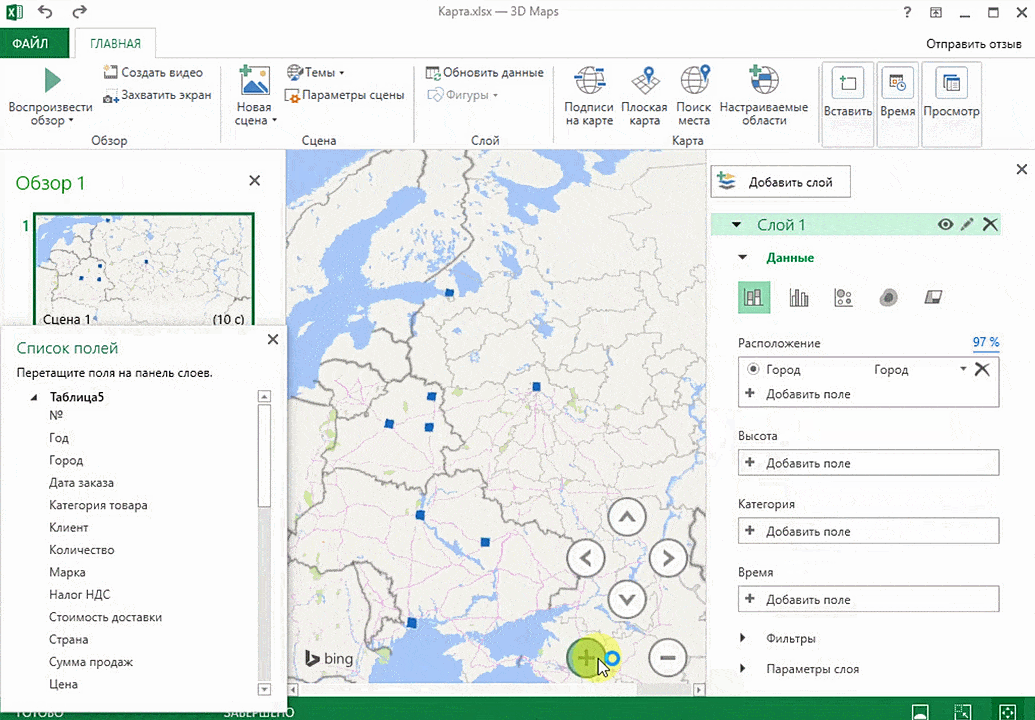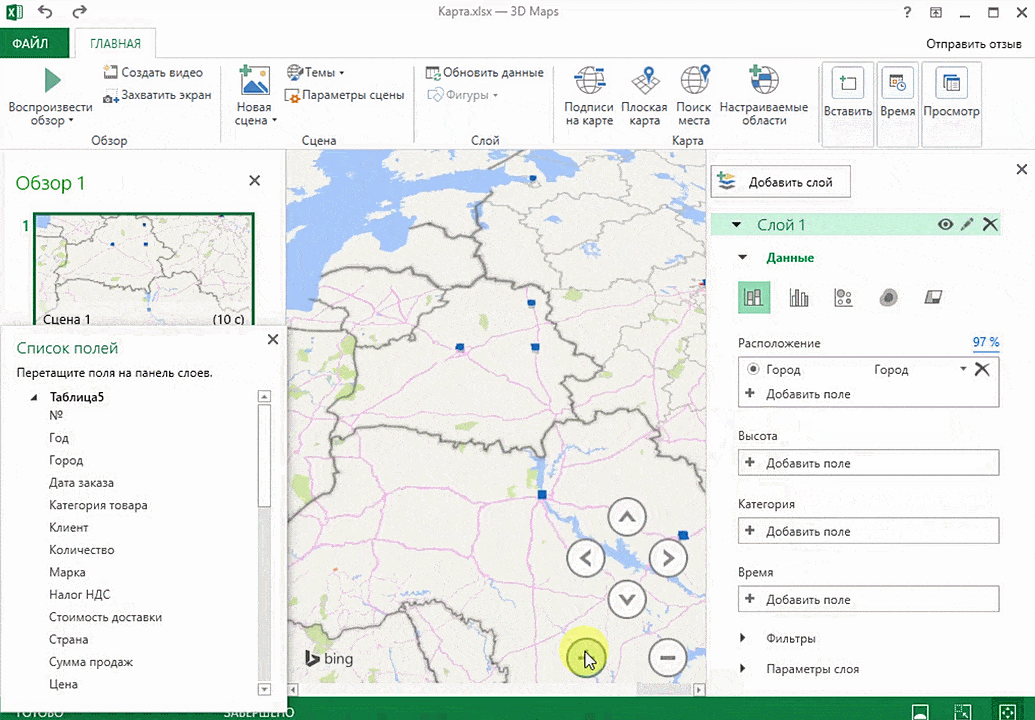
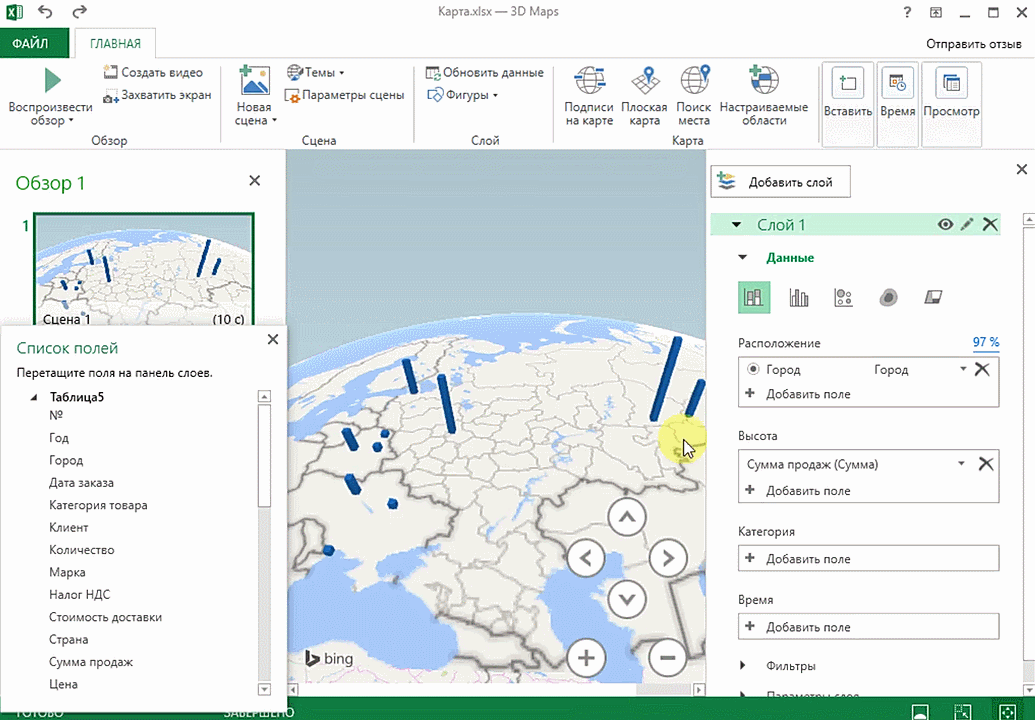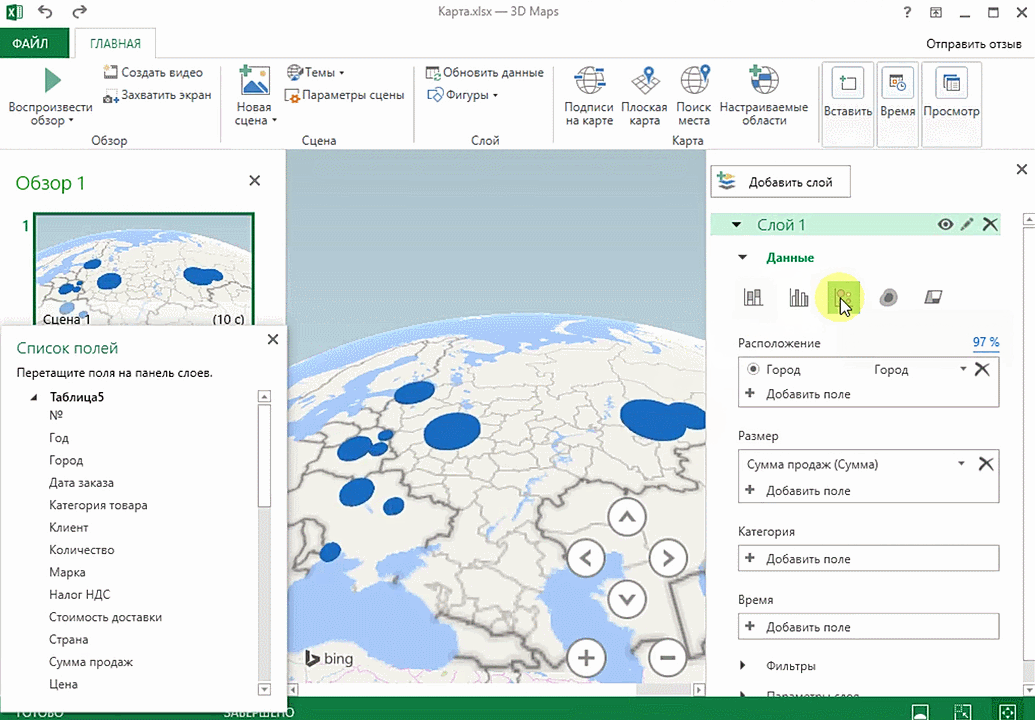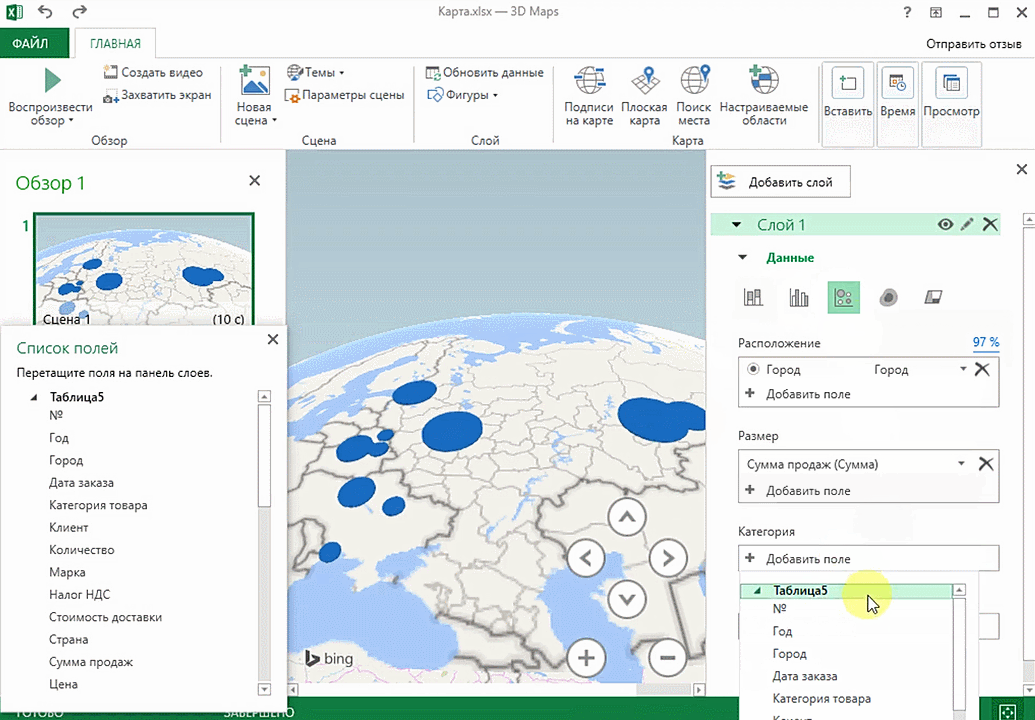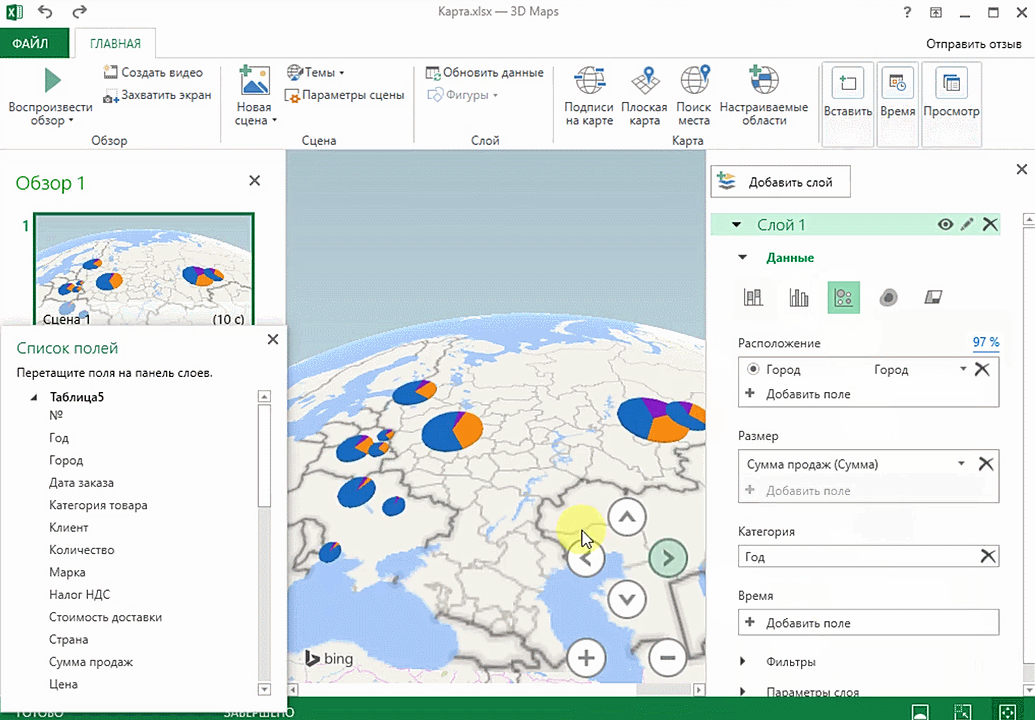
Также можно воспользоваться круговой диаграммой, которая является намного более информативной в некоторых случаях. От того, какая общая сумма по величине, зависит размер круга.
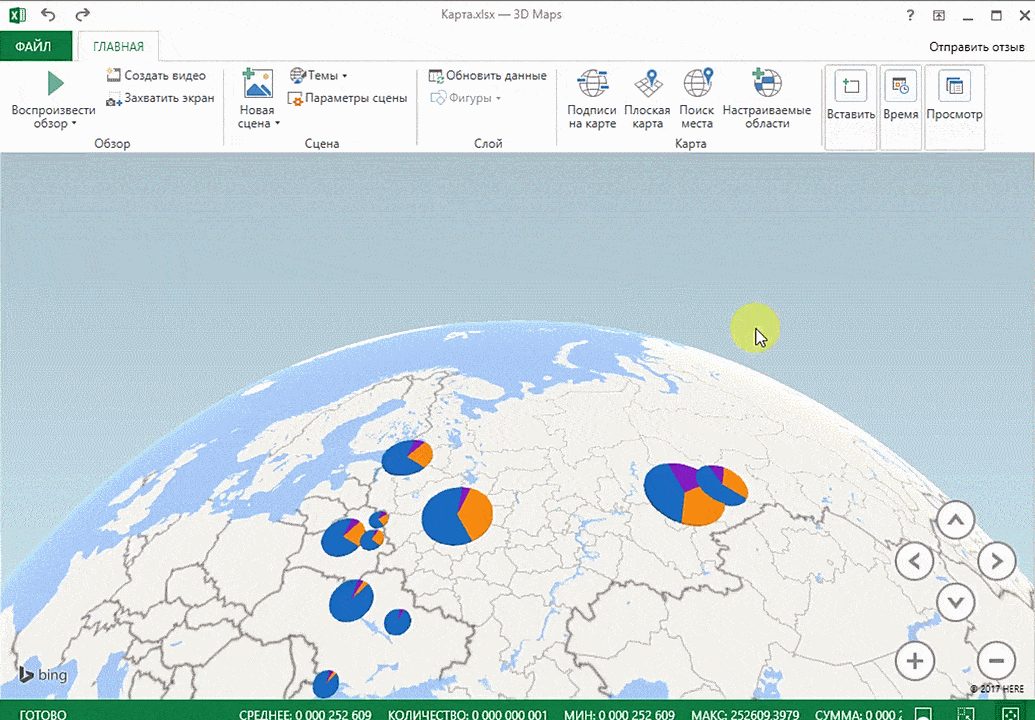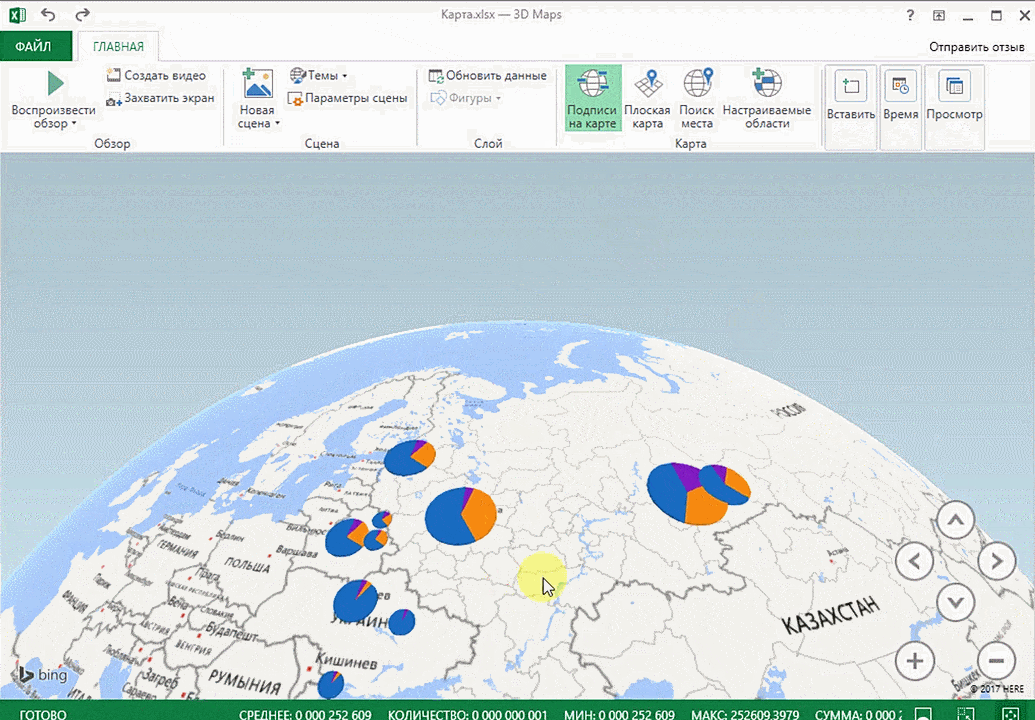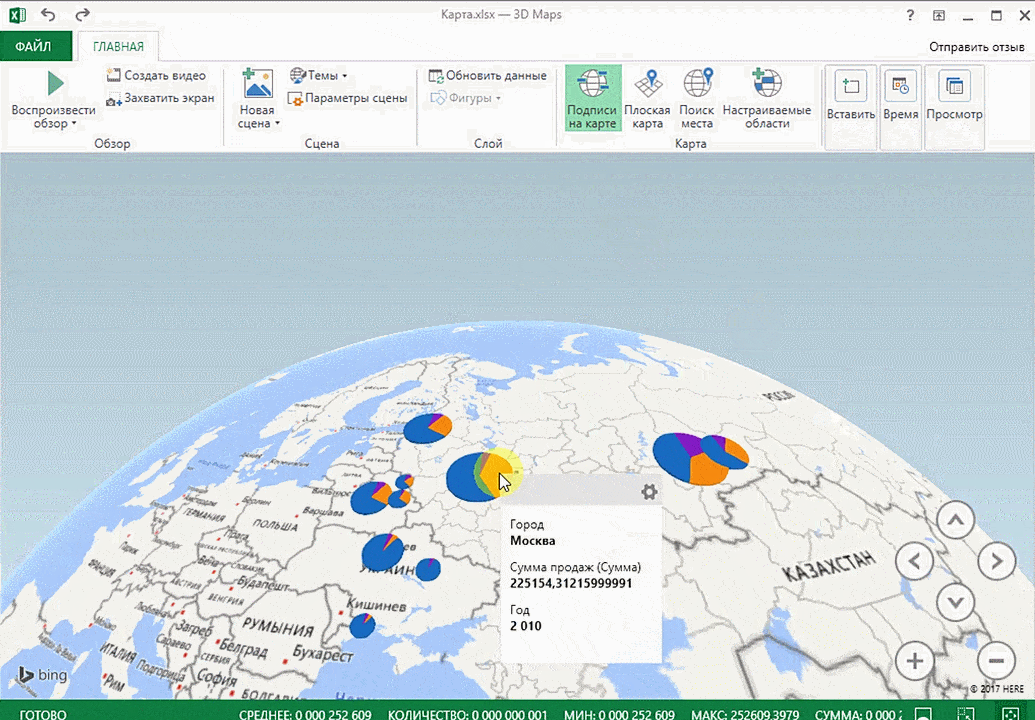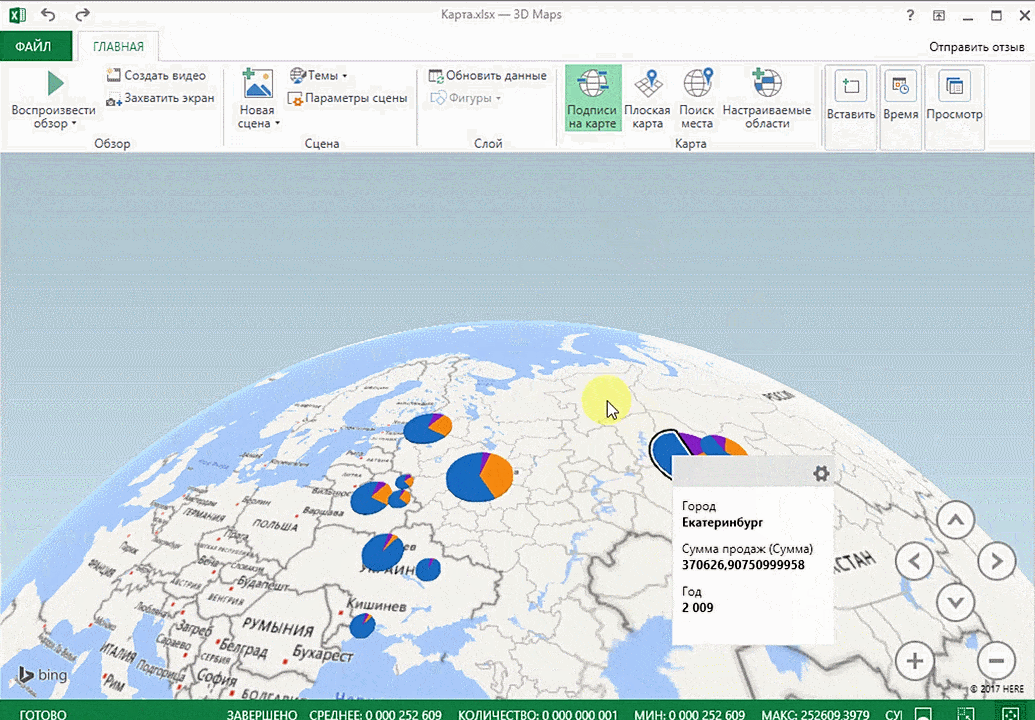
Лист прогноза в Excel
Нередко бизнес-процессы зависят от сезонных особенностей. И такие факторы надо обязательно принимать в учет на этапе планирования. Для этого существует специальный инструмент Excel, который понравится вам своей высокой точностью. Он значительно более функциональный, чем все описанные выше методы, какими бы отличными они ни были. Точно так же, очень широкой является сфера его использования – коммерческие, финансовые, маркетинговые и даже государственные структуры.
Важно: чтобы рассчитать прогноз, необходимо получить информацию за предыдущее время. От того, насколько долгосрочные данные, зависит качество прогнозирования. Рекомендуется иметь данные, которые разбиты по одинаковым интервалам (например, поквартально или помесячно).
Как работать с листом прогноза
Чтобы работать с листом прогноза, необходимо выполнять следующие действия:
- Откройте файл, в котором содержится большой объем информации по тем показателям, которые нам надо проанализировать. Например, в течение прошлого года (хотя чем больше, тем лучше).
- Выделите две строки с информацией.
- Перейдите в меню «Данные», и там кликните по кнопке «Лист прогноза».
- После этого откроется диалог, в котором можно выбрать тип визуального представления прогноза: график или гистограмма. Выберите тот, который подходит под вашу ситуацию.
- Установите дату, когда прогноз должен закончиться.
В приводимом нами ниже примере даются сведения за три года – 2011-2013. При этом рекомендуется указывать временные промежутки, а не конкретные числа. То есть, лучше писать март 2013, а не конкретное число типа 7 марта 2013 года. Чтобы исходя из этих данных получить прогноз на 2014 год необходимо получить данных, расположенные в рядах с датой и показателями, которые были на этот момент. Выделяем эти строки.
Затем переходим на вкладку «Данные» и ищем группу «Прогноз». После этого переходим в меню «Лист прогноза». После этого появится окно, в котором снова выбираем способ представления прогноза, а затем устанавливаем дату, к которой прогноз должен быть закончен. После этого нажимаем на «Создать», после чего получаем три варианта прогноза (показываются оранжевой линией).
Быстрый анализ в Excel
Предыдущий способ действительно хорош, потому что позволяет составлять реальные прогнозы, основываясь на статистических показателях. Но этот метод позволяет фактически проводить полноценную бизнес-аналитику. Очень классно, что эта возможность создана максимально эргономичной, поскольку для достижения желаемого результата необходимо совершить буквально несколько действий. Никаких ручных подсчетов, записи каких-либо формул. Достаточно просто выбрать диапазон, который будет анализироваться и задать конечную цель.
Есть возможность прямо в ячейке создавать самые разные диаграммы и микрографики.
Как работать
Итак, чтобы работать, нам надо надо открыть файл, в котором содержится тот набор данных, который надо анализировать и выделить соответствующий диапазон. После того, как мы его выделим, у нас автоматически появится кнопка, дающая возможность составить итоги или же выполнить набор других действий. Называется она быстрым анализом. Также мы можем определить суммы, которые автоматически будут проставлены внизу. Более наглядно посмотреть, как это работает, можете на этой анимации.
Функция быстрого анализа позволяет также по-разному форматировать получившиеся данные. А определить, какие значения больше или меньше, можно непосредственно в ячейках гистограммы, которая появляется после того, как мы настроим этот инструмент. 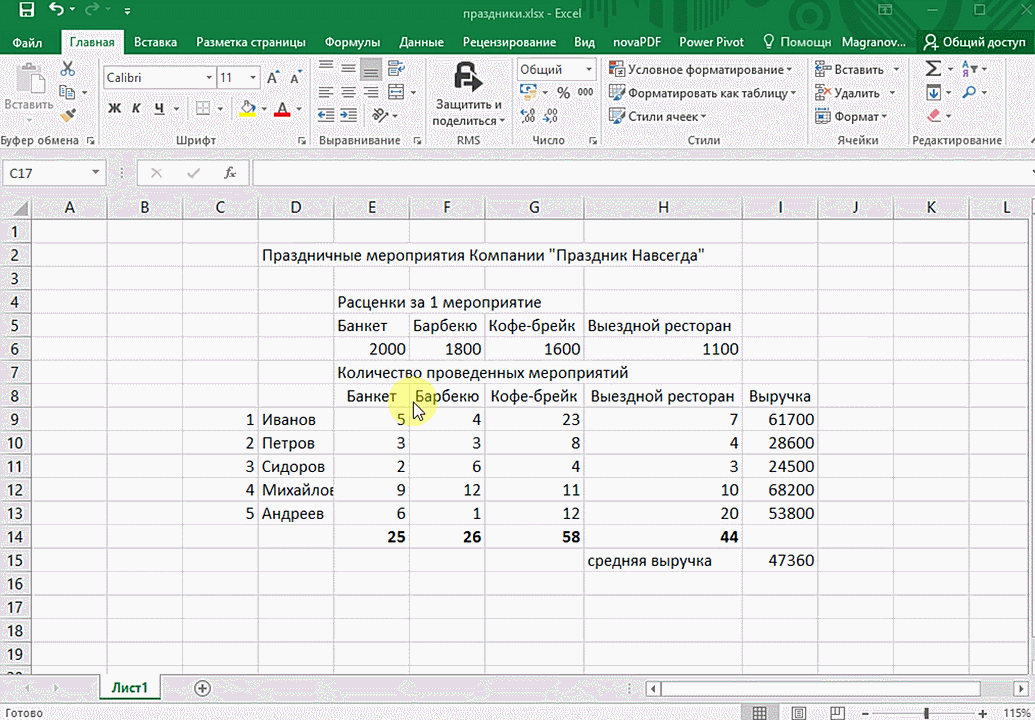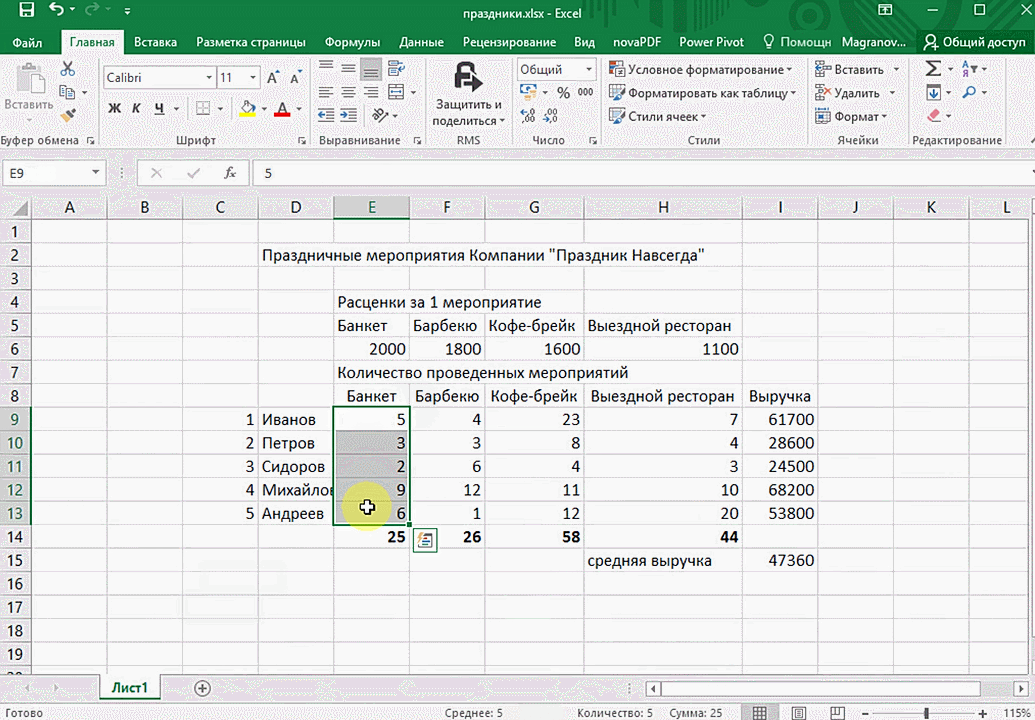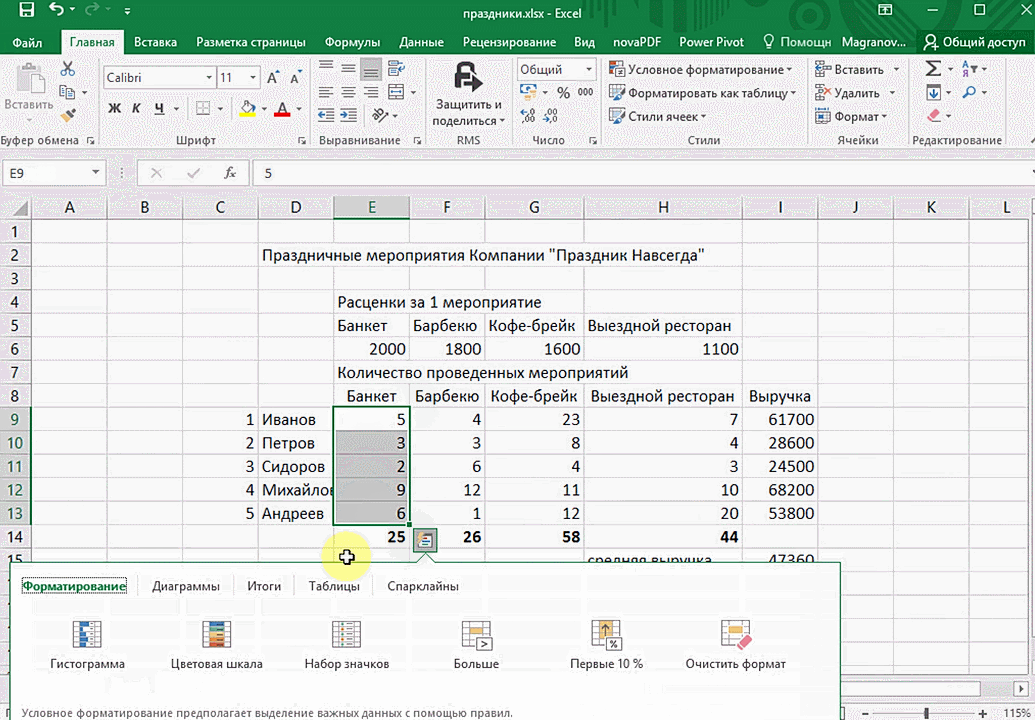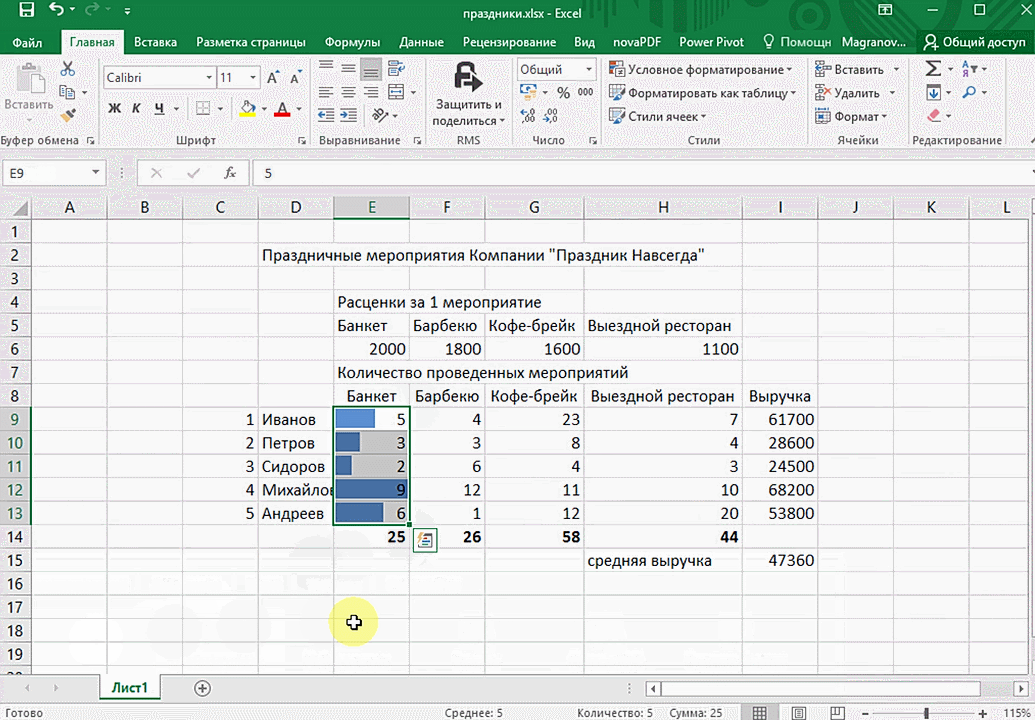
Также пользователь может поставить самые разные маркеры, которые обозначают большие и меньшие значения относительно тех, которые есть в выборке. Так, зеленым цветом будут показываться самые большие значения, а красным – наиболее маленькие.
Очень хочется верить, что эти приемы позволят вам значительно повысить эффективность вашей работы с электронными таблицами и максимально быстро добиться всего, что вы желаете. Как видим, эта программа для работы с электронными таблицами дает очень широкие возможности даже в стандартном функционале. А что уже говорить про дополнения, которых очень много на просторах интернета. Важно только обратить внимание, что все аддоны должны быть тщательно проверены на вирусы, потому что модули, написанные другими людьми, могут содержать вредоносный код. Если же надстройки разработаны компанией Майкрософт, то ее можно использовать смело.
Пакет анализа от Майкрософт – очень функциональная надстройка, которая делает пользователя настоящим профессионалом. Она позволяет выполнить почти любую обработку количественных данных, но она довольно сложная для начинающего пользователя. На официальном сайте справки Майкрософт есть детальная инструкция по тому, как использовать разные виды анализа с помощью этого пакета.
Оцените качество статьи. Нам важно ваше мнение: