
Одна из самых неприятных ситуаций, с которой может столкнуться пользователь при работе в Microsoft Excel — это поиск и подстановка данных с неточным совпадением. Когда вам надо подставить данные из одной таблицы в другую, но вы при этом уверены, что в обеих таблицах совпадающие элементы называются одинаково, то проблем нет — к вашим услугам множество способов: функции ВПР и её аналоги, надстройка Power Query и т.д.
А вот если в одной таблице «Пупкин Василий», а в другой просто «Пупкин», или «Пупкин В.», или даже «Пупкен», то все эти красивые способы не работают. Причем на практике такое встречается постоянно, особенно с почтовыми адресами или названиями компаний:

Обратите внимание на различные типы несоответствий, которые могут встречаться:
- переставлены местами улица, город, дом
- отсутствует какая-то часть адреса или, наоборот, есть что-то лишнее (индекс, номер квартиры)
- по-разному записан город (с буквой «г.» или без) или улица
- опечатки и ошибки (Козань вместо Казань)
Про точное соответствие или даже поиск по маске тут говорить не приходится. Помочь в таком случае могут только специальные макросы или надстройки для Excel. Про одну из таких макро-функций на VBA я уже писал, а здесь хочется рассказать про еще один вариант решения подобной задачи — надстройку Fuzzy Lookup от компании Microsoft.
Эта надстройка существует с 2011 года и совершенно бесплатно скачивается с сайта Microsoft. Системные требования: Windows 7 или новее, Office 2007 или новее, соответственно. После установки у вас в Excel появляется одноименная вкладка с единственной кнопкой на ней:

Нажатие на эту кнопку включает специальную панель в правой части окна Excel, где и задаются все настройки поиска:

Сразу хочу отметить, что эта надстройка умеет работать только с умными таблицами, поэтому все исходные таблицы нужно конвертировать в умные с помощью сочетания Ctrl+T или кнопки Форматировать как таблицу на вкладке Главная (Home — Format as Table):
Алгоритм действий при работе с надстройкой Fuzzy Lookup следующий:
- Выберите какие таблицы нужно связать в выпадающих списках Left и Right Table.
- Выберите ключевые столбцы в левой и правой таблицах, по которым нужно проверить соответствие и нажмите кнопку для добавления созданной пары в список Match Columns
- В списке Output Columns отметьте галочками столбцы, которые вы хотите получить на выходе в качестве результата.
- Установите активную ячейку в пустое место на листе, куда вы хотите вывести данные
- Нажмите кнопку Go
После анализа мы получаем таблицу, где каждому элементу ключевого столбца из первой таблицы подобрано максимально похожее значение из второй:

Лепота!
Нюансы и подводные камни
- Точность подбора можно регулировать с помощью ползунка Similarity Threshold в нижней части панели Fuzzy Lookup. Чем правее его положение, тем строже будет поиск, и — как следствие — тем меньше результатов надстройка будет находить. Если сдвинуть его влево, то результатов станет больше, но возрастет риск ошибочного совпадения. Тут все зависит от вашей конкретной ситуации — экспериментируйте.
- На больших таблицах поиск может занимать приличное количество времени (до нескольких десятков секунд), хотя многое, конечно, зависит от мощности вашего компьютера. Как вариант, для ускорения в настройках (кнопка Configure в нижней части панели) можно попробовать включить параметр UseApproximateIndexing в разделе Global Settings.
- Перед нажатием на кнопку Go не забудьте выделить пустую ячейку, начиная с которой вы хотите вывести результаты. Если случайно вы оставите активную ячейку где-нибудь в исходных данных, то надстройка выведет итоговую таблицу прямо поверх них, и вы их потеряете. Причем отмена последнего действия будет невозможна, а кнопка Undo в нижней части панели не всегда срабатывает почему-то.
- Для вывода столбца с коэффициентом подобия FuzzyLookup.Similarity необходимо, чтобы у вашего Excel была точка в качестве десятичного разделителя (целой и дробной части). Если это не так, то эту настройку временно можно поменять через Файл — Параметры — Дополнительно (File — Options — Advanced).
- Fuzzy Lookup — это не обычная надстройка, написанная на VBA (как мой PLEX, например), а COM-надстройка. Разница в том, что она устанавливается как отдельная программа, т.е. вам нужны соответствующие права на установку ПО на вашем компьютере. Дома, ясное дело, проблем не будет, а вот многим корпоративным пользователям, скорее всего, придется обращаться к вашим айтишникам. После установки отключать и подключать ее в дальнейшем можно на вкладке Разработчик — Надстройки COM (Developer — COM Add-ins).
В любом случае, при всех имеющихся минусах, эта надстройка однозначно стоит того, чтобы находиться в арсенале любого продвинутого пользователя Microsoft Excel.
Ссылки по теме
- Неточный поиск ближайшего похожего текста с помощью макрофункции
- Анализ текста регулярными выражениями (RegExp) в Excel
- Ссылка на скачивание надстройки Fuzzy Lookup с сайта Microsoft
Проблема нечёткого поиска
Когда мы имеем дело с текстом, вводимым человеком, то в нём неизбежны ненамеренные ошибки. Вместо «пер. Гоголя» человек может набрать «пер. Ноголя» просто потому, что промахнётся по нужной клавише и нажмёт соседнюю. В виду этого, возникает задача поставить в соответствие введеному слову слово словарное, которое в наибольшей степени похоже на то, что ввёл пользователь. Классическая задача — верификация названий улиц, населенных пунктов и т.п. Обычный поиск тут бессилен, так как введенное слово в словаре отсутствует. Обычный поиск в состоянии только установить этот факт, но не в состоянии предложить пользователю на выбор наиболее близкие варианты. Нужна реализация нечёткого поиска.
Что я предлагаю
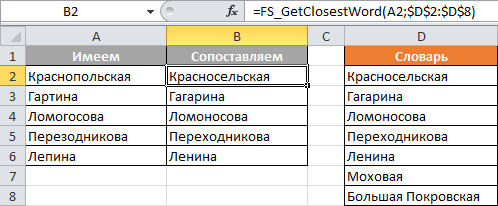
Для тех, кто спешит, сразу сообщаю, что, если тема актуальна, то я предлагаю вам воспользоваться своей пользовательской функцией рабочего листа, которая называется FS_GetClosestWord и имеет 2 обязательных параметра и 4 необязательных.
Формат вызова: =FS_GetClosestWord( What ; Where ; [NumItem] ; [MinLen] ; [Compare] ; [Dbg] ) , где:
-
What — ссылка на ячейку, которая содержит искомую строку. Обратите внимание, что текстовая константа в формуле не будет воспринята, только ссылка на ячейку;
-
Where — ссылка на диапазон, содержащий словарь, в котором необходимо подобрать наиболее близкое к What слово. Словарь может быть в виде столбца, строки или состоять из произвольного размера диапазона. Имейте только в виду, что, задав словарь из большого количества слов (скажем больше 10000), или, если словарь содержит много очень длинных слов, то вы рискуете надолго подвесить систему;
-
[NumItem] — в процессе поиска строится коллекция наиболее подходящих слов, которые ранжируются по определенному алгоритму. NumItem определяет
номер возвращаемого слова из этой коллеции. NumItem=1 возвращает наиболее близкое по мнению используемого алгоритма слово. Если указанный номер слишком велик и результирующая коллекция не содержит такого числа элементов, то возвращается ошибка #Н/Д; -
[MinLen] — минимальная длинна буквенных комбинаций, на которые разбиваются слова из словаря и, которые потом ищутся в слове из What. Не может быть меньше 3. Если укажете меньше 3 или не укажете вовсе, то будет использовано значение 3;
-
[Compare] — тип сравнения строк: с учётом регистра или без учёта. 0 — с учётом регистра, 1 — без учёта регистра;
-
[Dbg] — если указать тут число большее 1, то включится режим отладки и в зависимости от того, что вы тут укажаете, сможете получить:
-
1 — стандартное поведение, возвращающее близкое слово из Where;
-
2 — найденная подстрока;
-
3 — слепок найденного словарного слова;
-
4 — разница по модулю между слепком найденного и искомого слова, которая используется для ранжирования найденных слов по уровню схожести с оригинальным словом (чем меньше разница, тем считаются более похожими слова).
-
Большинство пользователей обойдутся первыми двумя параметрами.
Скачать файл с функцией
Скачать
Если будете переносить руками в свой Excel VBA проект, то не забудьте помимо модуля Fuzzy, также перенести класс Search.
Теория нечёткого поиска
Изучая вопрос, в начале заглянул к Николаю Павлову в этот его рецепт. Даже нашёл у него ошибки. Однако с самого начало было понятно, что предложенный алгоритм для общего случая будет неприемлем из-за медленной скорости, поэтому изыскания были продолжены. Отличный обзор алгоритмов нечёткого поиска дан в этой статье. Для своей реализации я выбрал метод N-грамм с привлечением хэширования по сигнатуре для оценки найденных вариантов.
Предположим, что у нас в словаре есть слово ПОМИДОР. Мой алгоритм разбивает это слово на подстроки длиной от 7 до 3 символов. 7 — длина слова в данном случае, а комбинации символов короче трёх символов использовать особого смысла нет.
-
7 символов — 1 вариант (ПОМИДОР)
-
6 символов — 2 варианта (ПОМИДО, ОМИДОР)
-
5 символов — 3 варианта (ПОМИД, ОМИДО, МИДОР)
-
4 символа — 4 варианта (ПОМИ, ОМИД, МИДО, ИДОР)
-
3 символа — 5 вариантов (ПОМ, ОМИ, МИД, ИДО, ДОР)
-
Итого мы получили из слова ПОМИДОР 15 разных буквенных комбинаций.
Все эти 15 комбинаций я помещаю в словарь. В этот же словарь заносятся все новые комбинации, образующиеся от остальных словарных слов. Далее берётся искомое слово и точно также разбивается на подстроки и прогоняется на совпадение с созданным словарём буквенных комбинаций. Все срабатывания заносятся в коллекцию и ранжируются по уровню похожести.
Проблемы реализации нечёткого поиска
На мой взгляд основная проблема тут — скорость поиска. Надо заметить, что прежде, чем я получил тот код, который вам предлагаю, я написал промежуточную статью про эффективность структур данных и перепробовал массу промежуточных вариантов структур и алгоритмов.
Поскольку всё реализовано в виде формулы рабочего листа, то основной способ улучшить производительность — это, чтобы каждая формула не расчитывала свою коллекцию буквенных комбинаций словаря, а использовала результаты однажды проделанной работы. Это было сделано через глобальные структуры. Однако это всё означает, что формула не отслеживает изменения в массиве Where. То есть считается, что диапазон Where статический и меняется редко.
Надеюсь вы найдёте этот функционал полезным. Если вам данное решение по какой-то причине не подошло или нуждается в серьёзной модификации, то дайте знать, возможно, я его доработаю, так как тема довольно интересная.
Читайте также:
-
Извлекаем список уникальных значений из необработанных данных
-
Формирование случайных списков на основе справочника
-
Расширенное сравнение двух колонок (списков)
Often you may want to join together two datasets in Excel based on imperfectly matching strings. This is sometimes called fuzzy matching.
The easiest way to do so is by using the Fuzzy Lookup Add-In for Excel.
The following step-by-step example shows how to use this Add-in to perform fuzzy matching.
Step 1: Download Fuzzy Lookup Add-In
First, we need to download the Fuzzy Lookup Add-In from Excel.
It’s completely free and downloads in only a few seconds.
To download this Add-In, go to this page from Microsoft and click Download:

Then click the .exe file and follow the instructions to complete the download.
Step 2: Enter the Two Datasets
Next, let’s open Excel and enter the following information for two datasets:

We will perform fuzzy matching to match the team names from the first dataset with the team names in the second dataset.
Step 3: Create Tables from Datasets
Before we can perform fuzzy matching, we must first convert each dataset into a table.
To do so, highlight the cell range A1:B6 and then press Ctrl+L.
In the new window that appears, click OK:

The dataset will be converted into a table with the name Table1:

Repeat the same steps to convert the second dataset into a table with the name Table2:

To perform Fuzzy matching, click the Fuzzy Lookup tab along the top ribbon:

Then click the Fuzzy Lookup icon within this tab to bring up the Fuzzy Lookup panel.
Choose Table1 for the Left Table and Table2 for the Right Table.
Then highlight Team for Left Columns and Team for Right Columns and click the join icon between the boxes, then click Go:

The results of the fuzzy matching will be shown in the cell you currently have active in Excel:

From the results we can see that Excel was able to match each team name between the two datasets except for the Kings.
Excel also shows a Similarity score, which represents the similarity between 0 and 1 of the two names that it matched.
Feel free to adjust the minimum Similarity score within the Fuzzy Lookup panel to allow for matching between text values that have lower similarity scores.
Additional Resources
The following tutorials explain how to perform other common tasks in Excel:
How to Count Frequency of Text in Excel
How to Check if Cell Contains Text from List in Excel
How to Calculate Average If Cell Contains Text in Excel
Иногда нам нужно не только выполнить точный поиск, но и выполнить нечеткий поиск, как показано на скриншоте ниже. На самом деле в Excel функция «Найти и заменить» несколько помогает при нечетком поиске.
Нечеткий поиск с помощью поиска и замены
Нечеткий поиск одного или нескольких значений с помощью удобного инструмента
Образец файла
Предположим, у вас есть диапазон A1: B6, как показано на скриншоте ниже, вы хотите найти нечеткую строку поиска «яблоко» без учета регистра или приложения в этом диапазоне. Для выполнения задания можно применить функцию «Найти и заменить».

Искать без учета регистра
1. Выберите диапазон, который вы хотите найти, нажмите клавиши Ctrl + F , чтобы включить функцию Найти и заменить , введите строку, которую вы хотите найти, в Найдите текстовое поле.

2. Нажмите Параметры , чтобы развернуть диалоговое окно, снимите флажок Учитывать регистр , но установите флажок Сопоставить все содержимое ячейки .

3. Нажмите Найти все , строки перечислены без учета регистра.

Найти часть строки
1. Выберите диапазон и нажмите клавиши Ctrl + F , чтобы включить функцию Найти и заменить , и введите строку детали, которую вы хотите найти, в Найдите текстовое поле , снимите флажок Соответствовать всему содержимому ячейки , при необходимости также снимите флажок Учитывать регистр .

2. Нажмите Найти все , и будут перечислены ячейки, содержащие строку.

Нечеткий поиск одного значения или нескольких значений с помощью удобного инструмента
Если вам нужно найти примерно одно значение или узнать все приблизительные значения одновременно, вы можете использовать функцию Fuzzy Lookup в Kutools for Excel .
| Kutools for Excel , с более чем 300 удобными функциями, упрощает вашу работу. |
|
Бесплатная загрузка |
После бесплатной установки Kutools for Excel, сделайте следующее:
Найдите примерно одно значение
Предположим, вы хотите найти значение «app» в диапазоне A1: A7, но количество различных символов не может быть больше 2, а количество символов должно быть больше 1.

1. Нажмите Kutools > Найти > Нечеткий поиск , чтобы включить панель Нечеткий поиск .

2. На всплывающей панели выполните следующие действия:
1) Выберите диапазон, который вы использовали для поиска, вы можете установить флажок Указано , чтобы исправить диапазон поиска.
2) Установите флажок Найти по указанному тексту .
3) Введите значение, на основе которого вы хотите выполнять нечеткий поиск, в Text .
4) Укажите необходимые критерии поиска.

3. Нажмите кнопку Найти , затем нажмите стрелку вниз, чтобы развернуть список и просмотреть результаты поиска.

Нечеткий поиск нескольких значений
Предположим, вы хотите найти все приблизительные значения в диапазоне A1: B7, вы можете сделать следующее:

1. Нажмите Kutools > Найти > Нечеткий поиск , чтобы включить панель Нечеткий поиск .
2. На панели Нечеткий поиск выберите диапазон поиска, а затем укажите необходимые критерии поиска.

3. Нажмите кнопку Найти , чтобы перейти к просмотру результатов поиска, затем нажмите стрелку вниз, чтобы развернуть список.

Быстрое разделение данных на несколько листов на основе столбца или фиксированных строк в Excel
|
| Предположим, у вас есть рабочий лист с данными в столбцах A на G имя продавца находится в столбце A, и вам необходимо автоматически разделить эти данные на несколько листов на основе столбца A в той же книге, и каждый продавец будет разделен на новый рабочий лист. Kutools for Excel может помочь вам быстро разделить данные на несколько листов на основе выбранного столбца, как показано на скриншоте ниже в Excel. Нажмите, чтобы получить 60-дневную бесплатную пробную версию! |
 |
| Kutools for Excel: с более чем 300 удобными надстройками Excel, бесплатно и без ограничений в течение 30 дней. |
Образец файла
Щелкните, чтобы загрузить образец файла
Другие операции (статьи)
Найти наибольшее отрицательное значение (меньше 0) в Excel
Для большинства пользователей Excel найти наибольшее значение из диапазона очень легко, но как насчет поиска наибольшего отрицательного значения (меньше чем 0) из диапазона данных, смешанного с отрицательными и положительными значениями?
Найти наименьший общий знаменатель или наибольший общий знаменатель в Excel
Все мы, возможно, помним, что в студенческие годы нас просили вычислить наименьший общий знаменатель или наибольший общий знаменатель некоторых чисел. Но если их десять или больше и несколько больших чисел, эта работа будет сложной.
Пакетный поиск и замена определенного текста в гиперссылках в Excel
В Excel вы можете выполнить пакетную замену определенной текстовой строки или символа в ячейках другим с помощью функции «Найти и заменить». Однако в некоторых случаях вам может потребоваться найти и заменить определенный текст в гиперссылках, исключая другие форматы содержимого.
Примените Функция обратного поиска или поиска в Excel
Как правило, мы можем применить функцию поиска или поиска для поиска определенного текста слева направо в текстовой строке по определенному разделителю. Если вам нужно перевернуть функцию поиска, чтобы найти слово, начинающееся в конце строки, как показано на следующем снимке экрана, как вы могли бы это сделать?
Другие статьи
Инструменты повышения производительности Excel -> ->
Еще одна проблема, которую часто приходится решать при обработке данных для последующего анализа — это сопоставление информации из разных источников. В наиболее простом случае это может быть сопоставление двух таблиц, в которых один из столбцов полностью или частично совпадают. В случае, если обработка данных проходит в СУБД, то задача решается написанием простого SQL-запроса (при условии, что исходные таблицы правильно созданы и имеют идентификаторы). В Excel для решения подобных задач существует замечательная функция ВПР (VLOOKUP), которая берет значение в одном из столбцов таблицы и возвращает значение из другого столбца.
Однако практическое использование этой функции для обработки обычных данных, может оказать довольно проблематичным. Что делать, если значения «почти» совпадают, но не совсем точно? К примеру, в одной из таблиц сравниваемая ячейка имеет запятую, а в другой нет? Или в одной используется «-«, а в другой «–» и так далее.
Я с подобными трудностями постоянно сталкиваюсь как минимум в двух случаях:
- При обработке данных по отдельным регионам РФ или странам мира. Проблема заключается в том, что разные страны или регионы могут иметь в разных источниках слегка отличающиеся названия. К примеру, » г. Москва» или «Москва (город)», «Белоруссия» или «Республика Беларусь», «Ханты-Мансийский автономный округ — Югра» или »
Ханты-Мансийский авт. округ — Югра» и так далее. Примеров может быть множество, причем зачастую один и тот же источник (тот же Росстат) может использовать в разных публикациях или разных источниках немного отличающиеся названия регионов. Формально существует ГОСТ 7.67-2003, который определяет как должны называться страны и российские регионы «по стандарту», но на практике в точности ему никто не следует даже в официальных статистических публикациях. Да и ГОСТ сам себе уже старый (2003 год) и странный. к примеру, в нем определены «Башкирия (Республика Башкортостан)», но просто «Татарстан». Почему именно так понять решительно невозможно, запомнить — тем более. Названия стран в английском языке также могут именоваться слегка по разному. Классическое «USA», «U.S.» или «United States»? - Названия видов экономической деятельности ( поОКВЭД). Формально тоже существует официальный вариант названий, выложенный на сайте Росстата. Но и сам Росстат ему не следует. К примеру, в ЦБСД названия видов деятельности часто имеют такой вид «Предоставление усл. по добыче нефти и газа» вместо «Предоставление услуг по добыче нефти и газа» (11.2) или «Добыча и произ-ство соли» вместо «Добыча и производство соли» и так далее. ЦБСД при выдаче результатов по видам экономической деятельности не сохраняет код вида, поэтому идентификация возможно только по названию. Новая информационная система — «Новая межведомственная информационно-статистическая система»- имеет одинаковые названия видов в соответствии со стандартом и даже умеет выдавать результаты в формате SDMХ, в котором присутствуют коды видов деятельности, но она обновляется с большим опозданием.
Этими примерами все не ограничивается. Подобная проблема возникает постоянно, когда нужно объединить информацию из разных источников, относящихся к одной и той же сущности, которая не имеет однозначного идентификатора.
Что же делать?
Первый и достаточно очевидный ответ — сделать все вручную. Метод вполне хороший и оправдывает себя, если количество «сущностей» не слишком велико, и задача возникает лишь эпизодически.
Если же речь о других масштабах, к примеру, раскидать данные по всем более чем двум тысячам видам деятельности и имеет регулярный характер, можно подумать об автоматизации, по крайней мере частичной.
В терминах обработки текстов подобная задача носит стандартное название «fuzzy string match». Существует множество алгоритмов для решения задач. Хорошее их описание на русском языке есть на хабрахабре. Общая идея всех алгоритмов — разработка некоторой метрики оценки «схожести» строк. Полностью одинаковые строки имеют метрику 1.0, полностью не совпадающие строки — 0.0. Пользователь задает «точку отсечения» строк, которые будут считаться одинаковыми — к примеру, это может быть 0.9 и алгоритм считает, что строки которые значение метрики больше являются одинаковыми. Один из наиболее известных метрик — расстояние Левенштейна (по имени советского математика из Института им. Келдыша). Расстояние Левенштейна определяет минимальное количество вставок, замен или удалений символов, необходимое для того, чтобы превратить одну строку в другую.
Алгоритмы — это хорошо, но как воспользоваться их возможностями без необходимости того, чтобы программировать самому?
Я знаю два бесплатных инструмента, которые можно использовать прямо «с колес» без особых знаний тонкостей алгоритмов:
- Google Refine. Как называет его сама Google, » a power tool for working with messy data». Программа бесплатно скачивается и устанавливается на десктоп. Работает в окне браузера. Позволяет открыть локальный файл или документ Google Docs и сопоставить «похожие» значения. Для нечеткого сравнения программа предлагает несколько алгоритмов, подробно описанных в документации. Вообще программа умеет много чего, и имеет смысл поразбираться в ней, благо документация написана хорошо, есть даже видеоролики с иллюстрациями разных возможностей. Проблема для меня заключается в том, что передача файлов и обратно в Google Refine занимает время. Работа в веб-браузере понятна, но не очень удобна (для меня по крайней мере), поэтому я использовал несколько раз Google Refine для обработки бюджетной статистики и обработки большой таблицы со статистикой по странам по разным странам, но не нашел программу уж очень удобной для быстрой работы.
- Надстройка Fuzzy Lookup для Excel, написанная самой Microsoft. Программа также бесплатно скачивается и устанавливается в Excel. Внешний вид выглядит примерно так (обработка таблиц с видами деятельности):
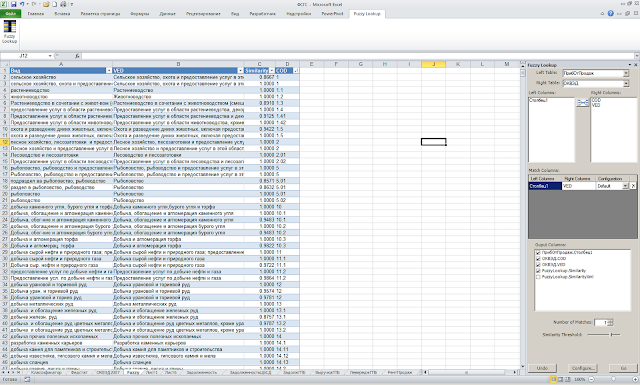
В архиве есть файл с примером, который показывает как все работает. Важное, что нужно запомнить для того, чтобы сравнивать таблицы: нужно их создать в виде «таблицы» (то есть Вставка-Таблица). Первой выбирается таблица из которой берутся исходные значения, второй — которые сопоставляются с исходными. Можно выбрать несколько столбцов, по которым будет проводиться сопоставление столбцов, для этого надо добавить несколько столбцов в Match Columns. В Output Columns можно выводить не все имеющиеся столбцы, и лишь те, что нужно. Это довольно удобно. К примеру, стандартная функция ВПР ничего подобного не умеет, поэтому надстройкой Fuzzly Lookup можно пользоваться и для «четкого» сопоставления разных таблиц.
Алгоритм работы программы не описывается, но на практике он дает вполне нормальные результаты и для строк на русском языке. Главное не забыть, проверить результаты сопоставления и исправить возможные ошибки алгоритма вручную. Для этого надо обратить на строки, в которых Fuzzy.Lookup.Similarity отличается от 1 и удостовериться, что «автоматическое» сопоставление сработало правильно.
P.S. Функция ВПР имеет параметр «Интервальный просмотр», который можно поставить на значение «1». Это будет означать приблизительное соответствие . Но я не рекомендую его использовать ни при каких обстоятельствах, так как результаты этой «приблизительности» абсолютно непонятны. Можно легко получить неправильные значения. Ошибку же крайне сложно будет обнаружить пост-фактум.