
|
||||||||||||||||
|
American inventor Henry Ford famously said that history is “more or less bunk.” Others have characterized history differently: as the essence of innumerable biographies, as a picture of human crimes and misfortunes, as nothing but an agreed upon fable, as something that is bound to repeat itself.
It’s hard to define such a monumental thing without grappling with the tensions between what is fact and what is fiction, as well as what was included and what was left out. So it’s only fitting that those tensions are wrapped up in the history of the word itself.
The short version is that the term history has evolved from an ancient Greek verb that means “to know,” says the Oxford English Dictionary’s Philip Durkin. The Greek word historia originally meant inquiry, the act of seeking knowledge, as well as the knowledge that results from inquiry. And from there it’s a short jump to the accounts of events that a person might put together from making inquiries — what we might call stories.
The words story and history share much of their lineage, and in previous eras, the overlap between them was much messier than it is today. “That working out of distinction,” says Durkin, “has taken centuries and centuries.” Today, we might think of the dividing line as the one between fact and fiction. Stories are fanciful tales woven at bedtime, the plots of melodramatic soap operas. That word can even be used to describe an outright lie. Histories, on the other hand, are records of events. That word refers to all time preceding this very moment and everything that really happened up to now.
Get our History Newsletter. Put today’s news in context and see highlights from the archives.


Thank you!
For your security, we’ve sent a confirmation email to the address you entered. Click the link to confirm your subscription and begin receiving our newsletters. If you don’t get the confirmation within 10 minutes, please check your spam folder.
The distinction is still messier than that, of course. Plenty of stories — like the story of a person’s life or a “true story” on which a less-true film is based — are supposed to be factual. And plenty of stories defy easy categorization one way or the other. Take the notion of someone telling their side of a story. To them, that account might be as correct as any note about a president’s birthplace. To someone else, that account might be as incorrect as the notion that storks deliver babies. Yet the word stands up just fine to that stress because the term story has come to describe such varying amounts of truth and fiction.
As the linguistic divide has evolved since the Middle Ages, we have come to expect more from history — that it be free from the flaws of viewpoint and selective memory that stories so often contain. Yet it isn’t, humans being the imperfect and hierarchical creatures that they are and history being something that is made rather than handed down from some omniscient scribe.
That is why feminists, for example, rejected the word history and championed the notion of herstory during the 1970s, says Dictionary.com’s Jane Solomon, “to point out the fact that history has mostly come from a male perspective.” The “his” in history has nothing, linguistically, to do with the pronoun referring to a male person. And some critics pointed that out back in the 1970s, saying that the invention of herstory showed ignorance about where the word comes from. But sociolinguist Ben Zimmer says there’s evidence that the feminists knew as much at the time. And more importantly, the fact that it sounds plausible that there would be a link can still tell us something.
Take the fact that similar plays on the word have been made by people in other marginalized groups too: When jazz musician Sun Ra quipped that “history is only his story. You haven’t heard my story yet,” that statement might have nothing to do with etymology but it can suggest a lot about race and whether an African-American viewpoint is included in the tales passed down in textbooks. That’s why, even if the origins of the word “history” are clear, the question of who gets to decide which version of the past is the right one remains a contentious debate centuries after the term came to be.
“The narrative element has always been there,” Zimmer says. In some ways, the apocryphal tale about how history came to describe accounts of the past “plays on what has been hiding in that word all along.”
Correction: The original version of this story incorrectly described the origins of the words “history” and “inquiry.” They do not share the same root.
Contact us at letters@time.com.
This article is about the unit of speech and writing. For the computer software, see Microsoft Word. For other uses, see Word (disambiguation).

Codex Claromontanus in Latin. The practice of separating words with spaces was not universal when this manuscript was written.
A word is a basic element of language that carries an objective or practical meaning, can be used on its own, and is uninterruptible.[1] Despite the fact that language speakers often have an intuitive grasp of what a word is, there is no consensus among linguists on its definition and numerous attempts to find specific criteria of the concept remain controversial.[2] Different standards have been proposed, depending on the theoretical background and descriptive context; these do not converge on a single definition.[3]: 13:618 Some specific definitions of the term «word» are employed to convey its different meanings at different levels of description, for example based on phonological, grammatical or orthographic basis. Others suggest that the concept is simply a convention used in everyday situations.[4]: 6
The concept of «word» is distinguished from that of a morpheme, which is the smallest unit of language that has a meaning, even if it cannot stand on its own.[1] Words are made out of at least one morpheme. Morphemes can also be joined to create other words in a process of morphological derivation.[2]: 768 In English and many other languages, the morphemes that make up a word generally include at least one root (such as «rock», «god», «type», «writ», «can», «not») and possibly some affixes («-s», «un-«, «-ly», «-ness»). Words with more than one root («[type][writ]er», «[cow][boy]s», «[tele][graph]ically») are called compound words. In turn, words are combined to form other elements of language, such as phrases («a red rock», «put up with»), clauses («I threw a rock»), and sentences («I threw a rock, but missed»).
In many languages, the notion of what constitutes a «word» may be learned as part of learning the writing system.[5] This is the case for the English language, and for most languages that are written with alphabets derived from the ancient Latin or Greek alphabets. In English orthography, the letter sequences «rock», «god», «write», «with», «the», and «not» are considered to be single-morpheme words, whereas «rocks», «ungodliness», «typewriter», and «cannot» are words composed of two or more morphemes («rock»+»s», «un»+»god»+»li»+»ness», «type»+»writ»+»er», and «can»+»not»).
Definitions and meanings
Since the beginning of the study of linguistics, numerous attempts at defining what a word is have been made, with many different criteria.[5] However, no satisfying definition has yet been found to apply to all languages and at all levels of linguistic analysis. It is, however, possible to find consistent definitions of «word» at different levels of description.[4]: 6 These include definitions on the phonetic and phonological level, that it is the smallest segment of sound that can be theoretically isolated by word accent and boundary markers; on the orthographic level as a segment indicated by blank spaces in writing or print; on the basis of morphology as the basic element of grammatical paradigms like inflection, different from word-forms; within semantics as the smallest and relatively independent carrier of meaning in a lexicon; and syntactically, as the smallest permutable and substitutable unit of a sentence.[2]: 1285
In some languages, these different types of words coincide and one can analyze, for example, a «phonological word» as essentially the same as «grammatical word». However, in other languages they may correspond to elements of different size.[4]: 1 Much of the difficulty stems from the eurocentric bias, as languages from outside of Europe may not follow the intuitions of European scholars. Some of the criteria for «word» developed can only be applicable to languages of broadly European synthetic structure.[4]: 1-3 Because of this unclear status, some linguists propose avoiding the term «word» altogether, instead focusing on better defined terms such as morphemes.[6]
Dictionaries categorize a language’s lexicon into individually listed forms called lemmas. These can be taken as an indication of what constitutes a «word» in the opinion of the writers of that language. This written form of a word constitutes a lexeme.[2]: 670-671 The most appropriate means of measuring the length of a word is by counting its syllables or morphemes.[7] When a word has multiple definitions or multiple senses, it may result in confusion in a debate or discussion.[8]
Phonology
One distinguishable meaning of the term «word» can be defined on phonological grounds. It is a unit larger or equal to a syllable, which can be distinguished based on segmental or prosodic features, or through its interactions with phonological rules. In Walmatjari, an Australian language, roots or suffixes may have only one syllable but a phonologic word must have at least two syllables. A disyllabic verb root may take a zero suffix, e.g. luwa-ø ‘hit!’, but a monosyllabic root must take a suffix, e.g. ya-nta ‘go!’, thus conforming to a segmental pattern of Walmatjari words. In the Pitjantjatjara dialect of the Wati language, another language form Australia, a word-medial syllable can end with a consonant but a word-final syllable must end with a vowel.[4]: 14
In most languages, stress may serve a criterion for a phonological word. In languages with a fixed stress, it is possible to ascertain word boundaries from its location. Although it is impossible to predict word boundaries from stress alone in languages with phonemic stress, there will be just one syllable with primary stress per word, which allows for determining the total number of words in an utterance.[4]: 16
Many phonological rules operate only within a phonological word or specifically across word boundaries. In Hungarian, dental consonants /d/, /t/, /l/ or /n/ assimilate to a following semi-vowel /j/, yielding the corresponding palatal sound, but only within one word. Conversely, external sandhi rules act across word boundaries. The prototypical example of this rule comes from Sanskrit; however, initial consonant mutation in contemporary Celtic languages or the linking r phenomenon in some non-rhotic English dialects can also be used to illustrate word boundaries.[4]: 17
It is often the case that a phonological word does not correspond to our intuitive conception of a word. The Finnish compound word pääkaupunki ‘capital’ is phonologically two words (pää ‘head’ and kaupunki ‘city’) because it does not conform to Finnish patterns of vowel harmony within words. Conversely, a single phonological word may be made up of more than one syntactical elements, such as in the English phrase I’ll come, where I’ll forms one phonological word.[3]: 13:618
Lexemes
A word can be thought of as an item in a speaker’s internal lexicon; this is called a lexeme. Nevertheless, it is considered different from a word used in everyday speech, since it is assumed to also include inflected forms. Therefore, the lexeme teapot refers to the singular teapot as well as the plural, teapots. There is also the question to what extent should inflected or compounded words be included in a lexeme, especially in agglutinative languages. For example, there is little doubt that in Turkish the lexeme for house should include nominative singular ev or plural evler. However, it is not clear if it should also encompass the word evlerinizden ‘from your houses’, formed through regular suffixation. There are also lexemes such as «black and white» or «do-it-yourself», which, although consist of multiple words, still form a single collocation with a set meaning.[3]: 13:618
Grammar
Grammatical words are proposed to consist of a number of grammatical elements which occur together (not in separate places within a clause) in a fixed order and have a set meaning. However, there are exceptions to all of these criteria.[4]: 19
Single grammatical words have a fixed internal structure; when the structure is changed, the meaning of the word also changes. In Dyirbal, which can use many derivational affixes with its nouns, there are the dual suffix -jarran and the suffix -gabun meaning «another». With the noun yibi they can be arranged into yibi-jarran-gabun («another two women») or yibi-gabun-jarran («two other women») but changing the suffix order also changes their meaning. Speakers of a language also usually associate a specific meaning with a word and not a single morpheme. For example, when asked to talk about untruthfulness they rarely focus on the meaning of morphemes such as -th or -ness.[4]: 19-20
Semantics
Leonard Bloomfield introduced the concept of «Minimal Free Forms» in 1928. Words are thought of as the smallest meaningful unit of speech that can stand by themselves.[9]: 11 This correlates phonemes (units of sound) to lexemes (units of meaning). However, some written words are not minimal free forms as they make no sense by themselves (for example, the and of).[10]: 77 Some semanticists have put forward a theory of so-called semantic primitives or semantic primes, indefinable words representing fundamental concepts that are intuitively meaningful. According to this theory, semantic primes serve as the basis for describing the meaning, without circularity, of other words and their associated conceptual denotations.[11][12]
Features
In the Minimalist school of theoretical syntax, words (also called lexical items in the literature) are construed as «bundles» of linguistic features that are united into a structure with form and meaning.[13]: 36–37 For example, the word «koalas» has semantic features (it denotes real-world objects, koalas), category features (it is a noun), number features (it is plural and must agree with verbs, pronouns, and demonstratives in its domain), phonological features (it is pronounced a certain way), etc.
Orthography

Words made out of letters, divided by spaces
In languages with a literary tradition, the question of what is considered a single word is influenced by orthography. Word separators, typically spaces and punctuation marks are common in modern orthography of languages using alphabetic scripts, but these are a relatively modern development in the history of writing. In character encoding, word segmentation depends on which characters are defined as word dividers. In English orthography, compound expressions may contain spaces. For example, ice cream, air raid shelter and get up each are generally considered to consist of more than one word (as each of the components are free forms, with the possible exception of get), and so is no one, but the similarly compounded someone and nobody are considered single words.
Sometimes, languages which are close grammatically will consider the same order of words in different ways. For example, reflexive verbs in the French infinitive are separate from their respective particle, e.g. se laver («to wash oneself»), whereas in Portuguese they are hyphenated, e.g. lavar-se, and in Spanish they are joined, e.g. lavarse.[a]
Not all languages delimit words expressly. Mandarin Chinese is a highly analytic language with few inflectional affixes, making it unnecessary to delimit words orthographically. However, there are many multiple-morpheme compounds in Mandarin, as well as a variety of bound morphemes that make it difficult to clearly determine what constitutes a word.[14]: 56 Japanese uses orthographic cues to delimit words, such as switching between kanji (characters borrowed from Chinese writing) and the two kana syllabaries. This is a fairly soft rule, because content words can also be written in hiragana for effect, though if done extensively spaces are typically added to maintain legibility. Vietnamese orthography, although using the Latin alphabet, delimits monosyllabic morphemes rather than words.
Word boundaries
The task of defining what constitutes a «word» involves determining where one word ends and another word begins, that is identifying word boundaries. There are several ways to determine where the word boundaries of spoken language should be placed:[5]
- Potential pause: A speaker is told to repeat a given sentence slowly, allowing for pauses. The speaker will tend to insert pauses at the word boundaries. However, this method is not foolproof: the speaker could easily break up polysyllabic words, or fail to separate two or more closely linked words (e.g. «to a» in «He went to a house»).
- Indivisibility: A speaker is told to say a sentence out loud, and then is told to say the sentence again with extra words added to it. Thus, I have lived in this village for ten years might become My family and I have lived in this little village for about ten or so years. These extra words will tend to be added in the word boundaries of the original sentence. However, some languages have infixes, which are put inside a word. Similarly, some have separable affixes: in the German sentence «Ich komme gut zu Hause an«, the verb ankommen is separated.
- Phonetic boundaries: Some languages have particular rules of pronunciation that make it easy to spot where a word boundary should be. For example, in a language that regularly stresses the last syllable of a word, a word boundary is likely to fall after each stressed syllable. Another example can be seen in a language that has vowel harmony (like Turkish):[15]: 9 the vowels within a given word share the same quality, so a word boundary is likely to occur whenever the vowel quality changes. Nevertheless, not all languages have such convenient phonetic rules, and even those that do present the occasional exceptions.
- Orthographic boundaries: Word separators, such as spaces and punctuation marks can be used to distinguish single words. However, this depends on a specific language. East-asian writing systems often do not separate their characters. This is the case with Chinese, Japanese writing, which use logographic characters, as well as Thai and Lao, which are abugidas.
Morphology
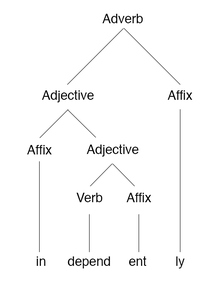
A morphology tree of the English word «independently»
Morphology is the study of word formation and structure. Words may undergo different morphological processes which are traditionally classified into two broad groups: derivation and inflection. Derivation is a process in which a new word is created from existing ones, often with a change of meaning. For example, in English the verb to convert may be modified into the noun a convert through stress shift and into the adjective convertible through affixation. Inflection adds grammatical information to a word, such as indicating case, tense, or gender.[14]: 73
In synthetic languages, a single word stem (for example, love) may inflect to have a number of different forms (for example, loves, loving, and loved). However, for some purposes these are not usually considered to be different words, but rather different forms of the same word. In these languages, words may be considered to be constructed from a number of morphemes.
In Indo-European languages in particular, the morphemes distinguished are:
- The root.
- Optional suffixes.
- A inflectional suffix.
Thus, the Proto-Indo-European *wr̥dhom would be analyzed as consisting of
- *wr̥-, the zero grade of the root *wer-.
- A root-extension *-dh- (diachronically a suffix), resulting in a complex root *wr̥dh-.
- The thematic suffix *-o-.
- The neuter gender nominative or accusative singular suffix *-m.
Philosophy
Philosophers have found words to be objects of fascination since at least the 5th century BC, with the foundation of the philosophy of language. Plato analyzed words in terms of their origins and the sounds making them up, concluding that there was some connection between sound and meaning, though words change a great deal over time. John Locke wrote that the use of words «is to be sensible marks of ideas», though they are chosen «not by any natural connexion that there is between particular articulate sounds and certain ideas, for then there would be but one language amongst all men; but by a voluntary imposition, whereby such a word is made arbitrarily the mark of such an idea».[16] Wittgenstein’s thought transitioned from a word as representation of meaning to «the meaning of a word is its use in the language.»[17]
Classes
Each word belongs to a category, based on shared grammatical properties. Typically, a language’s lexicon may be classified into several such groups of words. The total number of categories as well as their types are not universal and vary among languages. For example, English has a group of words called articles, such as the (the definite article) or a (the indefinite article), which mark definiteness or identifiability. This class is not present in Japanese, which depends on context to indicate this difference. On the other hand, Japanese has a class of words called particles which are used to mark noun phrases according to their grammatical function or thematic relation, which English marks using word order or prosody.[18]: 21–24
It is not clear if any categories other than interjection are universal parts of human language. The basic bipartite division that is ubiquitous in natural languages is that of nouns vs verbs. However, in some Wakashan and Salish languages, all content words may be understood as verbal in nature. In Lushootseed, a Salish language, all words with ‘noun-like’ meanings can be used predicatively, where they function like verb. For example, the word sbiaw can be understood as ‘(is a) coyote’ rather than simply ‘coyote’.[19][3]: 13:631 On the other hand, in Eskimo–Aleut languages all content words can be analyzed as nominal, with agentive nouns serving the role closest to verbs. Finally, in some Austronesian languages it is not clear whether the distinction is applicable and all words can be best described as interjections which can perform the roles of other categories.[3]: 13:631
The current classification of words into classes is based on the work of Dionysius Thrax, who, in the 1st century BC, distinguished eight categories of Ancient Greek words: noun, verb, participle, article, pronoun, preposition, adverb, and conjunction. Later Latin authors, Apollonius Dyscolus and Priscian, applied his framework to their own language; since Latin has no articles, they replaced this class with interjection. Adjectives (‘happy’), quantifiers (‘few’), and numerals (‘eleven’) were not made separate in those classifications due to their morphological similarity to nouns in Latin and Ancient Greek. They were recognized as distinct categories only when scholars started studying later European languages.[3]: 13:629
In Indian grammatical tradition, Pāṇini introduced a similar fundamental classification into a nominal (nāma, suP) and a verbal (ākhyāta, tiN) class, based on the set of suffixes taken by the word. Some words can be controversial, such as slang in formal contexts; misnomers, due to them not meaning what they would imply; or polysemous words, due to the potential confusion between their various senses.[20]
History
In ancient Greek and Roman grammatical tradition, the word was the basic unit of analysis. Different grammatical forms of a given lexeme were studied; however, there was no attempt to decompose them into morphemes. [21]: 70 This may have been the result of the synthetic nature of these languages, where the internal structure of words may be harder to decode than in analytic languages. There was also no concept of different kinds of words, such as grammatical or phonological – the word was considered a unitary construct.[4]: 269 The word (dictiō) was defined as the minimal unit of an utterance (ōrātiō), the expression of a complete thought.[21]: 70
See also
- Longest words
- Utterance
- Word (computer architecture)
- Word count, the number of words in a document or passage of text
- Wording
- Etymology
Notes
- ^ The convention also depends on the tense or mood—the examples given here are in the infinitive, whereas French imperatives, for example, are hyphenated, e.g. lavez-vous, whereas the Spanish present tense is completely separate, e.g. me lavo.
References
- ^ a b Brown, E. K. (2013). The Cambridge dictionary of linguistics. J. E. Miller. Cambridge: Cambridge University Press. p. 473. ISBN 978-0-521-76675-3. OCLC 801681536.
- ^ a b c d Bussmann, Hadumod (1998). Routledge dictionary of language and linguistics. Gregory Trauth, Kerstin Kazzazi. London: Routledge. p. 1285. ISBN 0-415-02225-8. OCLC 41252822.
- ^ a b c d e f Brown, Keith (2005). Encyclopedia of Language and Linguistics: V1-14. Keith Brown (2nd ed.). ISBN 1-322-06910-7. OCLC 1097103078.
- ^ a b c d e f g h i j Word: a cross-linguistic typology. Robert M. W. Dixon, A. Y. Aikhenvald. Cambridge: Cambridge University Press. 2002. ISBN 0-511-06149-8. OCLC 57123416.
{{cite book}}: CS1 maint: others (link) - ^ a b c Haspelmath, Martin (2011). «The indeterminacy of word segmentation and the nature of morphology and syntax». Folia Linguistica. 45 (1). doi:10.1515/flin.2011.002. ISSN 0165-4004. S2CID 62789916.
- ^ Harris, Zellig S. (1946). «From morpheme to utterance». Language. 22 (3): 161–183. doi:10.2307/410205. JSTOR 410205.
- ^ The Oxford handbook of the word. John R. Taylor (1st ed.). Oxford, United Kingdom. 2015. ISBN 978-0-19-175669-6. OCLC 945582776.
{{cite book}}: CS1 maint: others (link) - ^ Chodorow, Martin S.; Byrd, Roy J.; Heidorn, George E. (1985). «Extracting semantic hierarchies from a large on-line dictionary». Proceedings of the 23rd Annual Meeting on Association for Computational Linguistics. Chicago, Illinois: Association for Computational Linguistics: 299–304. doi:10.3115/981210.981247. S2CID 657749.
- ^ Katamba, Francis (2005). English words: structure, history, usage (2nd ed.). London: Routledge. ISBN 0-415-29892-X. OCLC 54001244.
- ^ Fleming, Michael; Hardman, Frank; Stevens, David; Williamson, John (2003-09-02). Meeting the Standards in Secondary English (1st ed.). Routledge. doi:10.4324/9780203165553. ISBN 978-1-134-56851-2.
- ^ Wierzbicka, Anna (1996). Semantics : primes and universals. Oxford [England]: Oxford University Press. ISBN 0-19-870002-4. OCLC 33012927.
- ^ «The search for the shared semantic core of all languages.». Meaning and universal grammar. Volume II: theory and empirical findings. Cliff Goddard, Anna Wierzbicka. Amsterdam: John Benjamins Pub. Co. 2002. ISBN 1-58811-264-0. OCLC 752499720.
{{cite book}}: CS1 maint: others (link) - ^ Adger, David (2003). Core syntax: a minimalist approach. Oxford: Oxford University Press. ISBN 0-19-924370-0. OCLC 50768042.
- ^ a b An introduction to language and linguistics. Ralph W. Fasold, Jeff Connor-Linton. Cambridge, UK: Cambridge University Press. 2006. ISBN 978-0-521-84768-1. OCLC 62532880.
{{cite book}}: CS1 maint: others (link) - ^ Bauer, Laurie (1983). English word-formation. Cambridge [Cambridgeshire]. ISBN 0-521-24167-7. OCLC 8728300.
- ^ Locke, John (1690). «Chapter II: Of the Signification of Words». An Essay Concerning Human Understanding. Vol. III (1st ed.). London: Thomas Basset.
- ^ Biletzki, Anar; Matar, Anat (2021). Ludwig Wittgenstein. The Stanford Encyclopedia of Philosophy (Winter 2021 ed.). Metaphysics Research Lab, Stanford University.
- ^ Linguistics: an introduction to language and communication. Adrian Akmajian (6th ed.). Cambridge, Mass.: MIT Press. 2010. ISBN 978-0-262-01375-8. OCLC 424454992.
{{cite book}}: CS1 maint: others (link) - ^ Beck, David (2013-08-29), Rijkhoff, Jan; van Lier, Eva (eds.), «Unidirectional flexibility and the noun–verb distinction in Lushootseed», Flexible Word Classes, Oxford University Press, pp. 185–220, doi:10.1093/acprof:oso/9780199668441.003.0007, ISBN 978-0-19-966844-1, retrieved 2022-08-25
- ^ De Soto, Clinton B.; Hamilton, Margaret M.; Taylor, Ralph B. (December 1985). «Words, People, and Implicit Personality Theory». Social Cognition. 3 (4): 369–382. doi:10.1521/soco.1985.3.4.369. ISSN 0278-016X.
- ^ a b Robins, R. H. (1997). A short history of linguistics (4th ed.). London. ISBN 0-582-24994-5. OCLC 35178602.
Bibliography
![]()
Wikimedia Commons has media related to Words.
![]()
Wikiquote has quotations related to Word.
![]()
Look up word in Wiktionary, the free dictionary.
- Barton, David (1994). Literacy: an introduction to the ecology of written language. Oxford, UK: Blackwell. p. 96. ISBN 0-631-19089-9. OCLC 28722223.
- The encyclopedia of language & linguistics. E. K. Brown, Anne Anderson (2nd ed.). Amsterdam: Elsevier. 2006. ISBN 978-0-08-044854-1. OCLC 771916896.
{{cite book}}: CS1 maint: others (link) - Crystal, David (1995). The Cambridge encyclopedia of the English language. Cambridge [England]: Cambridge University Press. ISBN 0-521-40179-8. OCLC 31518847.
- Plag, Ingo (2003). Word-formation in English. Cambridge: Cambridge University Press. ISBN 0-511-07843-9. OCLC 57545191.
- The Oxford English Dictionary. J. A. Simpson, E. S. C. Weiner, Oxford University Press (2nd ed.). Oxford: Clarendon Press. 1989. ISBN 0-19-861186-2. OCLC 17648714.
{{cite book}}: CS1 maint: others (link)
The etymology of a word refers to its origin and historical development: that is, its earliest known use, its transmission from one language to another, and its changes in form and meaning. Etymology is also the term for the branch of linguistics that studies word histories.
What’s the Difference Between a Definition and an Etymology?
A definition tells us what a word means and how it’s used in our own time. An etymology tells us where a word came from (often, but not always, from another language) and what it used to mean.
For example, according to The American Heritage Dictionary of the English Language, the definition of the word disaster is «an occurrence causing widespread destruction and distress; a catastrophe» or «a grave misfortune.» But the etymology of the word disaster takes us back to a time when people commonly blamed great misfortunes on the influence of the stars.
Disaster first appeared in English in the late 16th century, just in time for Shakespeare to use the word in the play King Lear. It arrived by way of the Old Italian word disastro, which meant «unfavorable to one’s stars.»
This older, astrological sense of disaster becomes easier to understand when we study its Latin root word, astrum, which also appears in our modern «star» word astronomy. With the negative Latin prefix dis- («apart») added to astrum («star»), the word (in Latin, Old Italian, and Middle French) conveyed the idea that a catastrophe could be traced to the «evil influence of a star or planet» (a definition that the dictionary tells us is now «obsolete»).
Is the Etymology of a Word Its True Definition?
Not at all, though people sometimes try to make this argument. The word etymology is derived from the Greek word etymon, which means «the true sense of a word.» But in fact the original meaning of a word is often different from its contemporary definition.
The meanings of many words have changed over time, and older senses of a word may grow uncommon or disappear entirely from everyday use. Disaster, for instance, no longer means the «evil influence of a star or planet,» just as consider no longer means «to observe the stars.»
Let’s look at another example. Our English word salary is defined by The American Heritage Dictionary as «fixed compensation for services, paid to a person on a regular basis.» Its etymology can be traced back 2,000 years to sal, the Latin word for salt. So what’s the connection between salt and salary?
The Roman historian Pliny the Elder tells us that «in Rome, a soldier was paid in salt,» which back then was widely used as a food preservative. Eventually, this salarium came to signify a stipend paid in any form, usually money. Even today the expression «worth your salt» indicates that you’re working hard and earning your salary. However, this doesn’t mean that salt is the true definition of salary.
Where Do Words Come From?
New words have entered (and continue to enter) the English language in many different ways. Here are some of the most common methods.
- Borrowing
The majority of the words used in modern English have been borrowed from other languages. Although most of our vocabulary comes from Latin and Greek (often by way of other European languages), English has borrowed words from more than 300 different languages around the world. Here are just a few examples:
futon (from the Japanese word for «bedclothes, bedding») - hamster (Middle High German hamastra)
- kangaroo (Aboriginal language of Guugu Yimidhirr, gangurru , referring to a species of kangaroo)
- kink (Dutch, «twist in a rope»)
- moccasin (Native American Indian, Virginia Algonquian, akin to Powhatan mäkäsn and Ojibwa makisin)
- molasses (Portuguese melaços, from Late Latin mellceum, from Latin mel, «honey»)
- muscle (Latin musculus, «mouse»)
- slogan (alteration of Scots slogorne, «battle cry»)
- smorgasbord (Swedish, literally «bread and butter table»)
- whiskey (Old Irish uisce, «water,» and bethad, «of life»)
- Clipping or Shortening
Some new words are simply shortened forms of existing words, for instance indie from independent; exam from examination; flu from influenza, and fax from facsimile. - Compounding
A new word may also be created by combining two or more existing words: fire engine, for example, and babysitter. - Blends
A blend, also called a portmanteau word, is a word formed by merging the sounds and meanings of two or more other words. Examples include moped, from mo(tor) + ped(al), and brunch, from br(eakfast) + (l)unch. - Conversion or Functional Shift
New words are often formed by changing an existing word from one part of speech to another. For example, innovations in technology have encouraged the transformation of the nouns network, Google, and microwave into verbs. - Transfer of Proper Nouns
Sometimes the names of people, places, and things become generalized vocabulary words. For instance, the noun maverick was derived from the name of an American cattleman, Samuel Augustus Maverick. The saxophone was named after Sax, the surname of a 19th-century Belgian family that made musical instruments. - Neologisms or Creative Coinages
Now and then, new products or processes inspire the creation of entirely new words. Such neologisms are usually short lived, never even making it into a dictionary. Nevertheless, some have endured, for example quark (coined by novelist James Joyce), galumph (Lewis Carroll), aspirin (originally a trademark), grok (Robert A. Heinlein). - Imitation of Sounds
Words are also created by onomatopoeia, naming things by imitating the sounds that are associated with them: boo, bow-wow, tinkle, click.
Why Should We Care About Word Histories?
If a word’s etymology is not the same as its definition, why should we care at all about word histories? Well, for one thing, understanding how words have developed can teach us a great deal about our cultural history. In addition, studying the histories of familiar words can help us deduce the meanings of unfamiliar words, thereby enriching our vocabularies. Finally, word stories are often both entertaining and thought provoking. In short, as any youngster can tell you, words are fun.
The growth
of the E. vocabulary from internal sources – through word-formation
and semantic change – can be observed in all periods of history. In
the 15-17th
c. its role became more important though the influx of borrowings
from other languages continued. Word formation fell into 2 types:
Word derivation and word
composition.
The means of derivation used in
OE continued to be employed in later periods: Suffixation, the most
productive way: most of the OE product. Suffixes have survived, many
– added from internal and external sources.
Prefixation was less productive
in ME, but later, in Early NE its productivity grew again.
Many OE prefixes dropped out of
use: a-,tō-,on-,of-,ze-,or-. In some words the prefix fused with the
root:OE on-zinna > ME ginnen > NE begin. The negative prefixes
mis- & un- produced a great number of new words:ME mislayen,
misdemen(NE mislay, misjudge). OE un- was mainly used with nouns and
adjectives: Early NE: unhook, unload.
Also, foreign prefixes were
adopted by the English lang. as component parts of loan-words:re-,
de-, dis-. Sound interchanges and the shifting of word stress were
mainly employed as a means of word differentiation, rather than as a
word-building means.
47.
Spelling
changes in ME and NE. Rules of reading.
The most conspicuous feature of
Late ME texts in comparison with OE texts is the difference in
spelling. The written forms in ME resemble modern forms, though the
pronunciation was different.
— In ME the runic letters
passed out of use. Thorn “ђ” and the crossed d: “đ” were
replaced by the digraph –th-, which retained the same sound value:
[Ө] & [ð]; the rune “wynn” was displaced by “double u”:
-w-;the ligatures æ & œ fell into disuse.
— Many innovations reveal an
influence of the French scribal tradition. The digraphs ou, ie &
ch were adopted as new ways of indicating the sounds [u:], [e:] &
[t∫] : e.g. OE ūt, ME out [u:t]; O Fr double, ME double [duble].
— The letters j,k,v,q were
first used in imitation of French manuscripts.
— The two-fold use of –g- &
-c- owes its origin to French: these letters usually stood for [dz] &
[s] before front vowels & for [g]&[k] before back vowels: ME
gentil [dzen’til], mercy [mer’si] & good[go:d].
— A wider use of digraphs: -sh-
is introduced to indicate the new sibilant [∫]: ME ship(from OE
scip); -dz- to indicate [dz]: ME edge [‘edze], joye [‘dzoiə];
the digraph –wh- replaced –hw-: OE hwæt, ME what [hwat].
— Long sounds were shown by
double letters: ME book [bo:k]
— The introduction of the
digraph –gh- for [x]& [x’]: ME knight [knix’t] & ME he
[he:].
— Some replacements were made
to avoid confusion of resembling letters: “o” was employed to
indicate “u”: OE munuc > ME monk; lufu > love. The letter
“y” – an equivalent og “i” : very, my [mi:].
48.Development of the syntactic system in me and early ne.
The
evolution of English syntax was tied up with profound changes in
morphology: the decline of the inflectional system was accompanied by
the growth of the functional load of syntactic means of word
connection. The most obvious difference between OE syntax and the
syntax of ME and NE periods is that the word order became more strict
and the use of prepositions more extensive. The growth of the
literary forms of the language, the literary flourishing in Late ME
and especially in the age of the Renaissance the differentiation of
literary styles and the efforts made by 18th
c. scholars to develop a logical, elegant style — all contributed to
the improvement and perfection of English syntax. The structure of
the sentence and word phrase, on the one hand, became more
complicated , on the other hand- were stabilized and standardized.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #