
![]()
![]()
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Любому бизнесу интересно заглянуть в будущее и правильно ответить на вопрос: «А сколько денег мы заработаем за следующий период?» Ответить на такого рода вопросы позволяют различные методики прогнозирования. В данной статье мы с вами рассмотрим несколько таких методик и произведем все необходимые расчеты в Excel. Еще больше про анализ данных в Excel мы рассказываем на нашем открытом курсе «Аналитика в Excel».
Постановка задачи
Исходные данные
Для начала, давайте определимся, какие у нас есть исходные данные и что нам нужно получить на выходе. Фактически, все что у нас есть, это некоторые исторические данные. Если мы говорим о прогнозировании продаж, то историческими данными будут продажи за предыдущие периоды.
Примечание. Собранные в разные моменты времени значения одной и той же величины образуют временной ряд. Каждое значение такого временного ряда называется измерением. Например: данные о продажах за последние 5 лет по месяцам — временной ряд; продажи за январь прошлого года — измерение.
Составляющие прогноза
Следующий шаг: давайте определимся, что нам нужно учесть при построении прогноза. Когда мы исследуем наши данные, нам необходимо учесть следующие факторы:
- Изменение нашей пронозируемой величины (например, продаж) подчиняется некоторому закону. Другими словами, в временном ряде можно проследить некую тенденцию. В математике такая тенденция называется трендом.
- Изменение значений в временном ряде может зависить от промежутка времени. Другими словами, при построении модели необходимо будет учесть коэффициент сезонности. Например, продажи арбузов в январе и августе не могут быть одинаковыми, т.к. это сезонный продукт и летом продажи значительно выше.
- Изменение значений в временном ряде периодически повторяется, т.е. наблюдается некоторая цикличность.
Эти три пункта в совокупность образуют регулярную составляющую временного ряда.
Примечание. Не обязательно все три элемента регулярной составляющей должны присутствовать в временном ряде.
Однако, помимо регулярной составляющей, в временном ряде присутствует еще некоторое случайное отклонение. Интуитивно это понятно – продажи могут зависеть от многих факторов, некоторые из которых могут быть случайными.
Вывод. Чтобы комплексно описать временной ряд, необходимо учесть 2 главных компонента: регулярную составляющую (тренд + сезонность + цикличность) и случайную составляющую.
Виды моделей
Следующий вопрос, на который нужно ответить при построении прогноза: “А какие модели временного ряда бывают?”
Обычно выделяют два основных вида:
- Аддитивная модель: Уровень временного ряда = Тренд + Сезонность + Случайные отклонения
- Мультипликативная модель: Уровень временного ряда = Тренд X Сезонность X Случайные отклонения
Иногда также выделают смешанную модель в отдельную группу:
- Смешанная модель: Уровень временного ряда = Тренд X Сезонность + Случайные отклонения
С моделями мы определились, но теперь возникает еще один вопрос: «А когда какую модель лучше использовать?»
Классический вариант такой:
— Аддитивная модель используется, если амплитуда колебаний более-менее постоянная;
— Мультипликативная – если амплитуда колебаний зависит от значения сезонной компоненты.
Пример:

Решение задачи с помощью Excel
Итак, необходимые теоретические знания мы с вами получили, пришло время применить их на практике. Мы будем с вами использовать классическую аддитивную модель для построения прогноза. Однако, мы построим с вами два прогноза:
- с использованием линейного тренда
- с использованием полиномиального тренда
Во всех руководствах, как правило, разбирается только линейный тренд, поэтому полиномиальная модель будет крайне полезна для вас и вашей работы!
![]()
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Модель с линейным трендом
Пусть у нас есть исходная информация по продажам за 2 года:
Учитывая, что мы используем линейный тренд, то нам необходимо найти коэффициенты уравнения
y = ax + b
где:
- y – значения продаж
- x – номер периода
- a – коэффициент наклона прямой тренда
- b – свободный член тренда
Рассчитать коэффициенты данного уравнения можно с помощью формулы массива и функции ЛИНЕЙН. Нам необходимо будет сделать следующую последовательность действий:
- Выделяем две ячейки рядом
- Ставим курсор в поле формул и вводим формулу =ЛИНЕЙН(C4:C27;B4:B27)
- Нажимаем Ctrl+Shift+Enter, чтобы активировать формулу массива
На выходе мы получили 2 числа: первое — коэффициент a, второе – свободный член b.
Теперь нам нужно рассчитать для каждого периода значение линейного тренда. Сделать это крайне просто — достаточно в полученное уравнение подставить известные номера периодов. Например, в нашем случае, мы прописываем формулу =B4*$F$4+$G$4 в ячейке I4 и протягиваем ее вниз по всем периодам.
Нам осталось рассчитать коэффициент сезонности для каждого периода. Учитывая, что у нас есть исторические данные за два года, разумно будет учесть это при расчете. Можем сделать следующим образом: в ячейке J4 прописываем формулу =(C4+C16)/СРЗНАЧ($C$4:$C$27)/2 и протягиваем вниз на 12 месяцев (т.е. до J15).
Что нам это дало? Мы посчитали, сколько суммарно продавалось каждый январь/каждый февраль и так далее, а потом разделили это на среднее значение продаж за все два периода.
То есть мы выяснили, как продажи двух январей отклонялись от средних продаж за два года, как продажи двух февралей отклонялись и так далее. Это и дает нам коэффициент сезонности. В конце формулы делим на 2, т.к. в расчете фигурировало 2 периода.
Примечание. Рассчитали только 12 коэффициентов, т.к. один коэффициент учитывает продажи сразу за 2 аналогичных периода.
Итак, теперь мы на финишной прямой. Нам осталось рассчитать тренд для будущих периодов и учесть коэффициент сезонности для них. Давайте амбициозно построим прогноз на год вперед.
Сначала создаем столбец, в котором прописываем номера будущих периодов. В нашем случае нумерация начинается с 25 периода.
Далее, для расчета значения тренда просто прописываем уже известную нам формулу =L4*$F$4+$G$4 и протягиваем вниз на все 12 прогнозируемых периодов.
И последний штрих — умножаем полученное значение на коэффициент сезонности. Вуаля, это и есть итоговый ответ в данной модели!
Модель с полиномиальным трендом
Конструкция, которую мы только что с вами построили, достаточно проста. Но у нее есть один большой минус — далеко не всегда она дает достоверные результаты.
Посмотрите сами, какая модель более точно аппроксимирует наши точки — линейный тренд (прямая зеленая линия) или полиномиальный тренд (красная кривая)? Ответ очевиден. Поэтому сейчас мы с вами и разберем, как построить полиномиальную модель в Excel.
Пусть все исходные данные у нас будут такими же. Для простоты модели будем учитывать только тренд, без сезонной составляющей.
Для начала давайте определимся, чем полиномиальный тренд отличается от обычного линейного. Правильно — формой уравнения. У линейного тренда мы разбирали обычный график прямой:
У полиномиального тренда же уравнение выглядит иначе: ![]()
где конечная степень определяется степенью полинома.
Т.е. для полинома 4 степени необходимо найти коэффициенты уравнения:
Согласитесь, выглядит немного страшно. Однако, ничего страшного нет, и мы с легкостью можем решить эту задачку с помощью уже известных нам методов.
- Ставим в ячейку F4 курсор и вводим формулу =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^{1;2;3;4});1;1). Функция ЛИНЕЙН позволяет произвести расчет коэффициентов, а с помощью функции ИНДЕКС мы вытаскиваем нужный нам коэффициент. В данном случае за выбор коэффициента отвечает самый последний аргумент. У нас стоит 1 — это коэффициент при самой высокой степени (т.е. при 4 степени, коэффициент). Кстати, узнать о самых полезных математических формулах Excel можно в нашем бесплатном гайде «Математические функции Excel».
- Аналогично прописываем формулу =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^{1;2;3;4});1;2) в ячейке ниже.
- Делаем такие же действия, пока не найдем все коэффициенты.
![]()
Кстати говоря, мы можем легко сами себя проверить. Давайте построим график наших продаж и добавим к нему полиномиальный тренд.
- Выделяем столбец с продажами
- Выбираем «Вставка» → «График» → «Точечный» → «Точечная диаграмма»
- Нажимаем на любую точку графика правой кнопкой мыши и выбираем «Добавить линию тренда»
- В открывшемся справа меню выбираем «Полиномиальная модель», меняем степень на 4 и ставим галочку на «Показывать уравнение на диаграмме»
![]()
Теперь вы наглядно можете видеть, как рассчитанный тренд аппроксимирует исходные данные и как выглядит само уравнение. Можно сравнить уравнение на графике с вашими коэффициентами. Сходится? Значит сделали все верно!
Помимо всего прочего, вы можете сразу оценить точность аппроксимации (не полностью, но хотя бы первично). Это делается с помощью коэффициента R^2. Тут у вас снова есть два пути:
- Вы можете вывести коэффициент на график, поставив галочку «Поместить на диаграмму величину достоверности аппроксимации»
- Вы можете рассчитать коэффициент R^2 самостоятельно по формуле =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^{1;2;3;4};;1);3;1)
![]()
Заключение
Мы с вами подробно разобрали вопрос прогнозирования — изучили необходимые термины и виды моделей, построили аддитивную модель в Excel с использованием линейного и полиномиального тренда, а также научились отображать результаты своих вычислений на графиках. Все это позволит вам эффективно внедрять полученные знания на работе, усложнять существующие модели и уточнять прогнозы. Чем большим количеством методов и инструментов вы будете владеть, тем выше будет ваш профессиональный уровень и статус на рынке труда.
Если вас интересуют еще какие-то модели прогнозирования — напишите нам об этом, и мы постараемся осветить эти темы в дальнейших своих статьях! Или запишитесь на курс «Excel Academy» от SF Education, где мы рассказываем про возможности Excel, необходимые для анализа.
Автор: Алексанян Андрон, эксперт SF Education
![]()
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Блог SF Education
Data Science
5 примеров экономии времени в Excel
Что для работодателя главное в сотруднике? Добросовестность, ответственность, профессионализм и, конечно же, умение пользоваться отведенным временем! Предлагаем познакомиться с очень нужными, на наш взгляд,…
В прошлой статье мы уже разобрали, что такое временной ряд и функцию тренда. Теперь подробнее разберемся с терминологией и остановимся на одной из моделей временного ряда.
Из чего состоит временной ряд
Уровни временного ряда (Yt) представляют из себя сумму двух компонент:
- Регулярную составляющую
- Случайную составляющую
В свою очередь регулярная составляющая состоит из:
- Тренда
- Сезонности
- Циклической составляющей
Однако, в модели необязательно наличие всех этих компонент сразу.
Случайная компонента отражает влияние случайных возмущений на модель, которые по отдельности имеют незначительное воздействие, но суммарно их влияние ощущается.
То есть, в общем случае временной ряд представляет из себя наличие четырех составляющих:
- Тренд (Tt)
- Сезонность (St)
- Цикличность (Ct)
- Случайные возмущения (Et)
Циклическая компонента, по сравнению с сезонностью, имеет более длительный эффект и меняется от цикла к циклу. Поэтому, ее обычно объединяют с трендом.
Виды моделей временного ряда
Обычно, выделяют две модели временного ряда и третью — смешанную.
- Аддитивная модель

-
Мультипликативная модель

-
Смешанная модель

При выборе необходимой модели временного ряда смотрят на амплитуду колебаний сезонной составляющей. Если ее колебания относительно постоянны, то выбирают аддитивную модель. То есть, амплитуда колебаний примерно одинакова:

Если амплитуда сезонных колебаний возрастает или уменьшается, строят мультипликативную модель временного ряда, которая ставит уровни ряда в зависимость от значений сезонной компоненты.
Построение этих моделей сводится к расчету тренда (Tt), сезонности (St) и случайных возмущений (Et) для каждого уровня ряда (Yt).
Алгоритм построения модели
- Выравниваем ряд с помощью скользящей средней, то есть сглаживаем ряд и отфильтровываем высокочастотные колебания.
- Рассчитываем значение сезонной компоненты St.
- Рассчитываем значения Tt с использованием полученного уравнения тренда.
- Используя полученные значения St и Tt, находим прогнозные значения уровней временного ряда.
- Оцениваем качество модели.
Реализация на практике
Итак, мы имеем на руках данные о продажах за 2016 и 2017 год и хотим спрогнозировать продажи на 2018 год.


Шаг 1
Следуя нашему алгоритму, мы должны сгладить временной ряд. Воспользуемся методом скользящей средней. Видим, что в каждом году есть большие пики (май-июнь 2016 и апрель 2017), поэтому возьмем период сглаживания пошире, например, месячную динамику, т.е. 12 месяцев.
Удобнее брать период сглаживания в виде нечетного числа, тогда формула для расчета уровней сглаженного ряда:

yi — фактическое значение i-го уровня ряда,
yt — значение скользящей средней в момент времени t,
2p+1 — длина интервала сглаживания.
Но так как мы решили использовать месячную динамику в виде четного числа 12, то данная формула нам не подойдет и мы воспользуемся этой:
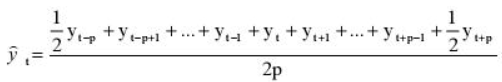
Иными словами, мы учитываем половины от крайних уровней ряда в диапазоне, в остальном формула не претерпела больше никаких изменений. Вот ее точный вид для нашей задачи:
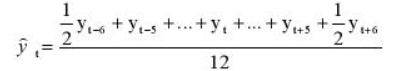
Сглаживаем наши уровни ряда и растягиваем формулу вниз:

Сразу можем построить график из известных значений уровня продаж и их сглаженной. Выведем ее уравнение и значение коэффициента детерминации R^2:

В качестве сглаженной я выбрала полином третьей степени, так как он лучше всего описывал уровни временного ряда и имел наибольший R^2.

Шаг 2
Так как мы рассматриваем аддитивную модель вида: 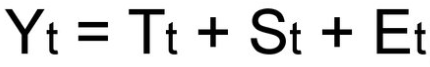
Найдем оценки сезонной компоненты как разность между фактическими уровнями ряда и значениями скользящей средней St+Et = Yt-Tt, так как Yt и Tt мы уже знаем.

Используем оценки сезонной компоненты (St+Et) для расчета значений сезонной компоненты St. Для этого найдем средние за каждый интервал (по всем годам) оценки сезонной компоненты St.

Средняя оценка сезонной компоненты находится как сумма по столбцу, деленная на количество заполненных строк в этом столбце. В нашем случае оценки сезонной составляющей расположились в строках без пересечений, поэтому сумма по столбцам состоит из одиночных значений, следовательно и среднее будет таким же. Если бы мы располагали периодом побольше, например с 2015, у нас бы добавилась еще одна строка и мы смогли бы полноценно найти среднее, поделив сумму на 2.
В моделях с сезонной компонентой обычно предполагается, что сезонные воздействия за период взаимопогашаются. В аддитивной модели это выражается в том, что сумма значений сезонной компоненты по всем интервалам должна быть равна нулю. Поэтому найдя значение случайной составляющей, поделив сумму средних оценок сезонной составляющей на 12, мы вычитаем ее значение из каждой средней оценки и получаем скорректированную сезонную компоненту, St.
Далее, заполняем нашу таблицу значениями сезонной составляющей дублируя ряд каждые 12 месяцев, то есть три раза:

Шаг 3
Теперь рассчитываем значения уровня тренда T(t) по тому уравнению, которое мы получили при построении сглаженного тренда на первом шаге.
T(t) = -23294+34114*t-1593*t^2+26,3*t^3
Вместо t используем значения из столбца Период из соответствующей строки.

Шаг 4
Имея рассчитанные значения S(t) и T(t) мы можем рассчитать прогнозные значения уровней ряда Y(t). Для этого накладываем уровни сезонности на тренд.

Теперь построим график известных значений Y(t) и спрогнозированных за 2018 год.

Вот мы и нашли спрогнозированные значения уровней продаж на 2018 год. Значения отражают возрастающую тенденцию и сезонные пики. Конечно, эти данные не дают 100% точности, ведь существует множество внешних воздействий, которые могут изменить направление тренда, поэтому к прогнозным значениям обычно строят доверительный интервал, это такой коридор, внутри которого могут колебаться прогнозные значения с заданной вероятностью (чаще всего выбирают 95%). Но об этом я расскажу в следующей статье.
Шаг 5
Осталось оценить точность модели. Для этого будем использовать среднюю ошибку аппроксимации, которая поможет рассчитать ошибку в относительном выражении. Иными словами, это среднее отклонение расчетных значений от фактических, которое вычисляется по формуле:

yi — спрогнозированные уровни ряда,
yi* — фактические уровни ряда,
n — количество складываемых элементов.
Модель может считаться адекватной, если:

Итак, рассчитываем ошибку аппроксимации для нашего случая. Так как в основе нашего тренда лежит полином третьей степени, прогнозные значения начинают хорошо повторять фактические значения к концу 2016 года, думаю, я думаю, поэтому корректнее было бы рассчитать ошибку аппроксимации для значений 2017 года.

Сложив весь столбец с ошибками аппроксимации и поделив на 12, получаем среднюю ошибку аппроксимации 4,13%. Это значение меньше 15% и можем сделать вывод об адекватности модели.
Не забывайте, что прогнозы не бывают точными на 100%. Любые неожиданные внешние воздействия могут развернуть значения уровней ряда в неизвестном направлении 🙂
Полезные ссылки:
- Ссылка на пример Google Sheets
- Построение функции тренда в Excel. Быстрый прогноз без учета сезонности
- Бывшев В.А. Эконометрика
- Об авторе
- Свежие записи

 Из данной статьи вы узнаете
Из данной статьи вы узнаете
- Что такое аддитивная сезонность,
- Как рассчитать аддитивную сезонность в Excel,
- Как учесть аддитивную сезонность в прогнозе.
Что такое аддитивная сезонность?
Сезонность можно разделить на 2 типа:
- Аддитивная;
- Мультипликативная.
В математике:
- Аддитивность — это операция сложения, формула прогноза F = T + S;
- Мультиплекативность – это операция умножения, формула прогноза F=T*S.
Где,
- T – это средняя или тренд;
- S – сезонность;
- F – прогноз.
Аддитивная сезонность измеряется в тех же единицах, что и ряд, т.е. если мы рассматриваем ряд с продажами в рублях по месяцам, то аддитивная сезонность будет выражена в отклонениях одного месяца относительно средней или тренда в рублях.
Мультипликативная сезонность измеряется в относительных единицах – коэффициентах и в среднем равна 1. Т.е. коэффициент января у нас может получится — 0,9, февраля — 1,1…
Аддитивную сезонность имеет смысл использовать, если амплитуда колебаний сезонности из года в год не меняется. Если амплитуда колебаний сезонности из года в год меняется (т.е. размах уменьшается или увеличивается), то используем мультипликативную сезонность.
Как рассчитать аддитивную сезонность в Excel?
Скачайте Excel-файл с примером расчета аддитивной сезонности
Возьмем продажи, например, муки по месяцам. Сезонность есть, но продажи из года в год стабильны, возрастающей амплитуды колебаний сезонности не наблюдается.
Для расчета аддитивной сезонности:
- Выделим линейный тренд из данных;
- Рассчитаем разницу «фактические продажи минус тренд»;
- Определим аддитивную сезонность по месяцам — среднее отклонение продаж от тренда для каждого месяца.
1. Выделим линейный тренд из данных.
Для расчета значений тренда для каждого периода времени пронумеруем значения временного ряда – продажи по месяцам:
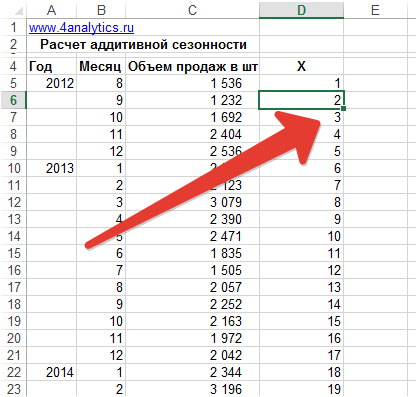
С помощью функции Excel =предсказ() рассчитаем значения тренда по месяцам:
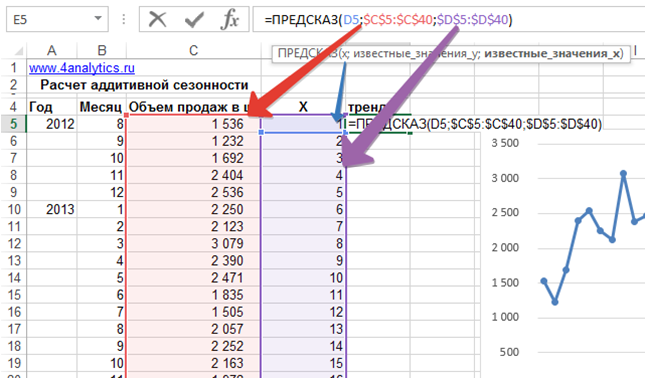
=ПРЕДСКАЗ где
- D5 – X – номер периода, для которого рассчитываем значение тренда;
- $C$5:$C$40 – известные значения y — фиксированная ссылка на диапазон с объемами продаж;
- $D$5:$D$40 – известные значения X – фиксированная ссылка на диапазон с номерами периодов.
Как зафиксировать ссылку, читайте в статье «Как зафиксировать ссылку в Excel».
Рассчитали значения тренда:
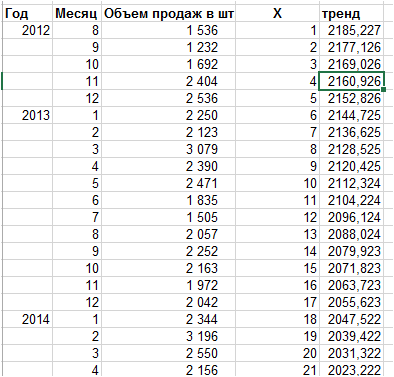
2. Рассчитываем разницу значений ряда и тренда — объем продаж минус тренд:
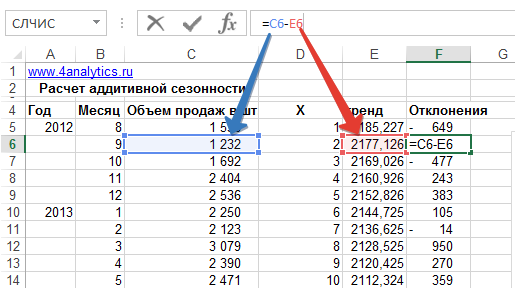
3. Определим аддитивную сезонность по месяцам — среднее отклонение продаж от тренда для каждого месяца.
Определяем среднее отклонение для каждого месяца:
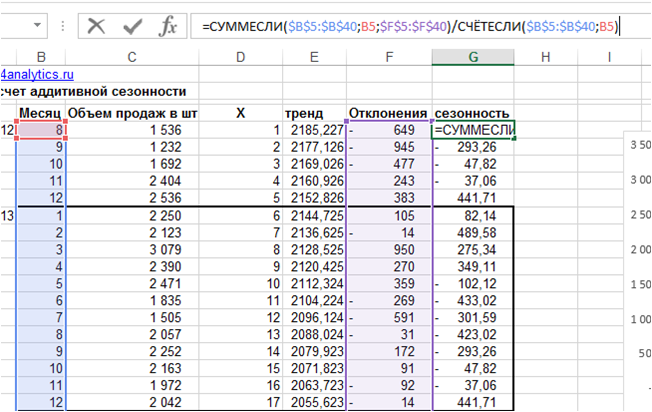
Т.к. первый и последний годы не полные, чтобы не запутаться с месяцами и формулами, воспользуемся формулой:
=СУММЕСЛИ($B$5:$B$40;B5;$F$5:$F$40)/СЧЁТЕСЛИ($B$5:$B$40;B5), где
- =СУММЕСЛИ — формула суммирует отклонения по заданным месяцам
- $B$5:$B$40; — ссылка на диапазон с номерами месяцев
- B5; — номер конкретного месяца для суммирования
- $F$5:$F$40 — ссылка на диапазон для суммирования
- / — делим сумму за определенный месяц на количество, получаем среднее по месяцам
- СЧЁТЕСЛИ — формула считает количество месяцев в диапазоне
- $B$5:$B$40; — диапазон с номерами месяцев
- B5 – номер конкретного месяца для счета
Получаем среднее отклонение по месяцам – аддитивную сезонность:
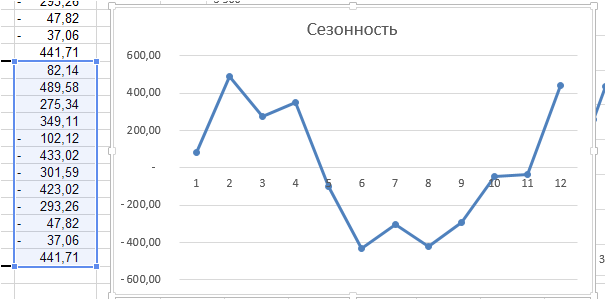
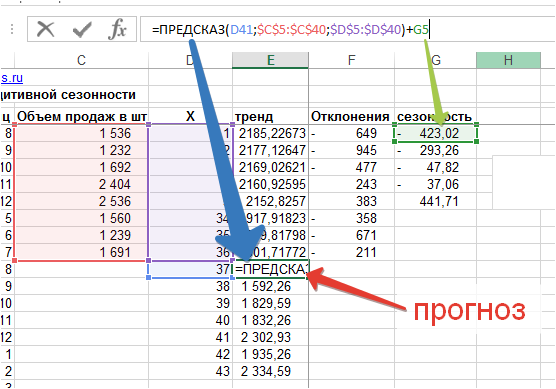
Для расчета прогноза:
- Продлеваем тренд в будущее;
- К тренду прибавляем аддитивную сезонность соответствующего месяца.
Получаем прогноз:
Скачайте Excel-файл с примером расчета аддитивной сезонности
Программа Forecast4AC PRO умеет автоматически подбирать аддитивную или мультипликативную сезонность, модель прогноза и подходит для прогноза большого массива данных.
Если есть вопросы, пожалуйста, обращайтесь!
Точных вам прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel.
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Зарегистрируйтесь и скачайте решения
Статья полезная? Поделитесь с друзьями
Рассмотрим
построение модели аддитивного ряда
средствами Exel
2007 на примере изучения объемов потребления
электроэнергии (млн кВТ*ч) жителями
региона за 16 кварталов и на основании
полученной модели спрогнозируем объем
потребляемой электроэнергии на следующие
полгода. Построенный пример описан в
![]() .
.
Пусть
известный объем потребляемой электроэнергии
задан таблицей 1.
Таблица
1. Потребление электроэнергии жителями
региона, млн кВТ*ч
|
№ кварт. |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
16 |
|
Объем (млн |
6,0 |
4,4 |
5,0 |
9,0 |
7,2 |
4,8 |
6,0 |
10 |
8,0 |
5,6 |
6,4 |
11 |
9,0 |
6,6 |
7,0 |
10.8 |
-
Внесем
эти данные в таблицу

-
В
главном меню выбираем «ВСТАВКА»
-
В
главном меню выбираем «ТОЧЕЧНАЯ»
-
Получаем
график

-
Теперь
считаем сезонную компоненту и среднюю
ошибку аппроксимации. Для этого открываем
лист 2 и копируем в него первые два
столбца. По методике, описанной в
1рассчитаем значения сезонной компоненты.
Таблица
1- Расчет оценок сезонной компоненты в
аддитивной модели
|
Номер |
Потребление |
Итого |
Скользящая |
Центрированная |
Оценка |
|
1 |
2 |
3 |
4 |
5 |
6 |
|
1 |
6,0 |
– |
– |
– |
– |
|
2 |
4,4 |
24,4 |
6,10 |
– |
– |
|
3 |
5,0 |
25,6 |
6,40 |
6,250 |
–1,250 |
|
4 |
9,0 |
26,0 |
6,50 |
6,450 |
2,550 |
|
5 |
7,2 |
27,0 |
6,75 |
6,625 |
0,575 |
|
6 |
4,8 |
28,0 |
7,00 |
6,875 |
–2,075 |
|
7 |
6,0 |
28,8 |
7,20 |
7,100 |
–1,100 |
|
8 |
10,0 |
29,6 |
7,40 |
7,300 |
2,700 |
|
9 |
8,0 |
30,0 |
7,50 |
7,450 |
0,550 |
|
10 |
5,6 |
31,0 |
7,75 |
7,625 |
–2,025 |
|
11 |
6,4 |
32,0 |
8,00 |
7,875 |
–1,475 |
|
12 |
11,0 |
33,0 |
8,25 |
8,125 |
2,875 |
|
13 |
9,0 |
33,6 |
8,40 |
8,325 |
0,675 |
|
14 |
6,6 |
33,4 |
8,35 |
8,375 |
–1,775 |
|
15 |
7,0 |
– |
– |
– |
– |
|
16 |
10,8 |
– |
– |
– |
– |
Таблица
расчета оценок сезонной компоненты в
аддитивной модели заполняется по
следующему правилу:
1
столбец
– известный номер квартала;
2
столбец
– известный объем потребляемой
электроэнергии(млн кВТ*ч);
3
столбец
– складываем последовательно значения
четырех ячеек 2 столбца и записываем их
на одну клетку ниже;
4
столбец
– каждое значение 3 столбца делим на 4
(период сезонных колебаний);
5
столбец
– складываем последовательно значения
двух ячеек 4 столбца, делим эту сумму на
2 и записываем на одну клетку ниже;
6
столбец
– из элементов 2 столбца вычитаем
элементы 5 столбца.
Рассчитаем
значения сезонной компоненты S
Для
этой цели составим следующую расчетную
таблицу 3, в которую последовательно
разместим данные из 6 столбца табл. 2.
Таблица
3- Расчет значений сезонной компоненты
в аддитивной модели
|
Показатель |
Год |
Номер |
|||
|
I |
II |
III |
IV |
||
|
1 |
– |
– |
–1,250 |
2,550 |
|
|
2 |
0,575 |
–2,075 |
–1,100 |
2,700 |
|
|
3 |
0,550 |
–2,025 |
–1,475 |
2,875 |
|
|
4 |
0,675 |
–1,775 |
– |
– |
|
|
Итого |
1,800 |
–5,875 |
–3,825 |
8,125 |
|
|
Средняя |
0,600 |
–1,958 |
–1,275 |
2,708 |
|
|
Скорректированная |
0,581 |
–1,977 |
–1,294 |
2,690 |
Средняя
оценка сезонной компоненты (![]() )
)
рассчитывается как итого за квартал
/3.
В
аддитивных моделях с сезонной компонентой
предполагается , что сезонные воздействия
за период взаимопогашаются. Это означает,
что сумма значений сезонной компоненты
по всем кварталам должна быть равна 0.
Для
данной модели имеем 0,600+ (–1,958) + (–1,275) +
2,708 = 0,075![]()
0.
Определим
корректирующий коэффициент k
=
0,075/4 = 0,01875.
Рассчитаем
скорректированные значения сезонной
компоненты, как разность между ее средней
оценкой и корректирующим коэффициентом
k:
![]()
k.
Проверим
условие равенства нулю суммы значений
сезонной компоненты: 0,581
– 1,977 – 1,294 + 2,690 = 0.
-
Подставим
значения скорректированной сезонной
компоненты в столбец С.
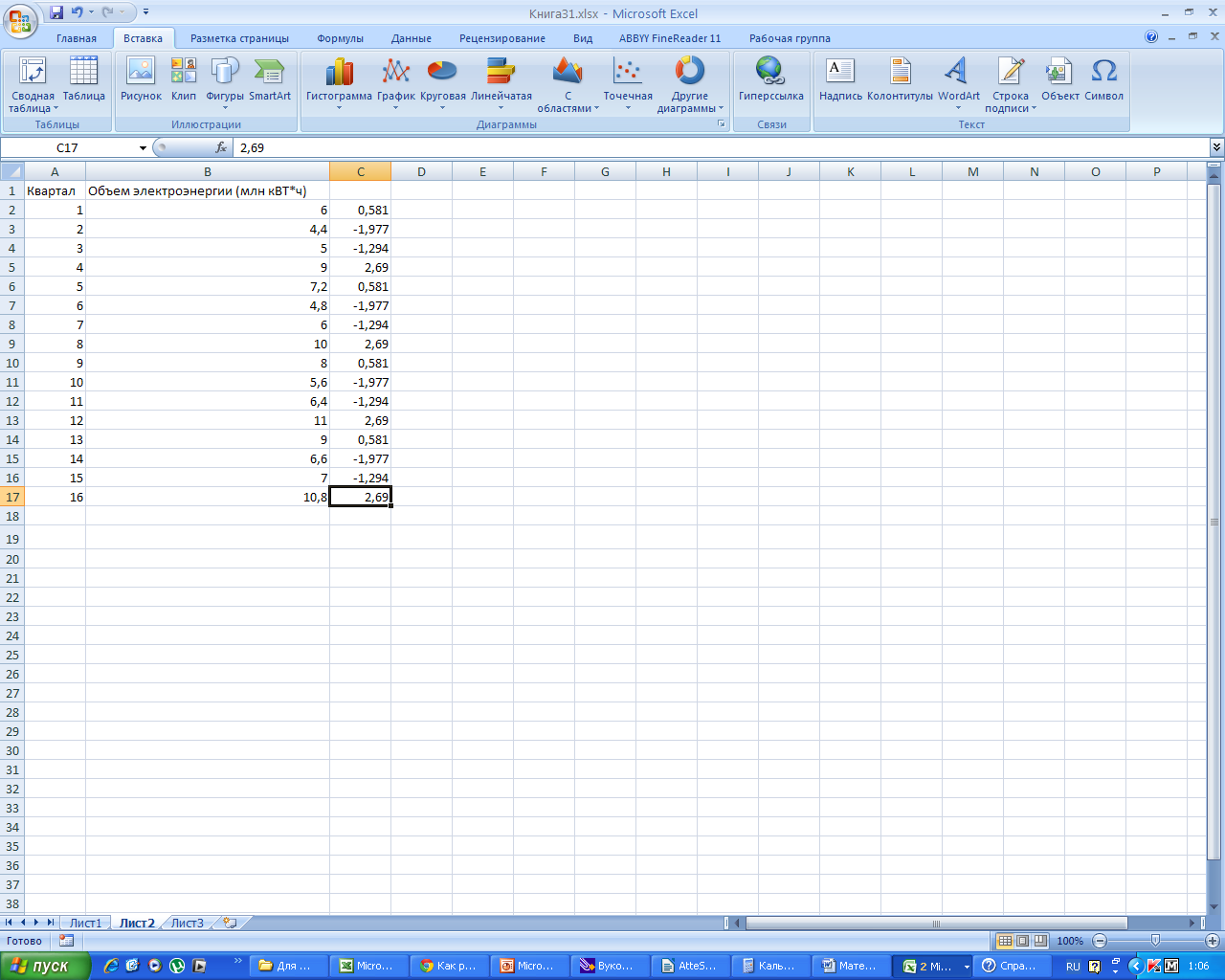
-
Заполняем
столбец D,
как разность В и С.
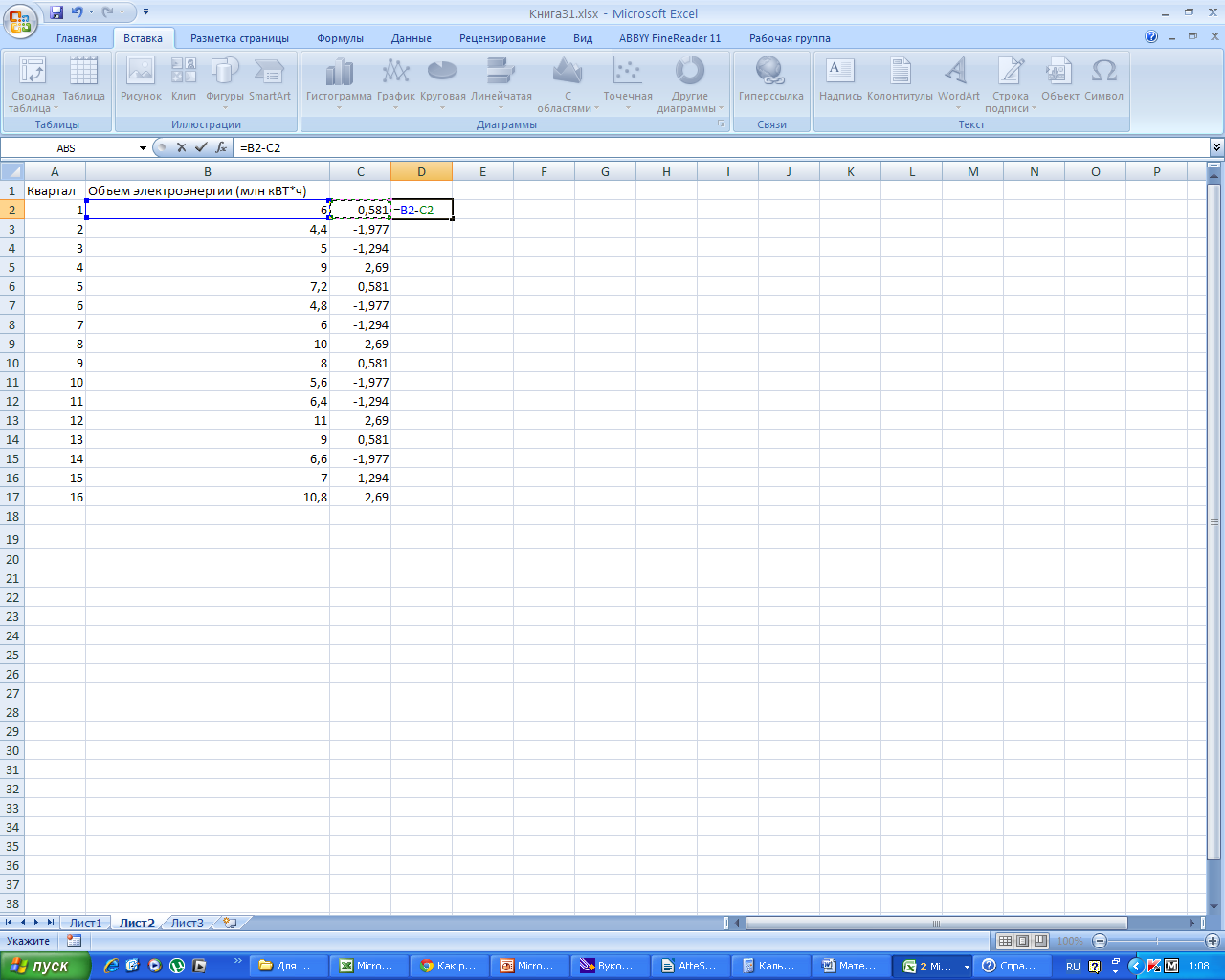
Получаем
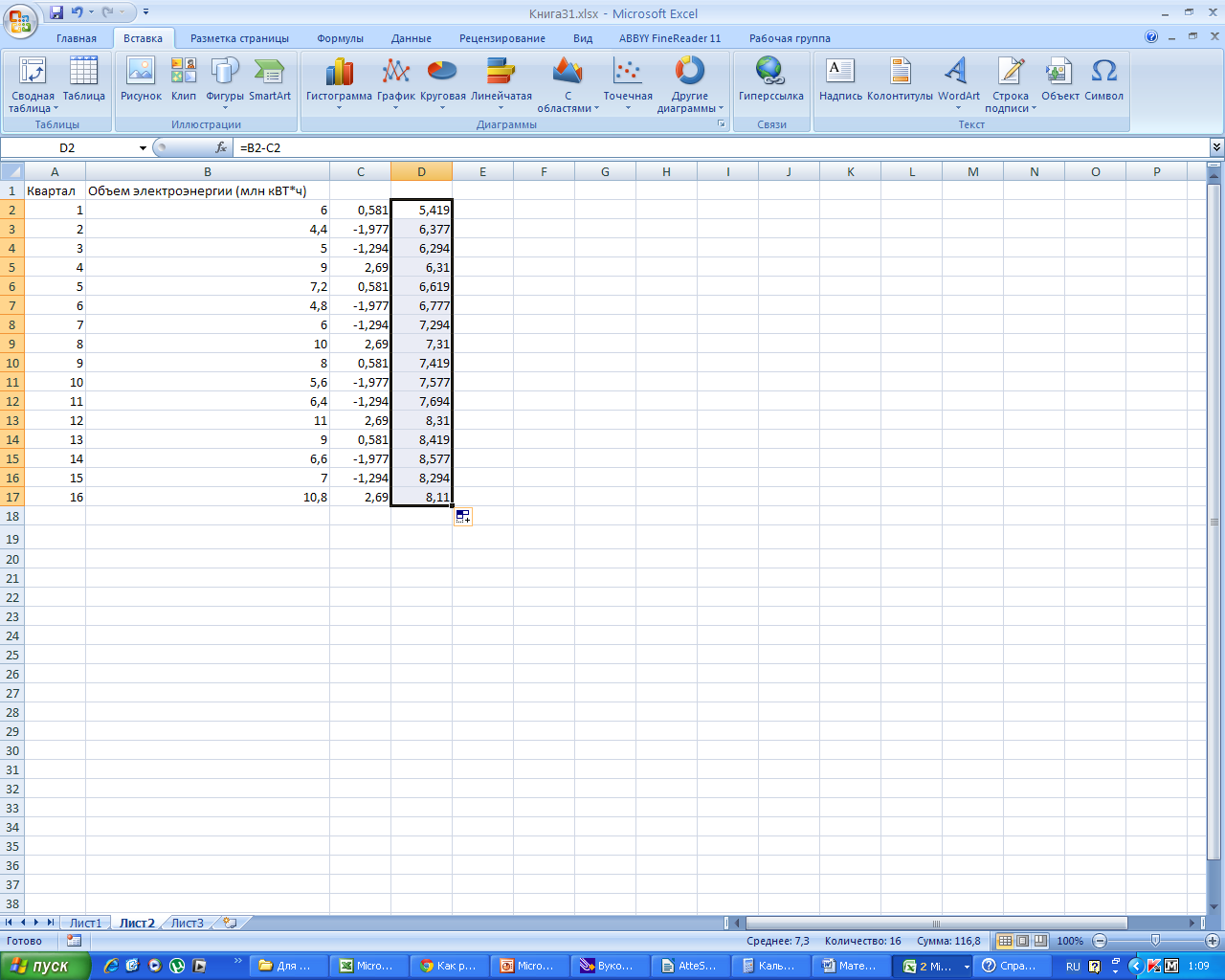
-
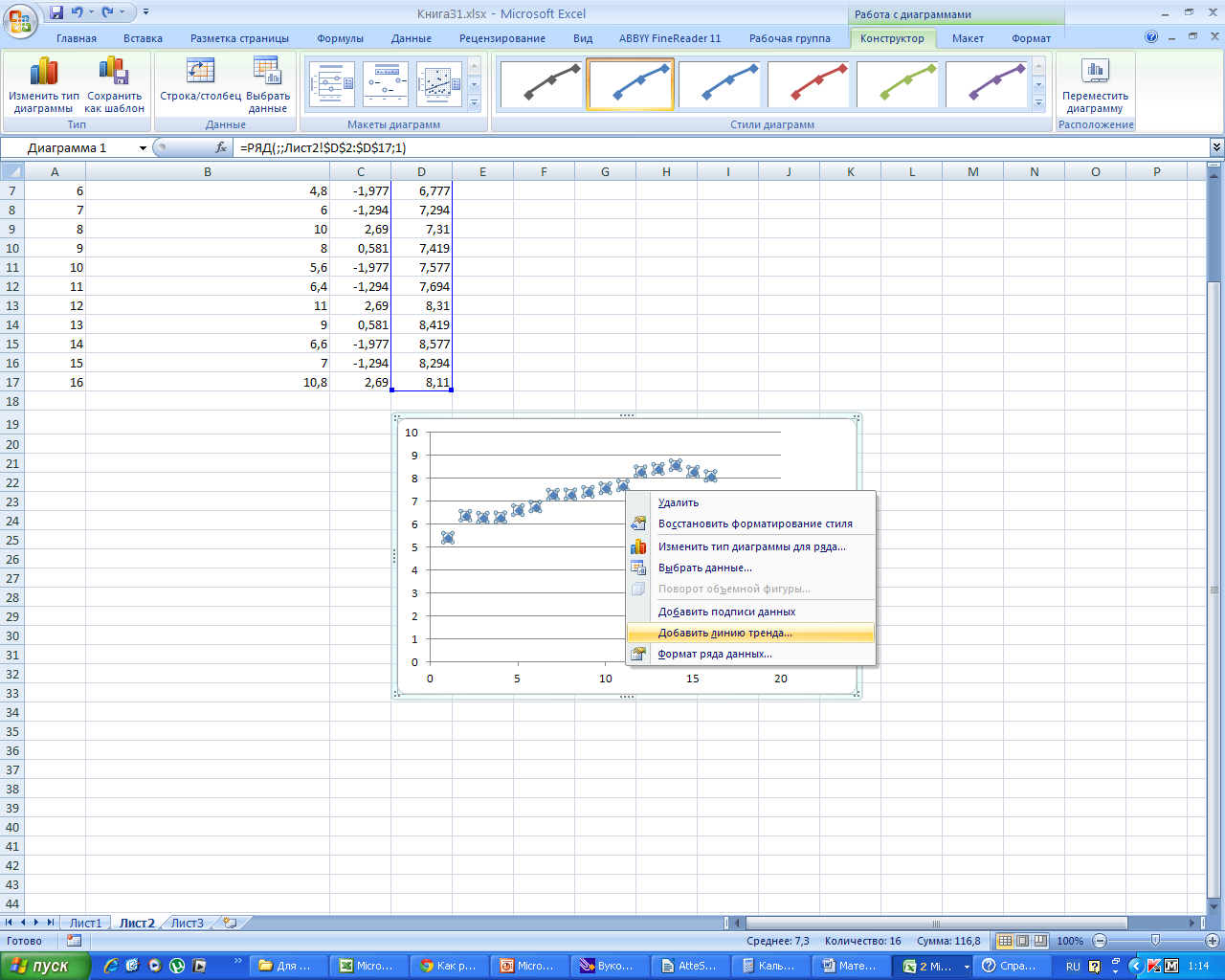
Пошагово
выбираем ту линию тренда, где наибольшее
значение имеет R2.
Для
этого ставим курсор на точки поля
корреляции и выбираем тренд, расставляя
галочки в окна, «показать уравнение на
диаграмме» и «поместить на диаграмму
величину достоверности аппроксимации».


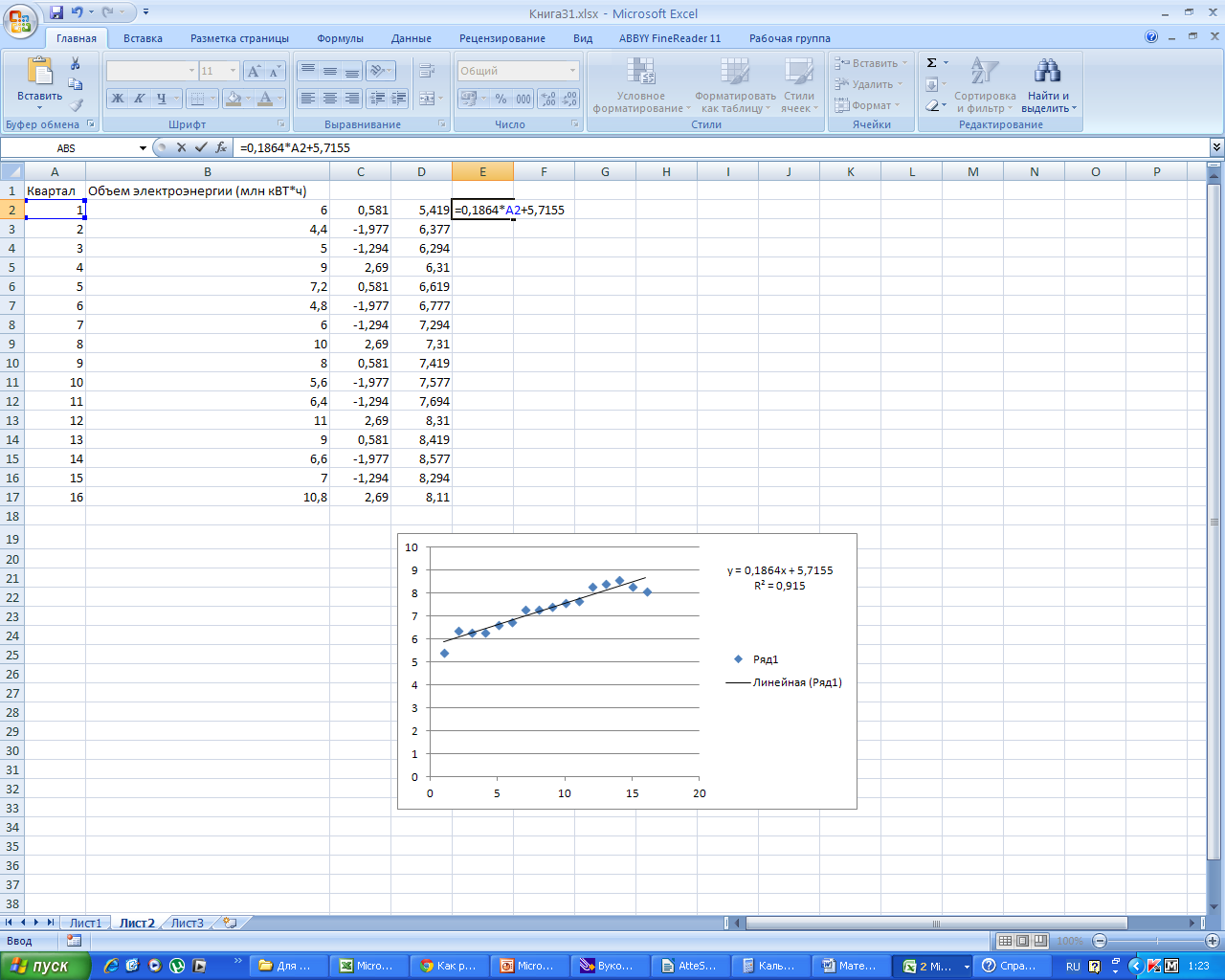
-
В
столбец Е вбиваем формулу для уравнения
тренда y=
0, 1864x
+ 5, 7155 и получаем расчетные значения
для тренда.

-
Заполним
столбец F,
как сумму C
и Е, и найдем ошибку аппроксимации.

Для
нахождения ошибки аппроксимации заполним
столбец G.
Для этого в столбец G
вставляем формулу

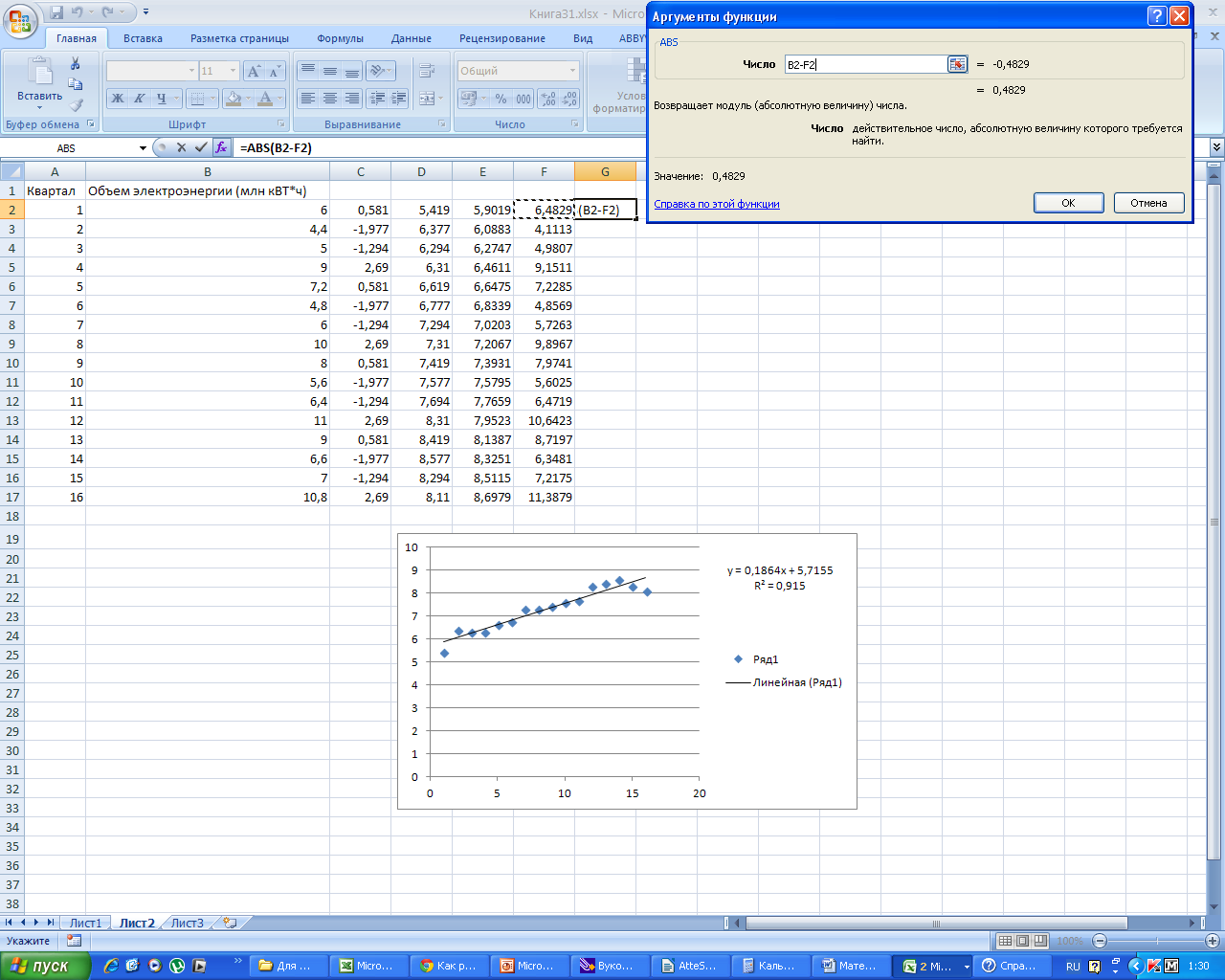
Получаем

Найдем
среднюю ошибку аппроксимации, заполнив
столбец Н. Для этого разделим G
на В и умножим на 100%.
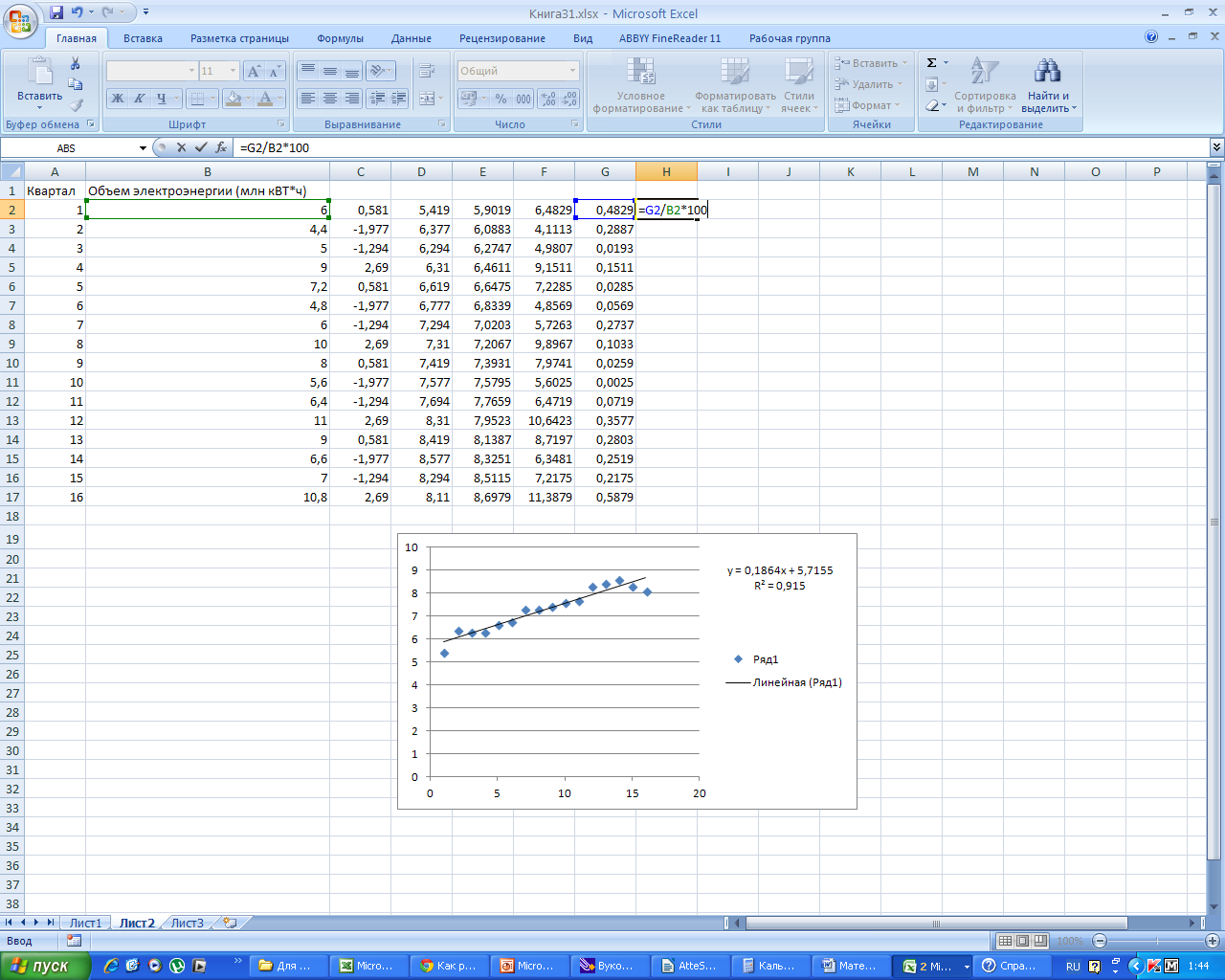
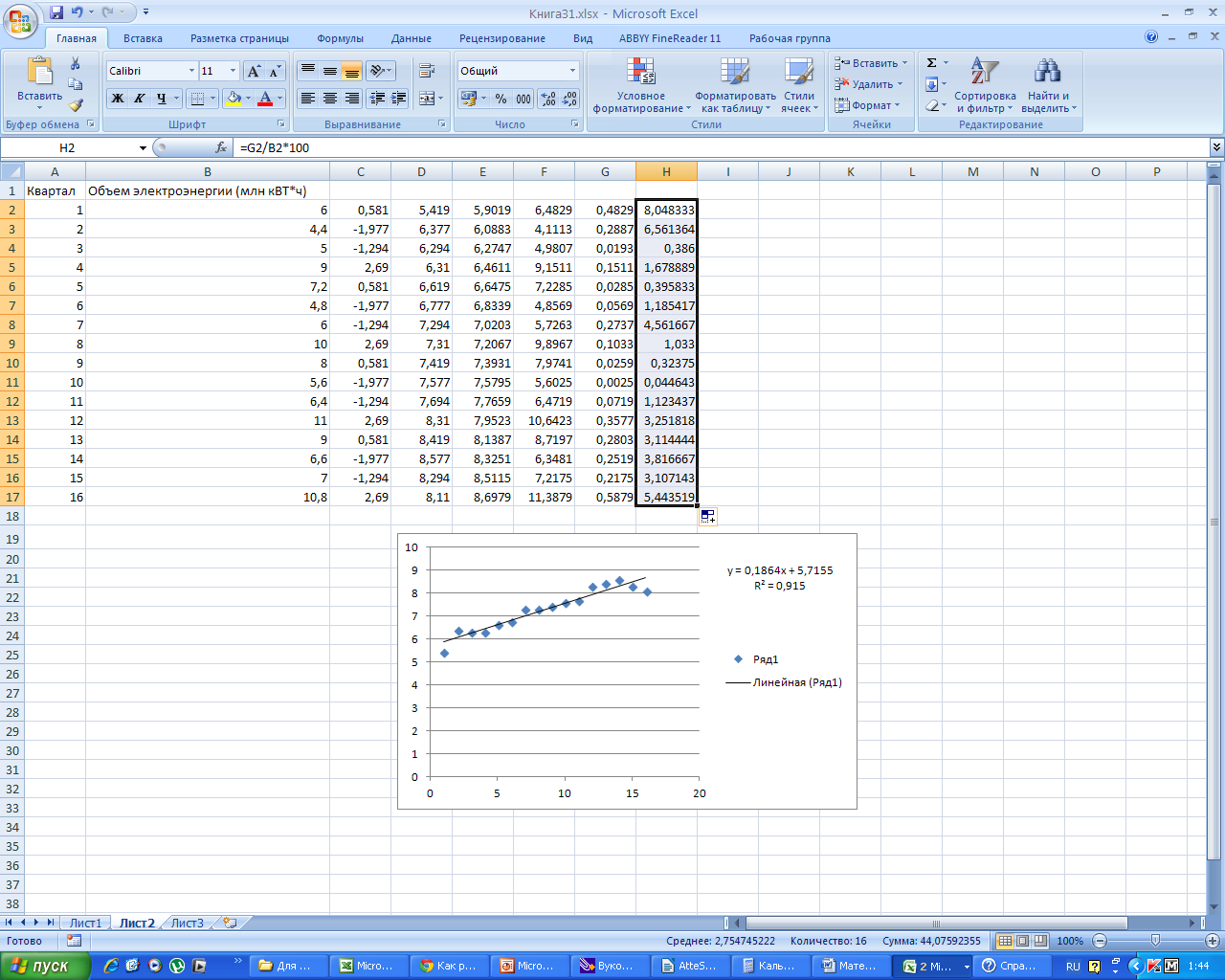


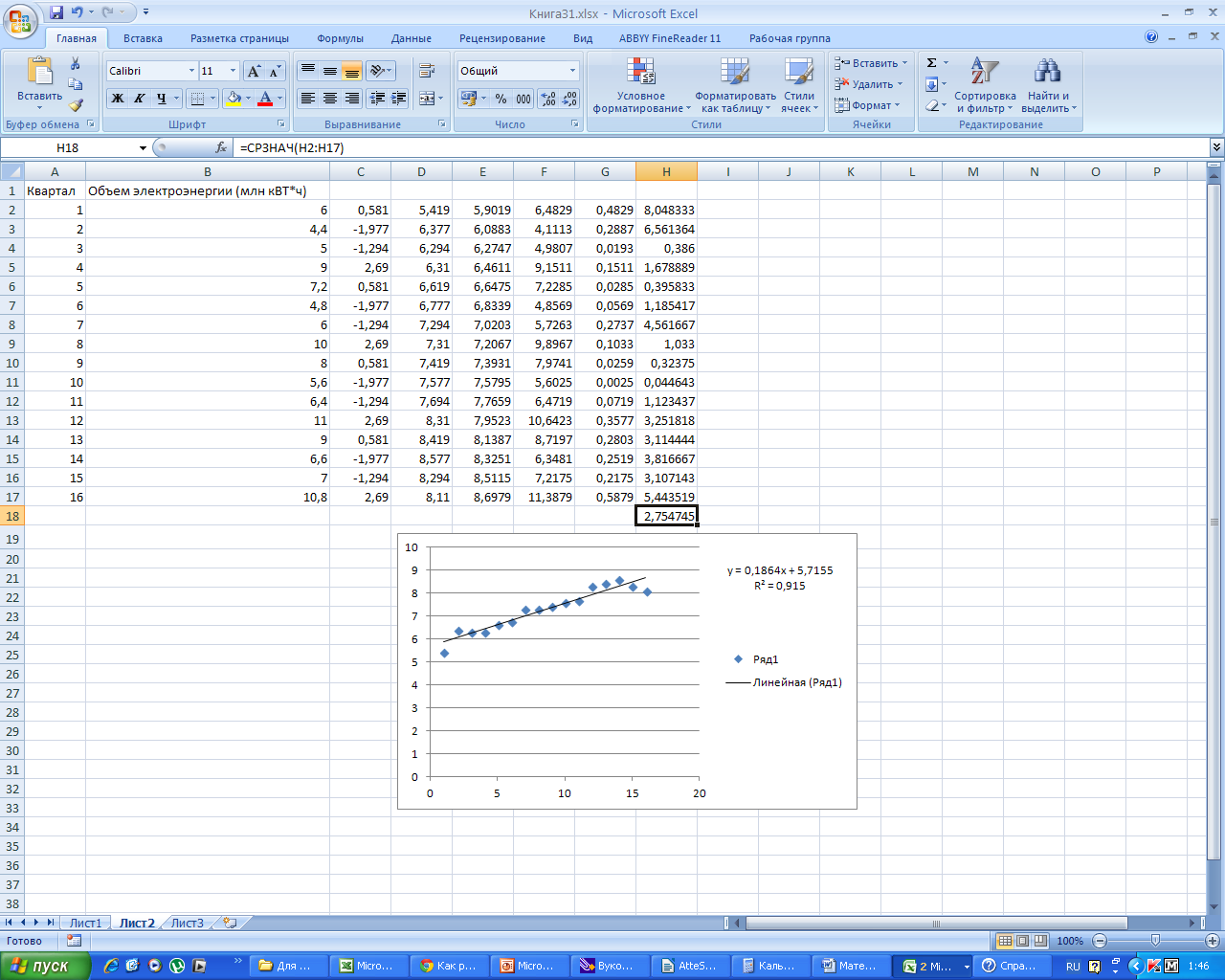
Таким
образом, заметим, что R2
= 0,915
0,75, средняя ошибка аппроксимации равна
2,75%< 3%. Значит, данная модель является
надежной.
Спрогнозируем
значения потребляемой электроэнергии
на следующий квартал. Для этого
воспользуемся вновь электронной
таблицей.

Заметим,
что полученное число 8,8843
млн. кВт/ч.
практически не отличается от полученного
ранее значения ![]() млн.
млн.
кВт/ч.
Приложение
2.
Соседние файлы в папке pravila
- #
- #
- #
- #
Аддитивная и мультипликативная модели временного ряда
Существует несколько подходов к анализу структуры временных рядов, содержащих сезонные или циклические колебания.
Простейший подход- расчет значений сезонной компоненты методом скользящей средней и построение аддитивной или мультипликативной модели временного ряда. Общий вид аддитивной модели следующий:
Эта модель предполагает, что каждый уровень временного ряда может быть представлен как произведение трендовой, сезонной и случайной компонент. Общий вид мультипликативной модели выглядит так:
Построение аддитивной и мультипликативной моделей сводится к расчету значений трендовой, циклической и случайной компонент для каждого уровня ряда.
Процесс построения модели включает в себя следующие шаги.
1. Выравнивание исходного ряда методом скользящей средней.
3. Устранение сезонной компоненты из исходных уровней ряда и получение выровненных данных в аддитивной или мультипликативной модели.
4. Аналитическое выравнивание уровней и расчет значений тренда с использованием полученного уравнения тренда.
Если полученные значения ошибок не содержат автокорреляции, ими можно заменить исходные уровни ряда и в дальнейшем использовать временной ряд ошибок для анализа взаимосвязи исходного ряда и других временных рядов.[5, c. 67]
Одним из таких упрощений является свойство стационарности. Будем считать, что поведение множества случайных величин с вероятностной точки зрения не зависит от времени.
Практически мы интересуемся вероятностями, которые связаны с конечным числом случайных величин. Эти вероятности включают в себя функцию совместного распределения. [24, c. 88]
1.9 Применение быстрого преобразования Фурье к стационарному временному ряду
Одно из назначений преобразования Фурье- выделять частоты циклических составляющих временного ряда, содержащего случайную компоненту.
Пусть число данных N представимо в виде N = N1 N2. Тогда можно записать
Отметим, что aN – j = aj и bN – j = — bj . Искомые коэффициенты являются соответственно действительной и мнимой частями суммы:




и ,
то существует около N1N2/2 = N/2 таких пар. После этого находятся действительная и мнимая части суммы (1.9.1):
для j = 0,1, . . ., [N/2]. Число операций умножения приближённо равно N2N в первых суммах и 2N1N во вторых суммах, так что число операций умножения в целом составляет примерно N (N2 + 2N1). В то же время число произведений в определении коэффициентов aj и bj , j=0,1, . . ., [N/2] примерно равно N 2 . [20, c.98], [21, c.78]
Раздел: Экономика
Количество знаков с пробелами: 33627
Количество таблиц: 0
Количество изображений: 0

Мнение эксперта
Знайка, самый умный эксперт в Цветочном городе
Если у вас есть вопросы, задавайте их мне!
Задать вопрос эксперту
Проверка гипотезы о наличии автокорреляции остатков 0 d1 d2 2 4-d2 4-d1 4 Положи- Зона Отсутствие Зона Отрицательная неопре- автокорренеопре- тельная автокор. Если же вы хотите что-то уточнить, я с радостью помогу!
Преобразование уровней ряда в новые
переменные (метод последовательных
разностей, метод отклонений от трендов)
Элиминирование влияния фактора времени на Yt
и Xt (метод включения в модель регрессии
фактора времени)
Построение аддитивной модели временного ряда
Отметим, что aN – j = aj и bN – j = — bj . Искомые коэффициенты являются соответственно действительной и мнимой частями суммы:
Построение аддитивной модели.
1 шаг. Выравнивание уровней ряда. Просуммируем уровни ряда за каждые четыре квартала со сдвигом на один момент времени. Разделив полученные суммы на 4, найдем скользящие средние. Найдем центрированные скользящие средние как средние значения из двух последовательных скользящих средних.
2 шаг. Расчет сезонной компоненты S. Найдем разность между уровнями и центрированными скользящими средними. Расчет средней оценки сезонной компоненты для каждого квартала за все годы. Расчет скорректированной сезонной компоненты.Моделирование сезонных колебаний:Аддитивная модель: .
Оценка сезонной компоненты за каждый квартал: . Средняя оценка сезонной компоненты для квартала за все годы: . Скорректированная сезонная компонента:
3 шаг. Устранение сезонной компоненты S.Вычтем скорректированное значение сезонной компоненты из каждого уровня исходного временного ряда. Получим: T+E=Y-S.
4 шаг. Расчет значений тренда. Проведем аналитическое выравнивание ряда (T+E) с помощью линейного тренда. Рассчитаем значения T для каждого момента времени по уравнению тренда.
5 шаг. Расчет значений T+S. Прибавим к уровням T значения сезонной компоненты (S) для соответствующих кварталов.
6 шаг. Расчет абсолютной ошибки. Выполним расчет ошибки для каждого уровня ряда по формуле: E=Y-(T+S). Расчет суммы квадратов абсолютных ошибок и ее сравнение с общей суммой квадратов отклонений уровней ряда.
1 шаг. Выравнивание уровней ряда. Просуммируем уровни ряда за каждые четыре квартала со сдвигом на один момент времени. Разделив полученные суммы на 4, найдем скользящие средние. Найдем центрированные скользящие средние как средние значения из двух последовательных скользящих средних.
3 шаг. Устранение сезонной компоненты S. Разделим каждый уровень исходного временного ряда на скорректированное значение сезонной компоненты. Получим: T*E=Y/S.
4 шаг. Расчет значений тренда. Проведем аналитическое выравнивание ряда (T*E) с помощью линейного тренда. Рассчитаем значения T для каждого момента времени по уравнению тренда.
5 шаг. Расчет значений T+S. Умножим уровни T на значения сезонной компоненты (S) для соответствующих кварталов.
6 шаг. Расчет абсолютной ошибки. Выполним расчет ошибки для каждого уровня ряда по формуле: E=Y/(T*S). Расчет суммы квадратов абсолютных ошибок и ее сравнение с общей суммой квадратов отклонений уровней ряда.
2. Каковы основные компоненты уровней временного ряда?
3. В чем состоит основная задача эконометрического исследования временного ряда?
4. Как определяется автокорреляция остатков во временных рядах?
7. Что такое коррелограмма? Что выявляют при помощи анализа коррелограммы?
8. Как сформулировать вывод о структуре временного ряда?
9. Какие методы применяются для выявления основной тенденции ряда?
Задача 1. Имеются следующие данные об урожайности пшеницы за 12 лет:
| 16,3 | 20,2 | 17,1 | 9,7 | 15,3 | 16,3 | 19,9 | 14,4 | 18,7 | 20,7 | 19,5 | 21,1 | |
1) определить среднее значение, среднее квадратическое отклонение и коэффициенты автокорреляции (для лагов 1,2) временного ряда;
2) провести сглаживание исходного временного ряда методом скользящих средних, используя среднюю арифметическую с интервалом сглаживания:
а) 3;
б) 4;
3) записать уравнение тренда ряда, полагая, что он линейный, и проверить его значимость на уровне 0,05.
Задача 2. Данные, отражающие динамику роста доходов на душу населения за восемь лет, приведены в таблице:
Задание: определить точечный прогноз дохода населения по линейному тренду на 9 год.
Анализ временных рядов. (Тема 5) — презентация онлайн
Trend — тенденция, тренд на период τ, tτ, зависит от рассчитанного сглаженного значения за предыдущий и текущий периоды (sτ и sτ-1) и от предыдущей тенденции:
tτ = β(sτ-sτ-1) + (1-β)tτ-1
Мнение эксперта
Знайка, самый умный эксперт в Цветочном городе
Если у вас есть вопросы, задавайте их мне!
Задать вопрос эксперту
Обратите внимание, что при сглаживании не имеет значения, совпадает график среднего с графиком данных или нет, целью является построение правильной формы. Если же вы хотите что-то уточнить, я с радостью помогу!
Smooth — сглаживание, сглаженный уровень на период τ, sτ, зависит от значения уровня на текущий период (Dτ), тренда за предыдущий период (tτ-1) и рассчитанного сглаженного значения на предыдущий период (sτ-1):
sτ = αDτ + (1 — α)(sτ-1 + tτ-1)
Построение аддитивной модели временного ряда.
Линейный тренд
yˆt a b t
Гипербола
yˆ t a b / t
Экспонента
Степенной тренд
ˆt e
y
a b t l
ˆyt a t b
Парабола k-го порядка
yˆ t a b1 t b2 t . bk t
2
k
| 16,3 | 20,2 | 17,1 | 9,7 | 15,3 | 16,3 | 19,9 | 14,4 | 18,7 | 20,7 | 19,5 | 21,1 | |
- Авторы
- Руководители
- Файлы работы
- Наградные документы
Приходько Д.С. 1
1МБОУ «Гимназия №3″ 9″А» класс
Белова Т.А. 1
1МБОУ «Гимназия №3»
Текст работы размещён без изображений и формул.
Полная версия работы доступна во вкладке «Файлы работы» в формате PDF
ВВЕДЕНИЕ
В настоящее время статистические методы прогнозирования заняли видное место в экономической практике. Широкому внедрению методов анализа и прогнозирования данных способствовало появление персональных компьютеров. Распространение статистических программных пакетов позволило сделать доступными и наглядными многие методы обработки данных.
Теперь уже не требуется проводить вручную трудоемкие расчеты, строить таблицы и графики – всю эту черновую работу выполняет компьютер. Человеку же остается исследовательская, творческая работа: постановка задачи, выбор методов прогнозирования, оценка качества полученных моделей, интерпретация результатов. Для этого необходимо иметь определенную подготовку в области статистических методов обработки данных и прогнозирования.
Поэтому мы решили изучить основные статистические методы анализа одномерных временных рядов и прогнозирования и возможность их реализации в электронной таблице Excel.
Цель исследования: освоение основных понятий, математических моделей и методов для решения задач прогнозирования различных процессов и явлений, их практическая реализация в электронной таблице Excel.
Задачи исследования: изучить основные понятия теории временных рядов, статистические методы прогнозирования, научиться применять полученные знания для построения прогнозов.
Актуальность выбранной темы очевидна. Необходимость предвидеть будущее осознавалась во все времена. Но особенно сильно роль прогнозирования возросла в наши дни, при стремительных темпах развития общества, науки и техники, производства и производственных отношений. Сегодня прогнозов, основанных на интуиции, уже явно недостаточно. Теперь необходимо прогнозирование, основанное на объективных закономерностях, на использовании математического аппарата, проводимое на основе научных методов и моделей, на обработке первичных данных с помощью информационных технологий.
ОСНОВНАЯ ЧАСТЬ
В современных условиях управленческие решения должны приниматься лишь на основе тщательного анализа имеющейся информации. Для решения задач, связанных с анализом данных при наличии случайных воздействий, предназначен мощный аппарат прикладной статистики, составной частью которого являются статистические методы прогнозирования. Эти методы позволяют выявлять закономерности на фоне случайностей, делать обоснованные прогнозы и оценивать вероятность их выполнения.
Статистические методы прогнозирования
1.1. Экономические прогнозы
Под прогнозом понимается научно обоснованное описание возможных состояний объектов в будущем, а также альтернативных путей и сроков достижения этого состояния. Процесс разработки прогнозов называется прогнозированием (от греч. prognosis – предвидение, предсказание).
Важной характеристикой является время (период) упреждения прогноза – отрезок времени от момента, для которого имеются последние статистические данные об изучаемом объекте, до момента, к которому относится прогноз.
По времени упреждения экономические прогнозы делятся на:
оперативные (с периодом упреждения до одного месяца);
краткосрочные (период упреждения – от одного, нескольких месяцев до года);
среднесрочные (период упреждения более 1 года, но не превышает 5 лет);
долгосрочные (с периодом упреждения более 5 лет).
Прогнозирование экономических явлений и процессов включает в себя следующие этапы:
1. постановка задачи и сбор необходимой информации;
2. первичная обработка исходных данных;
3. определение круга возможных моделей прогнозирования;
4. оценка параметров моделей;
5. исследование качества выбранных моделей, адекватности их реальному процессу и выбор лучшей из моделей;
6. построение прогноза;
7. содержательный анализ полученного прогноза.
1.2. Виды временных рядов. Требования, предъявляемые к исходной информации
Статистическое описание развития экономических процессов во времени осуществляется с помощью временных рядов.
Временным (динамическим) рядом называется последовательность значений показателя (признака), упорядоченная в хронологическом порядке, т.е. в порядке возрастания временного параметра. Отдельные наблюдения временного ряда называются уровнями этого ряда.
Каждый временной ряд содержит два элемента: значения времени; соответствующие им значения уровней ряда.
В качестве показателя времени в рядах динамики могут указываться либо определенные моменты времени (даты), либо отдельные периоды (сутки, месяцы, кварталы, полугодия, годы и т.д.). В зависимости от характера временного параметра ряды делятся на моментные и интервальные.
В моментных рядах динамики уровни характеризуют значения показателя по состоянию на определенные моменты времени. В интервальных рядах уровни характеризуют значение показателя за определенные интервалы (периоды) времени.
Важной особенностью интервальных рядов динамики абсолютных величин является возможность суммирования их уровней. Суммирование уровней моментного ряда динамики не практикуется, т.к. полученные накопленные итоги лишены всякого смысла. Моментные ряды динамики, в отличие от интервальных не обладают свойством аддитивности (термин происходит от английского глагола to add – добавлять).
При исследовании моментного ряда динамики определенный смысл имеет расчет разностей уровней, характеризующих изменение показателя за некоторый отрезок времени.
Успешность статистического анализа развития процессов во времени во многом зависит от правильного построения временных рядов.
Большое значение для дальнейшего исследования процесса имеет выбор интервалов между соседними уровнями ряда. Удобнее всего иметь дело с равноотстоящими друг от друга уровнями ряда.
Одним из важнейших условий, необходимых для правильного отражения временным рядом реального процесса развития, является сопоставимость уровней ряда. Для несопоставимых величин неправомерно проводить исследование динамики.
Чаще всего несопоставимость встречается в стоимостных показателях, что вызвано изменением цен в разные периоды времени, поэтому на практике осуществляют пересчет уровней в сопоставимые цены (цены одного периода).
Уровни рядов динамики могут содержать аномальные значения или «выбросы». Часто появление таких значений может быть вызвано ошибками при сборе, записи и передаче информации. Выявление, исключение таких значений, замена их истинными или расчетными является необходимым этапом первичной обработки данных, т.к. применение математических методов к «засоренной» информации приводит к искажению результатов анализа.
Соответствие исходной информации всем указанным требованиям проверяется на этапе предварительного анализа временных рядов. Лишь после этого переходят к расчету и анализу основных показателей динамики развития, построению моделей прогнозирования, получению прогнозных оценок.
1.3. Компоненты временных рядов
В практике исследования динамики явлений и прогнозирования принято считать, что значения уровней временных рядов экономических показателей могут содержать следующие компоненты (составные части или структурно-образующие элементы):
тренд;
сезонную компоненту;
циклическую компоненту;
случайную составляющую.
Под трендом понимают изменение, определяющее общее направление развития, основную тенденцию временного ряда. Это систематическая составляющая долговременного действия.
Наряду с долговременными тенденциями во временных рядах экономических процессов часто имеют место более или менее регулярные колебания – периодические составляющие рядов динамики.
Если период колебаний не превышает одного года, то их называют сезонными. Чаще всего причиной их возникновения считаются природно-климатические условия.
При большем периоде колебания считают, что во временных рядах имеет место циклическая составляющая. Примерами могут служить демографические, инвестиционные и другие циклы.
Если из временного ряда удалить тренд и периодические составляющие, то останется нерегулярная компонента.
Экономисты разделяют факторы, под действием которых формируется нерегулярная компонента, на 2 вида:
факторы резкого, внезапного действия;
текущие факторы.
Факторы первого вида (например, стихийные бедствия, эпидемии и др.), как правило, вызывают более значительные отклонения. Иногда такие отклонения называют катастрофическими колебаниями.
Факторы второго вида вызывают случайные колебания, являющиеся результатом действия большого числа побочных причин. Влияние каждого из текущих факторов незначительно, но ощущается их суммарное воздействие.
Если временной ряд представляется в виде суммы соответствующих компонент, то полученная модель носит название аддитивной (1.1), если в виде произведения – мультипликативной (1.2) или смешанного типа (1.3):
; (1)
; (2)
, (3)
где: – уровни временного ряда;
– трендовая составляющая;
– сезонная компонента;
– циклическая компонента;
– случайная компонента.
Решение любой задачи по анализу и прогнозированию временных рядов начинается с построения графика исследуемого показателя. Иногда на стадии графического анализа можно определить характер сезонных колебаний: аддитивный или мультипликативный. Отличительной особенностью аддитивной модели является то, что амплитуда сезонных колебаний, отражающая отклонения от тренда или среднего, остается примерно постоянной, неизменной во времени.
1.4. Сглаживание временных рядов с помощью простых скользящих средних
Распространенным приемом при выявлении и анализе тенденции развития является сглаживание временного ряда. Суть различных приемов сглаживания сводится к замене фактических уровней временного ряда расчетными уровнями, которые в меньшей степени подвержены колебаниям. Это способствует более четкому проявлению тенденции развития.
Мы рассмотрим методы сглаживания временных рядов с помощью скользящих средних. Скользящие средние позволяют сгладить как случайные, так и периодические колебания, выявить имеющуюся тенденцию в развитии процесса, и поэтому служат важным инструментом при фильтрации компонент временного ряда.
Алгоритм сглаживания по простой скользящей средней может быть представлен в виде следующей последовательности шагов:
1. Определяют длину интервала сглаживания , включающего в себя последовательных уровней ряда ( ). При этом надо иметь в виду, что чем шире интервал сглаживания, тем в большей степени взаимопогашаются колебания, и тенденция развития носит более плавный, сглаженный характер. Чем сильнее колебания, тем шире должен быть интервал сглаживания.
2. Разбивают весь период наблюдения на участки, при этом интервал сглаживания как бы скользит по ряду с шагом, равным 1.
3. Рассчитывают средние арифметические из уровней ряда, образующих каждый участок.
4. Заменяют фактические значения ряда, стоящие в центре каждого участка, на соответствующие средние значения.
При этом удобно брать длину интервала сглаживания в виде нечетного числа: , т.к. в этом случае полученные значения скользящей средней приходятся на средний член интервала.
Процедура сглаживания приводит к устранению периодических колебаний во временном ряду, если длина интервала сглаживания берется равной или кратной периоду колебаний.
Для устранения сезонных колебаний часто требуется использовать четырех- и двенадцатичленные скользящие средние, но при этом не будет выполняться условие нечетности длины интервала сглаживания.
При четной базе в сглаживаемой серии отсутствует член, соответствующий среднему промежутку времени. Нет промежутка, которому можно корректно приписать результат.
В таких ситуациях используют двухэтапное сглаживание. На первом этапе проводят сглаживание при четной длине интервала сглаживания (скажем, при ). Среднего промежутка времени здесь нет, и результат приписывают не точно середине, а со сдвигом на полпериода вперед или назад (например, назад). После этого проводят повторное сглаживание уже сглаженного ряда при длине интервала, который во всех случаях равен 2. База опять четная, и на этот раз результат опять сдвигают на полпериода, но в противоположную сторону (в нашем примере вперед). В итоге такой двухэтапной процедуры окончательный результат оказывается центрированным корректно.
При использовании скользящей средней с длиной активного участка первые и последние уровней ряда сгладить нельзя, их значения теряются.
1.5. Прогнозирование развития по линии тренда
Под тенденцией развития понимают общее направление развития, долговременную эволюцию. На практике для описания тенденции развития явления широко используются модели кривых роста, представляющие собой различные функции времени . При таком подходе изменение исследуемого показателя связывают лишь с течением времени; считается, что влияние других факторов несущественно или косвенно сказывается через фактор времени.
Прогнозирование на основе модели кривой роста базируется на экстраполяции, т.е. на продлении в будущее тенденции, наблюдавшейся в прошлом. При этом предполагается, что во временном ряду присутствует тренд, характер развития показателя обладает свойством инерционности, сложившаяся тенденция не должна претерпевать существенных изменений в течение периода упреждения.
Прогнозирование на основе кривых роста предполагает выбор формы кривой, оценивание ее параметров, проверку адекватности, а также точечный и интервальный прогноз с помощью этой функции.
Наиболее распространенным вариантом кривой роста является полином:
, (4)
где
– параметры многочлена,
– независимая переменная (время), .
Коэффициенты полиномов невысоких степеней могут иметь конкретную интерпретацию в зависимости от содержания динамического ряда. Например, их можно трактовать как скорость роста ( ), ускорение роста ( ), изменение ускорения ( ), начальный уровень ряда при ( ).
Обычно в экономических исследованиях применяются полиномы не выше третьего порядка.
Оценки параметров в модели (4) определяются методом наименьших квадратов. Суть его состоит в нахождении таких параметров, при которых сумма квадратов отклонений расчетных значений уровней от фактических значений, была бы минимальной. Таким образом, эти оценки находятся в результате минимизации выражения:
где
– фактическое значение уровня временного ряда;
– расчетное значение;
– длина временного ряда.
В качестве другого варианта кривой роста можно рассмотреть простую показательную кривую, которая имеет вид:
. (6)
Если b, то кривая растет вместе с ростом , и падает, если . Параметр характеризует начальные условия развития, а параметр b – постоянный темп роста.
Существует несколько практических подходов, облегчающих процесс выбора формы кривой роста. Наиболее простой путь – визуальный анализ, опирающийся на изучение графического изображения временного ряда. Подбирают такую кривую роста, форма которой соответствует фактическому развитию процесса.
На практике чаще всего к выбору формы кривой подходят исходя из значений критерия, в качестве которого принимают сумму квадратов отклонений фактических значений уровней от расчетных, получаемых выравниванием. Из рассматриваемых кривых предпочтение будет отдано той, которой соответствует минимальное значение критерия, т.к. чем меньше значение критерия, тем ближе к кривой ложатся данные наблюдений.
Также в качестве критерия выбора кривой роста используется средняя квадратическая ошибка:
(7)
где
– фактическое значение уровня ряда;
– расчетное значение уровня ряда, полученное по модели;
– длина ряда.
Средняя квадратическая ошибка всегда имеет положительное значение, которое уменьшается по мере приближения ошибки к нулю. Большее значение показывает больший разброс значений в представленном множестве со средней величиной множества; меньшее значение, соответственно, показывает, что значения в множестве сгруппированы вокруг среднего значения.
Заключительным этапом применения кривых роста является экстраполяция тенденции на базе выбранного уравнения. Прогнозные значения исследуемого показателя вычисляют путем подстановки в уравнение кривой значений времени , соответствующих периоду упреждения. Полученный таким образом прогноз называют точечным, так как для каждого момента времени определяется только одно значение прогнозируемого показателя.
На практике в дополнении к точечному прогнозу желательно определить границы возможного изменения прогнозируемого показателя, задать «вилку» возможных значений прогнозируемого показателя, т.е. вычислить прогноз интервальный.
Несовпадение фактических данных с точечным прогнозом, полученным путем экстраполяции тенденции по кривым роста, может быть вызвано:
1. субъективной ошибочностью выбора вида кривой;
2. погрешностью оценивания параметров кривых;
3. погрешностью, связанной с отклонением отдельных наблюдений от тренда, характеризующего некоторый средний уровень ряда на каждый момент времени.
Погрешность, связанная со вторым и третьим источником, может быть отражена в виде доверительного интервала прогноза. Границы доверительного интервала, учитывающего неопределенность, связанную с положением тренда, и возможность отклонения от этого тренда, упрощенно определяется в виде:
, (8)
где
– расчетное значение уровня ряда, полученное по модели,
– средняя квадратическая ошибка,
– одно из чисел: 1, 2 или 3. При границы доверительного интервала обеспечивают приблизительно 68% надежность прогноза, при обеспечивается 95% надежность, при обеспечивается 99% надежность.
Построение модели сезонности с использование электронной таблицы Excel
В настоящее время существует большое количество программного обеспечения, специализирующегося именно на прогнозировании. Но и обычная электронная таблица Excel имеет в своем арсенале инструменты для выполнения прогнозирования, которые по своей эффективности мало чем уступают профессиональным программам. В данном разделе нашей работы мы выясним, что это за инструменты и постоим модель сезонности на практике.
В качестве исходных данных возьмем данные по объему перевозки пассажиров за 2019-2021 года.
Таблица 1.
Объем перевозки пассажиров за 2019-2021 года
|
Год |
Квартал |
Данные |
|
2019 |
1 кв. |
464,39 |
|
2 кв. |
369,45 |
|
|
3 кв. |
350,3 |
|
|
4 кв. |
199,62 |
|
|
2020 |
1 кв. |
809,63 |
|
2 кв. |
440,88 |
|
|
3 кв. |
501,51 |
|
|
4 кв. |
327,26 |
|
|
2021 |
1 кв. |
842,55 |
|
2 кв. |
715,45 |
|
|
3 кв. |
813,8 |
|
|
4 кв. |
545,1 |
Задача прогнозирования заключается в том, чтобы вычислить прогнозные значения квартальных объемов перевозок за 2022 года при условии, что сохранятся существующие тенденции.
Как мы знаем решение любой задачи по анализу и прогнозированию временных рядов начинается с построения графика исследуемого показателя. Для этого перенесем исходные данные в Excel и построим график.
Рис. 1. Диаграмма «Данные по перевозкам»
Данный график наглядно демонстрируют устойчивые сезонные колебания при повышающемся тренде.
При изучении сезонности имеют дело с периодическим воздействием, связанным с календарным циклом. Эти воздействия рассматриваются как внешние по отношению к основным причинам, характеризующим поведение системы. Поэтому при изучении ряда сезонные колебания отделяют от тренда.
Построение прогноза предполагает:
Выявление обобщенных характеристик циклических колебаний.
Расчет трендового прогноза, выражающего общую тенденцию ряда.
Совмещение трендового прогноза с характеристиками циклических колебаний.
Такое построение может быть основано на аддитивной модели или на мультипликативной модели.
В обеих моделях (1), (3) предполагается, что исходный ряд данных представляет собой комбинацию трех составляющих:
– трендовая составляющая, характеризующая основную долговременную тенденцию ряда;
– циклическая (обычно сезонная) составляющая, характеризующая регулярно повторяющиеся изменения исходного ряда;
– остаточная составляющая, отражающая случайные воздействия (ее называют также ошибкой модели).
2.1. Построение аддитивной модели
Аддитивная модель предполагает, что к тренду ряда прибавляется циклическая составляющая в виде периодически изменяющегося дополнительного слагаемого, принимающего положительные и отрицательные значения. Значения, лежащие на линии тренда, в связи с этим увеличиваются в одни периоды времени (циклическая составляющая для таких периодов положительна) и уменьшаются в другие периоды времени (циклическая составляющая отрицательна). Средняя величина всех таких слагаемых, входящих в циклическую составляющую, за время одного цикла равна 0.
Пошаговая процедура построения аддитивной модели:
1. Устранение циклических колебаний из исходного ряда (сглаживание ряда методом скользящей средней по базе, равной длине цикла; в случае четной базы проведение двухэтапного сглаживания).
2. Выявление колебаний ряда (построение разности между исходным и сглаженным рядом).
3. Определение средних значений циклических характеристик (вычисление средних значений по однородным периодам).
4. Нормирование средних значений циклических характеристик (определение их среднего значения с последующим смещением всех характеристик на эту величину так, чтобы среднее значение смещенных характеристик было равно 0). Результат рассматривается как циклическая составляющая ряда .
5. Устранение циклической составляющей из исходного временного ряда (построение разности между исходным и циклическим рядом). Результатом является трендовая составляющая.
6. Выбор вида тренда и расчет его параметров (определение формулы тренда).
7. Расчет прогнозных значений по формуле тренда.
8. Наложение нормированных циклических характеристик на трендовый прогноз (их суммирование с трендовым прогнозом).
9. Построение графика исходного ряда, продолженного прогнозными значениями.
10. Построение доверительного интервала.
Полученные результаты при условии прогнозирования на 1 год вперед приведены ниже. Описание построения модели приведено в Приложении 1.
Рис. 2. Прогноз по аддитивной модели на основе экспоненциального тренда
Рис. 3. Прогноз по аддитивной модели на основе экспоненциального тренда с доверительным интервалом
2.2. Построение мультипликативной модели
В мультипликативной модели предполагается, что тренд ряда умножается на циклическую составляющую , имеющую вид периодически изменяющегося коэффициента, принимающего значения большие и меньшие единицы. Этот коэффициент увеличивает значения, лежащие на линии тренда, в те периоды времени, когда циклическая составляющая больше 1, и уменьшаются, в те периоды, когда циклическая составляющая меньше 1. Средняя величина всех таких слагаемых за время одного цикла равна 1.
Пошаговая процедура построения мультипликативной модели:
1. Устранение циклических колебаний из исходного ряда (сглаживание ряда методом скользящей средней по базе, равной длине цикла; в случае четной базы проведение двухэтапного сглаживания).
2. Выявление колебаний ряда (деление исходного ряда на сглаженный).
3. Определение средних значений циклических характеристик (вычисление средних значений по однородным периодам).
4. Нормирование средних значений циклических характеристик (определение их среднего значения с последующим смещением всех характеристик на эту величину так, чтобы среднее значение смещенных характеристик было равно 1). Результат рассматривается как циклическая составляющая ряда .
5. Устранение циклической составляющей из исходного временного ряда (деление исходного ряда на циклический).
6. Выбор вида тренда и расчет его параметров (определение формулы тренда).
7. Расчет прогнозных значений по формуле тренда.
8. Наложение нормированных циклических характеристик на трендовый прогноз (их перемножение с трендовым прогнозом).
9. Построение графика исходного ряда, продолженного прогнозными значениями.
10. Построение доверительного интервала.
Полученные результаты приведены ниже. Описание построения модели приведено в Приложении 2.
Рис. 4. Прогноз по мультипликативной модели на основе линейного и экспоненциального трендов
Рис. 5. Прогноз по мультипликативной модели на основе экспоненциального тренда с доверительным интервалом
ЗАКЛЮЧЕНИЕ
Статистические методы все шире проникают в экономическую практику. С развитием компьютеров, распространением пакетов прикладных программ эти методы вышли за стены учебных и научно-исследовательских институтов. Они стали важным инструментом в деятельности аналитических, плановых, маркетинговых отделов различных фирм и предприятий.
При прогнозировании часто исходят из того, что уровни временных рядов экономических показателей могут содержать следующие компоненты: тренд, сезонную, циклическую и случайную составляющие. В зависимости от способа сочетания этих компонент модели временных рядов делятся на аддитивные, мультипликативные или модели смешанного типа.
По результатам проведенного исследования были сделаны следующие выводы:
Статистические методы прогнозирования имеют важное практическое значение в современном мире.
Электронная таблица Excel имеет достаточно средств для быстрого построения разнообразных функций для выделения трендовой составляющей модели данных и для построения на этой основе прогноза.
Как мы увидели построение качественного прогноза – процесс весьма трудоемкий. Качественный прогноз может дать только качественная модель данных. Прогнозирование действительно помогает заглянуть за горизонт завтрашнего дня и тем приносит несомненную пользу в процессах принятия решений.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
Дуброва Т.А. Статистические методы прогнозирования в экономике: Учебное пособие, практикум, тесты, программа курса. – М.: Московский государственный университет экономики, статистики и информатики, 2004. – 136 с.
Литвинчук С.Ю. Информационные технологии в экономике. Анализ и прогнозирование временных рядов с помощью Excel: учебное пособие. – Нижний Новгород: Нижегородский государственный архитектурно-строительный университет, 2010. – 78 с. .
Кувайская Ю.Г. Статистические методы прогнозирования: учебное пособие.– Ульяновск: УлГТУ, 2019. – 197 с.
Приложение 1.
Построение аддитивной модели в электронной таблице Excel на основе линейного тренда
В исходные данные добавим столбец с порядковым номера квартала (). Учитываем, что мы хотим построить прогноз на 2022 год (4 шага вперед):
Подготовим шаблон модели в соответствии с шагами, описанными в разделе 2.1 работы.
ШАГ 1. Устранение циклических колебаний из исходного ряда .
Как мы увидели из графического анализа исходных данных, имеют место устойчивые циклические колебания. Потому необходимо провести сглаживание ряда методом скользящей средней (в наш случае длина интервала сглаживания равна 4). Так как длина интервала представляет собой четное число, то мы будем проводить двухэтапное сглаживание.
На первом этапе проведем сглаживание при определенной нами длине интервала ( ), результат укажем в ячейке Е5 со сдвигом на полпериода вперед. Для вычисления среднего значения воспользуемся встроенной функцией СРЗНАЧ, которая возвращает среднее арифметическое своих аргументов. В ячейку Е5 вводим функцию СРЗНАЧ со следующими аргументами:
и протягиваем ее до ячейки Е13. В результате получим сглаженные годовые данные.
Теперь проведем повторное сглаживание уже сглаженного ряда при длине интервала, равному 2. База опять четная, и на этот раз результат мы сдвинем на полпериода назад. В ячейку F6 вводим функцию СРЗНАЧ со следующими аргументами:
и протягиваем ее до ячейки F13. В результате получим сглаженные, центрированные корректно, годовые данные
ШАГ 2. Выявление колебаний ряда.
Для того, чтобы выделить сезонные колебания, необходимо из исходного ряда данных вычесть полученный на шаге 1 ряд сглаженных данных.
В ячейку G6 вводим формулу: «=D6-F6» и протягиваем ее до ячейки G13. В итоге мы получим сезонные колебания нашего исходного ряда.
ШАГ 3. Определение средних значений циклических характеристик.
Для каждого однородного периода найдем среднее значение сезонных колебаний. Для 1 квартала найдем среднее значение колебаний, относящихся к первому кварталу, для 2 кварталу – ко второму и т.д. В ячейку H16 вводим формулу «=СРЗНАЧ(G8;G12)», в ячейку H17 вводим формулу «=СРЗНАЧ(G9;G13)», в H18 – «=СРЗНАЧ(G6;G10)», в H19 – «=СРЗНАЧ(G7;G11)». Получим поквартальные средние значения циклических колебаний.
ШАГ 4. Нормирование средних значений циклических характеристик.
Определим среднее значение поквартальных средних значений циклических колебаний. В ячейку H2 вводим формулу: «=СРЗНАЧ(H16:H19)».
Получаем среднее значение, равное -5. Смещаем все характеристики поквартальных средних значений циклические колебаний на эту величину так, чтобы среднее значение смещенных характеристик было равно 0.
В ячейку I16 вводим формулу: «=H16-$H$2», закрепляя ячейку H2 и протягиваем ее до ячейки I19. В итоге мы получим нормированные средние значения сезонных колебаний.
Проверим, что среднее значение нормированных поквартальных средних значений циклических колебаний равняется 0. В ячейку I2 вводим формулу: =СРЗНАЧ(I16:I19)». Результатом вычисления является 0.
В итоге мы получили – циклическую составляющую исходного ряда . Внесем полученные данные в соответствующий столбец.
ШАГ 5. Устранение циклической составляющей из исходного временного ряда .
Для устранения цикличности и построения обессезоненного ряда данных необходимо построить разность между исходным рядом и циклическим рядом . В ячейку К4 вводим формулу «=D4-J4» и протягиваем ее до ячейки К15. В результате получим обессезоненную составляющую исходного ряда.
Отобразим на диаграмме полученные на Шагах 1-5 данные: исходные данные , сезонную составляющую и обессезоненные данные.
ШАГ 6. Выбор вида тренда и расчет его параметров (определение формулы тренда).
Средство построения диаграмм и графиков Excel автоматически строит линии тренда и автоматически рассчитывает его параметры. Обратим внимание, что линию тренда нельзя добавить в объемную, лепестковую, круговую и кольцевую диаграммы, а также в диаграмму с накоплением.
Для построения линии тренда необходимо сначала построить график обессезоненных данных. Для этого выделим в таблице столбец обессезоненных данных вместе с заголовком, затем во вкладке «Вставка» в блоке «Диаграммы» выберем пункт «Вставить график» и тип «График с маркерами».
С помощью кнопки блока «Диаграммы» перенесем диаграмму на отдельный лист.
Чтобы по этому ряду данных построить линию тренда, выполним следующие действия.
Щелкнем по графику правой клавишей мыши, чтобы вызвать контекстное меню .
Выбираем раздел «Добавить линию тренда», чтобы открыть диалоговое окно «Формат линия тренда»:
В диалоговом окне «Формат линии тренда» выберем тип линии тренда. Для выбора предоставляются следующие типы линии тренда:
Экспоненциальная,
Линейная,
Логарифмическая,
Полиномиальная,
Степенная,
Линейная фильтрация.
Если ряд данных содержит нулевые или отрицательные значения, то линии тренда Экспоненциальная и Степенная будут недоступны.
В диалоговом окне «Формат линии тренда» также предлагается:
определить название линии тренда, которое будут включено в легенду,
задать количество периодов, на которые будут прогнозироваться данные (вперед и назад).
Три дополнительные опции позволяют отобразить на диаграмме:
пересечение линии тренда с осью Y (опция Пересечение кривой с осью Y в точке);
уравнение линии тренда (опция Показывать уравнение на диаграмме);
значение коэффициента детерминации , определяющее достоверность аппроксимации (опция Поместить на диаграмму величину достоверности аппроксимации (R^2)).
Построим линейную, степенную и экспоненциальную линии тренда с отображением уравнения и коэффициента детерминации на 4 месяца вперед.
Коэффициент детерминации характеризует степень близости линии тренда к исходным данным. Он может принимать значения от 0 до 1. Чем больше его значение, тем лучше линия тренда аппроксимирует исходные данные.
Как мы видим ближе всего к 1 значение коэффициента детерминации у степенной линии тренда.
На основе полученных уравнений можно рассчитать точечный прогноз путем подстановки в уравнение кривой значений времени , соответствующие периоду упреждения.
ШАГ 7. Расчет прогнозных значений по формуле тренда.
Прогнозирование с помощью встроенных функций Excel предоставляет большие возможности, чем графические средства.
Для быстрого вычисления прогнозных значений переменной без явного построения функции тренда используют статистические функции РОСТ и ТЕНДЕНЦИЯ.
Функция ТЕНДЕНЦИЯ возвращает значения в соответствии с линейным трендом.
Функция РОСТ рассчитывает прогнозируемый экспоненциальный рост на основе имеющихся данных.
Функции ТЕНДЕНЦИЯ и РОСТимеют одинаковый синтаксис:
=ТЕНДЕНЦИЯ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст])
=РОСТ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст]),
где
Известные_значения_Y – обязательный аргумент. Множество значений переменной Y, которые уже известны;
Известные_значения_Х – обязательный аргумент. Множество значений факторов;
Новые_значения_х – обязательный аргумент. Значения факторов, для которых вычисляется прогнозное значение;
Константа – необязательный аргумент.
Если в функциях ТЕНДЕНЦИЯ и РОСТ аргумент Известные_значения_Х опущен, то предполагается, что это массив натуральных чисел {1; 2; 3; …} такого же размера, как и массив аргумента Известные_значения_Y. Если опущен аргумент Новые_значения_х, то по умолчанию предполагается, что он совпадает с аргументом Известные_значения_Х.
Рассчитаем прогнозные значения с помощью функции ТЕНДЕНЦИЯ (сделаем прогноз на основе линейного тренда). Для этого в ячейку L4 введем функцию ТЕНДЕНЦИЯ со следующими аргументами, предварительно закрепив нужные диапазоны данных, где
Известные_значения_Y – множество обессезоненных данных (диапазон данных $K$4:$K$15);
Известные_значения_Х – множество значений периодов (диапазон данных $A$4:$A$15);
Новые_значения_х – значения времени , соответствующие периоду построения прогноза (значение ячейки A4).
Протягиваем формулу до ячейки L19. Таким образом, мы получим – трендовую составляющую исходного ряда , рассчитанную на основе линейного тренда.
ШАГ 8. Наложение нормированных циклических характеристик на трендовый прогноз.
Построим окончательный прогноз на основе линейного тренда, для этого сложим сезонную и трендовые составляющие. В ячейку М4 введем формулу: «=L4+J4» и протянем ее до ячейки M19. В итоге получим прогнозные значения.
ШАГ 9. Построение графика исходного ряда, продолженного прогнозными значениями.
Построим графики исходного ряда и полученных прогнозных значений. Для этого выделим два столбца соответствующих данных вместе с заголовками, затем во вкладке «Вставка» в блоке «Диаграммы» выберем пункт «Вставить график» и тип «График с маркерами».
ШАГ 10. Построение доверительного интервала.
На данном шаге мы определим границы возможного изменения прогнозируемого показателя, зададим «вилку» возможных значений прогнозируемых показателей, т.е. вычислим прогноз интервальный.
Границы доверительного интервала, учитывающего неопределенность, связанную с положением тренда, и возможность отклонения от этого тренда, упрощенно определяется в виде:
где
– расчетное значение уровня ряда, полученное по модели,
– средняя квадратическая ошибка,
– одно из чисел: 1, 2 или 3. При границы доверительного интервала обеспечивают приблизительно 68% надежность прогноза, при обеспечивается 95% надежность, при обеспечивается 99% надежность.
В работе мы рассмотрели формулу средней квадратической ошибки:
где
– фактическое значение уровня ряда;
– расчетное значение уровня ряда, полученное по модели;
– длина ряда.
Для расчета средней квадратической ошибки воспользуемся встроенной в Excel функцией СУММКВРАЗН, которая возвращает сумму квадратов разностей соответствующих значений в двух массивах и встроенной функцией СЧЕТ, которая подсчитывает количество ячеек, содержащих числа.
Функция СУММКВРАЗН имеет следующий синтаксис:
СУММКВРАЗН(массив_x; массив_y)
где
Массив_x – обязательный аргумент. Первый массив или диапазон значений;
Массив_y – обязательный аргумент. Второй массив или диапазон значений.
Введем в ячейку N2 формулу: «=(СУММКВРАЗН(D4:D15;M4:M15)/(СЧЁТ($D:$D)-2))^0,5». Таким образом, мы рассчитаем среднюю квадратическую ошибку.
Ограничим ввод данных в ячейке О2. Мы хотим, чтобы в нее можно было вводить только числа 1, 2 или 3. Для этого выделяем эту ячейку, затем во вкладке «Данные» в блоке «Работа с данными» выберем пункт «Проверка данных» и подпункт «Проверка данных».
В диалоговом окне «Проверка вводимых значений» во вкладке «Параметры» задаем следующие ограничения:
Во вкладках «Сообщение для ввода» и «Сообщение об ошибке» следующие данные:
Теперь в ячейку О2 мы сможем внести только значения 1, 2 или 3.
Осталось только отобразить в ячейке Р2 надежность нашего доверительного интервала. Сделаем это при помощи функции ЕСЛИ, которая возвращает одно значение, если указанное условие дает в результате значение ИСТИНА, и другое значение, если условие дает в результате значение ЛОЖЬ.
Функция ЕСЛИ имеет следующий синтаксис:
ЕСЛИ(лог_выражение; [значение_если_истина]; [значение_если_ложь])
Лог_выражение – обязательный аргумент. Любое значение или выражение, дающее в результате значение ИСТИНА или ЛОЖЬ. В этом аргументе может использоваться любой оператор сравнения.
Значение_если_истина – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ИСТИНА. Если аргумент лог_выражение соответствует значению ИСТИНА, а аргумент значение_если_истина опущен (т.е. после аргумента лог_выражение есть только запятая), возвращается значение 0.
Значение_если_ложь – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а аргумент значение_если_ложь опущен (т.е. после аргумента значение_если_истина нет запятой), функция ЕСЛИ возвращает логическое значение ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а значение аргумента значение_если_ложь пусто (т. е. после аргумента значение_если_истина стоит только запятая), функция ЕСЛИ возвращает значение 0 (ноль).
Введем в ячейку Р2 функцию если со следующими параметрами:
Теперь при значении , в ячейке Р2 отобразится 68%, при значении – 95%, при – значение 99%.
Построим доверительный интервал при надежности 95%.
Для построения нижней границы доверительного интервала введем в ячейку N4 формулу: «=$M4-$N$2*$O$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки N19. Таким образом мы найдем значения нижней границы доверительного интервала.
Для построения верхней границы доверительного интервала введем в ячейку О4 формулу: «=$M4+$N$2*$O$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки О19. Таким образом мы найдем значения верхней границы доверительного интервала.
Наша аддитивная модель сезонности на основе линейного тренда построена. Осталось только изобразить ее графически. Добавим на диаграмму, полученную на шаге 9, верхнюю и нижнюю границы доверительного интервала. Для этого выделим соответствующие столбцы данных вместе с заголовками, скопируем их, перейдем на лист с диаграммой и нажнем кнопку «Вставить». Соответствующие графики отобразятся на исходной диаграмме.
Построение аддитивной модели в электронной таблице Excel на основе экспоненциального тренда
Подготовим шаблон модели в соответствии с шагами, описанными в разделе 2.1 работы.
Повторим Шаги с 1 по 6, описанные первом разделе данного приложения.
ШАГ 7. Расчет прогнозных значений по формуле тренда.
Прогнозирование с помощью встроенных функций Excel предоставляет большие возможности, чем графические средства.
Для быстрого вычисления прогнозных значений переменной без явного построения функции тренда используют статистические функции РОСТ и ТЕНДЕНЦИЯ.
Функция ТЕНДЕНЦИЯ возвращает значения в соответствии с линейным трендом.
Функция РОСТ рассчитывает прогнозируемый экспоненциальный рост на основе имеющихся данных.
Функции ТЕНДЕНЦИЯ и РОСТимеют одинаковый синтаксис:
=ТЕНДЕНЦИЯ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст])
=РОСТ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст]),
где
Известные_значения_Y – обязательный аргумент. Множество значений переменной Y, которые уже известны;
Известные_значения_Х – обязательный аргумент. Множество значений факторов;
Новые_значения_х – обязательный аргумент. Значения факторов, для которых вычисляется прогнозное значение;
Константа – необязательный аргумент.
Если в функциях ТЕНДЕНЦИЯ и РОСТ аргумент Известные_значения_Х опущен, то предполагается, что это массив натуральных чисел {1; 2; 3; …} такого же размера, как и массив аргумента Известные_значения_Y. Если опущен аргумент Новые_значения_х, то по умолчанию предполагается, что он совпадает с аргументом Известные_значения_Х.
Рассчитаем прогнозные значения с помощью функции РОСТ (сделаем прогноз на основе экспоненциального тренда). Для этого в ячейку L4 введем функцию РОСТ со следующими аргументами, предварительно закрепив нужные диапазоны данных, где
Известные_значения_Y – множество обессезоненных данных (диапазон данных $K$4:$K$15);
Известные_значения_Х – множество значений периодов (диапазон данных $A$4:$A$15);
Новые_значения_х – значения времени , соответствующие периоду построения прогноза (значение ячейки A4).
Протягиваем формулу до ячейки L19. Таким образом, мы получим – трендовую составляющую исходного ряда , рассчитанную на основе экспоненциального тренда.
ШАГ 8. Наложение нормированных циклических характеристик на трендовый прогноз.
Построим окончательный прогноз на основе экспоненциального тренда, для этого сложим сезонную и трендовые составляющие. В ячейку М4 введем формулу: «=L4+J4» и протянем ее до ячейки M19. В итоге получим прогнозные значения.
ШАГ 9. Построение графика исходного ряда, продолженного прогнозными значениями.
Построим графики исходного ряда и полученных прогнозных значений. Для этого выделим два столбца соответствующих данных вместе с заголовками, затем во вкладке «Вставка» в блоке «Диаграммы» выберем пункт «Вставить график» и тип «График с маркерами».
ШАГ 10. Построение доверительного интервала.
На данном шаге мы определим границы возможного изменения прогнозируемого показателя, зададим «вилку» возможных значений прогнозируемых показателей, т.е. вычислим прогноз интервальный.
Границы доверительного интервала, учитывающего неопределенность, связанную с положением тренда, и возможность отклонения от этого тренда, упрощенно определяется в виде:
,
где
– расчетное значение уровня ряда, полученное по модели,
– средняя квадратическая ошибка,
– одно из чисел: 1, 2 или 3. При границы доверительного интервала обеспечивают приблизительно 68% надежность прогноза, при обеспечивается 95% надежность, при обеспечивается 99% надежность.
В работе мы рассмотрели формулу средней квадратической ошибки:
где
– фактическое значение уровня ряда;
– расчетное значение уровня ряда, полученное по модели;
– длина ряда.
Для расчета средней квадратической ошибки воспользуемся встроенной в Excel функцией СУММКВРАЗН, которая возвращает сумму квадратов разностей соответствующих значений в двух массивах и встроенной функцией СЧЕТ, которая подсчитывает количество ячеек, содержащих числа.
Функция СУММКВРАЗН имеет следующий синтаксис:
СУММКВРАЗН(массив_x; массив_y)
где
Массив_x – обязательный аргумент. Первый массив или диапазон значений;
Массив_y – обязательный аргумент. Второй массив или диапазон значений.
Введем в ячейку N2 формулу: «=(СУММКВРАЗН(D4:D15;M4:M15)/(СЧЁТ($D:$D)-2))^0,5». Таким образом, мы рассчитаем среднюю квадратическую ошибку.
Ограничим ввод данных в ячейке О2. Мы хотим, чтобы в нее можно было вводить только числа 1, 2 или 3. Для этого выделяем эту ячейку, затем во вкладке «Данные» в блоке «Работа с данными» выберем пункт «Проверка данных» и подпункт «Проверка данных».
В диалоговом окне «Проверка вводимых значений» во вкладке «Параметры» задаем следующие ограничения:
В
о вкладках «Сообщение для ввода» и «Сообщение об ошибке» следующие данные:
Теперь в ячейку О2 мы сможем внести только значения 1, 2 или 3.
Осталось только отобразить в ячейке Р2 надежность нашего доверительного интервала. Сделаем это при помощи функции ЕСЛИ, которая возвращает одно значение, если указанное условие дает в результате значение ИСТИНА, и другое значение, если условие дает в результате значение ЛОЖЬ.
Функция ЕСЛИ имеет следующий синтаксис:
ЕСЛИ(лог_выражение; [значение_если_истина]; [значение_если_ложь])
Лог_выражение – обязательный аргумент. Любое значение или выражение, дающее в результате значение ИСТИНА или ЛОЖЬ. В этом аргументе может использоваться любой оператор сравнения.
Значение_если_истина – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ИСТИНА. Если аргумент лог_выражение соответствует значению ИСТИНА, а аргумент значение_если_истина опущен (т.е. после аргумента лог_выражение есть только запятая), возвращается значение 0.
Значение_если_ложь – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а аргумент значение_если_ложь опущен (т.е. после аргумента значение_если_истина нет запятой), функция ЕСЛИ возвращает логическое значение ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а значение аргумента значение_если_ложь пусто (т. е. после аргумента значение_если_истина стоит только запятая), функция ЕСЛИ возвращает значение 0 (ноль).
Введем в ячейку Р2 функцию если со следующими параметрами:
Теперь при значении , в ячейке Р2 отобразится 68%, при значении – 95%, при – значение 99%.
Построим доверительный интервал при надежности 95%.
Для построения нижней границы доверительного интервала введем в ячейку N4 формулу: «=$M4-$N$2*$O$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки N19. Таким образом мы найдем значения нижней границы доверительного интервала.
Для построения верхней границы доверительного интервала введем в ячейку О4 формулу: «=$M4+$N$2*$O$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки О19. Таким образом мы найдем значения верхней границы доверительного интервала.
Наша аддитивная модель сезонности на основе экспоненциального тренда построена. Осталось только изобразить ее графически. Добавим на диаграмму, полученную на шаге 9, верхнюю и нижнюю границы доверительного интервала. Для этого выделим соответствующие столбцы данных вместе с заголовками, скопируем их, перейдем на лист с диаграммой и нажнем кнопку «Вставить». Соответствующие графики отобразятся на исходной диаграмме.
Приложение 2.
Построение мультипликативной модели в электронной таблице Excel на основе линейного и экспоненциального трендов
В исходные данные добавим столбец с порядковым номера квартала (). Учитываем, что мы хотим построить прогноз на 2022 год (4 шага вперед):
Подготовим шаблон модели в соответствии с шагами, описанными в разделе 2.2 работы.
ШАГ 1. Устранение циклических колебаний из исходного ряда .
Как мы увидели из графического анализа исходных данных, имеют место устойчивые циклические колебания. Потому необходимо провести сглаживание ряда методом скользящей средней (в наш случае длина интервала сглаживания равна 4). Так как длина интервала представляет собой четное число, то мы будем проводить двухэтапное сглаживание.
На первом этапе проведем сглаживание при определенной нами длине интервала ( ), результат укажем в ячейке Е5 со сдвигом на полпериода вперед. Для вычисления среднего значения воспользуемся встроенной функцией СРЗНАЧ, которая возвращает среднее арифметическое своих аргументов. В ячейку Е5 вводим функцию СРЗНАЧ со следующими аргументами:
и
протягиваем ее до ячейки Е13. В результате получим сглаженные годовые данные.
Теперь проведем повторное сглаживание уже сглаженного ряда при длине интервала, равному 2. База опять четная, и на этот раз результат мы сдвинем на полпериода назад. В ячейку F6 вводим функцию СРЗНАЧ со следующими аргументами:
и протягиваем ее до ячейки F13. В результате получим сглаженные, центрированные корректно, годовые данные
Ш
АГ 2. Выявление колебаний ряда.
Для того, чтобы выделить сезонные колебания, необходимо разделить исходный ряд данных на полученный на шаге 1 ряд сглаженных данных.
В
ячейку G6 вводим формулу: «=D6/F6» и протягиваем ее до ячейки G13. В итоге мы получим сезонные колебания нашего исходного ряда.
ШАГ 3. Определение средних значений циклических характеристик.
Для каждого однородного периода найдем среднее значение сезонных колебаний. Для 1 квартала найдем среднее значение колебаний, относящихся к первому кварталу, для 2 кварталу – ко второму и т.д. В ячейку H16 вводим формулу «=СРЗНАЧ(G8;G12)», в ячейку H17 вводим формулу «=СРЗНАЧ(G9;G13)», в H18 – «=СРЗНАЧ(G6;G10)», в H19 – «=СРЗНАЧ(G7;G11)». Получим поквартальные средние значения циклических колебаний.
ШАГ 4. Нормирование средних значений циклических характеристик.
Определим среднее значение поквартальных средних значений циклических колебаний. В ячейку H2 вводим формулу: «=СРЗНАЧ(H16:H19)».
Получаем среднее значение, равное 0,9797. Смещаем все характеристики поквартальных средних значений циклические колебаний на эту величину так, чтобы среднее значение смещенных характеристик было равно 1.
В ячейку I16 вводим формулу: «=H16/$H$2», закрепляя ячейку H2 и протягиваем ее до ячейки I19. В итоге мы получим нормированные средние значения сезонных колебаний.
Проверим, что среднее значение нормированных поквартальных средних значений циклических колебаний равняется 1. В ячейку I2 вводим формулу: =СРЗНАЧ(I16:I19)». Результатом вычисления является 1.
В итоге мы получили – циклическую составляющую исходного ряда . Внесем полученные данные в соответствующий столбец.
ШАГ 5. Устранение циклической составляющей из исходного временного ряда .
Д
ля устранения цикличности и построения обессезоненного ряда данных необходимо поделить исходный ряд на циклический ряд . В ячейку К4 вводим формулу «=D4/J4» и протягиваем ее до ячейки К15. В результате получим обессезоненную составляющую исходного ряда.
Отобразим на диаграмме полученные на Шагах 1-5 данные: исходные данные , сезонную составляющую и обессезоненные данные.
Так как значения ряда сезонности изменяется в диапазоне от 0 до 2, то диаграмма в таком виде неинформативна. Добавим для данного ряда значений дополнительную ось. Для этого выделим диаграмму, затем в пункте меню «Работа с диаграммами» во вкладке «Конструктор» в блоке «Тип» нажимаем кнопку «Изменить тип диаграммы». Во всплывающем диалоговом окне «Изменение типа диаграммы» переходим на вкладку «Вид диаграммы». Выбираем вид – комбинированная и напротив ряда данных «Сезонность» указываем необходимость наличия дополнительной оси.
Получим более информативный график, на котором видно цикличность изменения ряда данных сезонности.
ШАГ 6. Выбор вида тренда и расчет его параметров (определение формулы тренда).
Средство построения диаграмм и графиков Excel автоматически строит линии тренда и автоматически рассчитывает его параметры. Обратим внимание, что линию тренда нельзя добавить в объемную, лепестковую, круговую и кольцевую диаграммы, а также в диаграмму с накоплением.
Для построения линии тренда необходимо сначала построить график обессезоненных данных. Для этого выделим в таблице столбец обессезоненных данных вместе с заголовком, затем во вкладке «Вставка» в блоке «Диаграммы» выберем пункт «Вставить график» и тип «График с маркерами».
С помощью кнопки блока «Диаграммы» перенесем диаграмму на отдельный лист.
Чтобы по этому ряду данных построить линию тренда, выполним следующие действия.
Щелкнем по графику правой клавишей мыши, чтобы вызвать контекстное меню .
Выбираем раздел «Добавить линию тренда», чтобы открыть диалоговое окно «Формат линия тренда»:
.
В диалоговом окне «Формат линии тренда» выберем тип линии тренда. Для выбора предоставляются следующие типы линии тренда:
Экспоненциальная,
Линейная,
Логарифмическая,
Полиномиальная,
Степенная,
Линейная фильтрация.
Если ряд данных содержит нулевые или отрицательные значения, то линии тренда Экспоненциальная и Степенная будут недоступны.
В диалоговом окне «Формат линии тренда» также предлагается:
определить название линии тренда, которое будут включено в легенду,
задать количество периодов, на которые будут прогнозироваться данные (вперед и назад).
Три дополнительные опции позволяют отобразить на диаграмме:
пересечение линии тренда с осью Y (опция Пересечение кривой с осью Y в точке);
уравнение линии тренда (опция Показывать уравнение на диаграмме);
значение коэффициента детерминации , определяющее достоверность аппроксимации (опция Поместить на диаграмму величину достоверности аппроксимации (R^2)).
Построим линейную, степенную и экспоненциальную линии тренда с отображением уравнения и коэффициента детерминации на 4 месяца вперед.
Коэффициент детерминации характеризует степень близости линии тренда к исходным данным. Он может принимать значения от 0 до 1. Чем больше его значение, тем лучше линия тренда аппроксимирует исходные данные.
Как мы видим ближе всего к 1 значение коэффициента детерминации у экспоненциальной линии тренда.
На основе полученных уравнений можно рассчитать точечный прогноз путем подстановки в уравнение кривой значений времени , соответствующие периоду упреждения.
2.1 Построение мультипликативной модели в электронной таблице Excel на основе линейного тренда
ШАГ 7. Расчет прогнозных значений по формуле тренда.
Прогнозирование с помощью встроенных функций Excel предоставляет большие возможности, чем графические средства.
Для быстрого вычисления прогнозных значений переменной без явного построения функции тренда используют статистические функции РОСТ и ТЕНДЕНЦИЯ.
Функция ТЕНДЕНЦИЯ возвращает значения в соответствии с линейным трендом.
Функция РОСТ рассчитывает прогнозируемый экспоненциальный рост на основе имеющихся данных.
Функции ТЕНДЕНЦИЯ и РОСТимеют одинаковый синтаксис:
=ТЕНДЕНЦИЯ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст])
=РОСТ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст]),
где
Известные_значения_Y – обязательный аргумент. Множество значений переменной Y, которые уже известны;
Известные_значения_Х – обязательный аргумент. Множество значений факторов;
Новые_значения_х – обязательный аргумент. Значения факторов, для которых вычисляется прогнозное значение;
Константа – необязательный аргумент.
Если в функциях ТЕНДЕНЦИЯ и РОСТ аргумент Известные_значения_Х опущен, то предполагается, что это массив натуральных чисел {1; 2; 3; …} такого же размера, как и массив аргумента Известные_значения_Y. Если опущен аргумент Новые_значения_х, то по умолчанию предполагается, что он совпадает с аргументом Известные_значения_Х.
Рассчитаем прогнозные значения с помощью функции ТЕНДЕНЦИЯ (сделаем прогноз на основе линейного тренда). Для этого в ячейку L4 введем функцию ТЕНДЕНЦИЯ со следующими аргументами, предварительно закрепив нужные диапазоны данных, где
Известные_значения_Y – множество обессезоненных данных (диапазон данных $K$4:$K$15);
Известные_значения_Х – множество значений периодов (диапазон данных $A$4:$A$15);
Новые_значения_х – значения времени , соответствующие периоду построения прогноза (значение ячейки A4).
Протягиваем формулу до ячейки L19. Таким образом, мы получим – трендовую составляющую исходного ряда , рассчитанную на основе линейного тренда.
ШАГ 8. Наложение нормированных циклических характеристик на трендовый прогноз.
П
остроим окончательный прогноз на основе линейного тренда, для этого перемножим сезонную и трендовые составляющие. В ячейку М4 введем формулу: «=L4*J4» и протянем ее до ячейки M19. В итоге получим прогнозные значения.
ШАГ 9. Построение графика исходного ряда, продолженного прогнозными значениями.
Построим графики исходного ряда и полученных прогнозных значений. Для этого выделим два столбца соответствующих данных вместе с заголовками, затем во вкладке «Вставка» в блоке «Диаграммы» выберем пункт «Вставить график» и тип «График с маркерами».
ШАГ 10. Построение доверительного интервала.
На данном шаге мы определим границы возможного изменения прогнозируемого показателя, зададим «вилку» возможных значений прогнозируемых показателей, т.е. вычислим прогноз интервальный.
Границы доверительного интервала, учитывающего неопределенность, связанную с положением тренда, и возможность отклонения от этого тренда, упрощенно определяется в виде:
,
где
– расчетное значение уровня ряда, полученное по модели,
– средняя квадратическая ошибка,
– одно из чисел: 1, 2 или 3. При границы доверительного интервала обеспечивают приблизительно 68% надежность прогноза, при обеспечивается 95% надежность, при обеспечивается 99% надежность.
В работе мы рассмотрели формулу средней квадратической ошибки:
где
– фактическое значение уровня ряда;
– расчетное значение уровня ряда, полученное по модели;
– длина ряда.
Для расчета средней квадратической ошибки воспользуемся встроенной в Excel функцией СУММКВРАЗН, которая возвращает сумму квадратов разностей соответствующих значений в двух массивах и встроенной функцией СЧЕТ, которая подсчитывает количество ячеек, содержащих числа.
Функция СУММКВРАЗН имеет следующий синтаксис:
СУММКВРАЗН(массив_x; массив_y)
где
Массив_x – обязательный аргумент. Первый массив или диапазон значений;
Массив_y – обязательный аргумент. Второй массив или диапазон значений.
Введем в ячейку N2 формулу: «=(СУММКВРАЗН($D$4:$D$15;M4:M15)/(СЧЁТ($D:$D)-2))^0,5». Таким образом, мы рассчитаем среднюю квадратическую ошибку.
Ограничим ввод данных в ячейке О2. Мы хотим, чтобы в нее можно было вводить только числа 1, 2 или 3. Для этого выделяем эту ячейку, затем во вкладке «Данные» в блоке «Работа с данными» выберем пункт «Проверка данных» и подпункт «Проверка данных».
В диалоговом окне «Проверка вводимых значений» во вкладке «Параметры» задаем следующие ограничения:
В
о вкладках «Сообщение для ввода» и «Сообщение об ошибке» следующие данные:
Теперь в ячейку О2 мы сможем внести только значения 1, 2 или 3.
Осталось только отобразить в ячейке T2 надежность нашего доверительного интервала. Сделаем это при помощи функции ЕСЛИ, которая возвращает одно значение, если указанное условие дает в результате значение ИСТИНА, и другое значение, если условие дает в результате значение ЛОЖЬ.
Функция ЕСЛИ имеет следующий синтаксис:
ЕСЛИ(лог_выражение; [значение_если_истина]; [значение_если_ложь])
Лог_выражение – обязательный аргумент. Любое значение или выражение, дающее в результате значение ИСТИНА или ЛОЖЬ. В этом аргументе может использоваться любой оператор сравнения.
Значение_если_истина – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ИСТИНА. Если аргумент лог_выражение соответствует значению ИСТИНА, а аргумент значение_если_истина опущен (т.е. после аргумента лог_выражение есть только запятая), возвращается значение 0.
Значение_если_ложь – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а аргумент значение_если_ложь опущен (т.е. после аргумента значение_если_истина нет запятой), функция ЕСЛИ возвращает логическое значение ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а значение аргумента значение_если_ложь пусто (т. е. после аргумента значение_если_истина стоит только запятая), функция ЕСЛИ возвращает значение 0 (ноль).
Введем в ячейку T2 функцию если со следующими параметрами:
Теперь при значении , в ячейке T2 отобразится 68%, при значении – 95%, при – значение 99%.
Построим доверительный интервал при надежности 95%.
Для построения нижней границы доверительного интервала введем в ячейку N4 формулу: «=$M4-$N$2*$O$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки N19. Таким образом мы найдем значения нижней границы доверительного интервала.
Для построения верхней границы доверительного интервала введем в ячейку О4 формулу: «=$M4+$N$2*$O$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки О19. Таким образом мы найдем значения верхней границы доверительного интервала.
Наша мультипликативная модель сезонности на основе линейного тренда построена. Осталось только изобразить ее графически. Добавим на диаграмму, полученную на шаге 9, верхнюю и нижнюю границы доверительного интервала. Для этого выделим соответствующие столбцы данных вместе с заголовками, скопируем их, перейдем на лист с диаграммой и нажнем кнопку «Вставить». Соответствующие графики отобразятся на исходной диаграмме.
Построение мультипликативной модели в электронной таблице Excel на основе экспоненциального тренда
ШАГ 7. Расчет прогнозных значений по формуле тренда.
Прогнозирование с помощью встроенных функций Excel предоставляет большие возможности, чем графические средства.
Для быстрого вычисления прогнозных значений переменной без явного построения функции тренда используют статистические функции РОСТ и ТЕНДЕНЦИЯ.
Функция ТЕНДЕНЦИЯ возвращает значения в соответствии с линейным трендом.
Функция РОСТ рассчитывает прогнозируемый экспоненциальный рост на основе имеющихся данных.
Функции ТЕНДЕНЦИЯ и РОСТимеют одинаковый синтаксис:
=ТЕНДЕНЦИЯ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст])
=РОСТ(Известные_значения_Y; [Известные_значения_Х]; [Новые_значения_х]; [Конст]),
где
Известные_значения_Y – обязательный аргумент. Множество значений переменной Y, которые уже известны;
Известные_значения_Х – обязательный аргумент. Множество значений факторов;
Новые_значения_х – обязательный аргумент. Значения факторов, для которых вычисляется прогнозное значение;
Константа – необязательный аргумент.
Если в функциях ТЕНДЕНЦИЯ и РОСТ аргумент Известные_значения_Х опущен, то предполагается, что это массив натуральных чисел {1; 2; 3; …} такого же размера, как и массив аргумента Известные_значения_Y. Если опущен аргумент Новые_значения_х, то по умолчанию предполагается, что он совпадает с аргументом Известные_значения_Х.
Рассчитаем прогнозные значения с помощью функции РОСТ (сделаем прогноз на основе экспоненциального тренда). Для этого в ячейку Р4 введем функцию РОСТ со следующими аргументами, предварительно закрепив нужные диапазоны данных, где
Известные_значения_Y – множество обессезоненных данных (диапазон данных $K$4:$K$15);
Известные_значения_Х – множество значений периодов (диапазон данных $A$4:$A$15);
Новые_значения_х – значения времени , соответствующие периоду построения прогноза (значение ячейки A4).
Протягиваем формулу до ячейки P19. Таким образом, мы получим – трендовую составляющую исходного ряда , рассчитанную на основе экспоненциального тренда.
ШАГ 8. Наложение нормированных циклических характеристик на трендовый прогноз.
Построим окончательный прогноз на основе экспоненциального тренда, для этого перемножим сезонную и трендовые составляющие. В ячейку Q4 введем формулу: «=P4*J4» и протянем ее до ячейки Q19. В итоге получим прогнозные значения.
ШАГ 9. Построение графика исходного ряда, продолженного прогнозными значениями.
Построим графики исходного ряда и полученных прогнозных значений. Для этого выделим два столбца соответствующих данных вместе с заголовками, затем во вкладке «Вставка» в блоке «Диаграммы» выберем пункт «Вставить график» и тип «График с маркерами».
ШАГ 10. Построение доверительного интервала.
На данном шаге мы определим границы возможного изменения прогнозируемого показателя, зададим «вилку» возможных значений прогнозируемых показателей, т.е. вычислим прогноз интервальный.
Границы доверительного интервала, учитывающего неопределенность, связанную с положением тренда, и возможность отклонения от этого тренда, упрощенно определяется в виде:
,
где
– расчетное значение уровня ряда, полученное по модели,
– средняя квадратическая ошибка,
– одно из чисел: 1, 2 или 3. При границы доверительного интервала обеспечивают приблизительно 68% надежность прогноза, при обеспечивается 95% надежность, при обеспечивается 99% надежность.
В работе мы рассмотрели формулу средней квадратической ошибки:
где
– фактическое значение уровня ряда;
– расчетное значение уровня ряда, полученное по модели;
– длина ряда.
Для расчета средней квадратической ошибки воспользуемся встроенной в Excel функцией СУММКВРАЗН, которая возвращает сумму квадратов разностей соответствующих значений в двух массивах и встроенной функцией СЧЕТ, которая подсчитывает количество ячеек, содержащих числа.
Функция СУММКВРАЗН имеет следующий синтаксис:
СУММКВРАЗН(массив_x; массив_y)
где
Массив_x – обязательный аргумент. Первый массив или диапазон значений;
Массив_y – обязательный аргумент. Второй массив или диапазон значений.
Введем в ячейку R2 формулу: «=(СУММКВРАЗН($D$4:$D$15;Q4:Q15)/(СЧЁТ($D:$D)-2))^0,5». Таким образом, мы рассчитаем среднюю квадратическую ошибку.
Ограничим ввод данных в ячейке S2. Мы хотим, чтобы в нее можно было вводить только числа 1, 2 или 3. Для этого выделяем эту ячейку, затем во вкладке «Данные» в блоке «Работа с данными» выберем пункт «Проверка данных» и подпункт «Проверка данных».
В диалоговом окне «Проверка вводимых значений» во вкладке «Параметры» задаем следующие ограничения:
В
о вкладках «Сообщение для ввода» и «Сообщение об ошибке» следующие данные:
Теперь в ячейку S2 мы сможем внести только значения 1, 2 или 3.
Осталось только отобразить в ячейке U2 надежность нашего доверительного интервала. Сделаем это при помощи функции ЕСЛИ, которая возвращает одно значение, если указанное условие дает в результате значение ИСТИНА, и другое значение, если условие дает в результате значение ЛОЖЬ.
Функция ЕСЛИ имеет следующий синтаксис:
ЕСЛИ(лог_выражение; [значение_если_истина]; [значение_если_ложь])
Лог_выражение – обязательный аргумент. Любое значение или выражение, дающее в результате значение ИСТИНА или ЛОЖЬ. В этом аргументе может использоваться любой оператор сравнения.
Значение_если_истина – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ИСТИНА. Если аргумент лог_выражение соответствует значению ИСТИНА, а аргумент значение_если_истина опущен (т.е. после аргумента лог_выражение есть только запятая), возвращается значение 0.
Значение_если_ложь – необязательный аргумент. Значение, которое возвращается, если аргумент лог_выражение соответствует значению ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а аргумент значение_если_ложь опущен (т.е. после аргумента значение_если_истина нет запятой), функция ЕСЛИ возвращает логическое значение ЛОЖЬ. Если аргумент лог_выражение соответствует значению ЛОЖЬ, а значение аргумента значение_если_ложь пусто (т. е. после аргумента значение_если_истина стоит только запятая), функция ЕСЛИ возвращает значение 0 (ноль).
Введем в ячейку U2 функцию если со следующими параметрами:
Теперь при значении , в ячейке U2 отобразится 68%, при значении – 95%, при – значение 99%.
Построим доверительный интервал при надежности 99%.
Для построения нижней границы доверительного интервала введем в ячейку R4 формулу: «=$Q4-$R$2*$S$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки R19. Таким образом мы найдем значения нижней границы доверительного интервала.
Для построения верхней границы доверительного интервала введем в ячейку S4 формулу: «=$Q4+$R$2*$S$2», закрепив при этом необходимые ячейки, и протянем ее до ячейки S19. Таким образом мы найдем значения верхней границы доверительного интервала.
Наша мультипликативная модель сезонности на основе экспоненциального тренда построена. Осталось только изобразить ее графически. Добавим на диаграмму, полученную на шаге 9, верхнюю и нижнюю границы доверительного интервала. Для этого выделим соответствующие столбцы данных вместе с заголовками, скопируем их, перейдем на лист с диаграммой и нажнем кнопку «Вставить». Соответствующие графики отобразятся на исходной диаграмме.
Просмотров работы: 31