
Время на прочтение
6 мин
Количество просмотров 349K
Добрый день, уважаемые читатели.
В сегодняшней статье я хотел бы, как можно подробнее, рассмотреть интеграцию приложений Python и MS Excel. Данные вопрос может возникнуть, например, при создании какой-либо системы онлайн отчетности, которая должна выгружать результаты в общепринятый формат ну или какие-либо другие задачи. Также в статье я покажу и обратную интеграцию, т.е. как использовать функцию написанную на python в Excel, что также может быть полезно для автоматизации отчетов.
Работаем с файлами MS Excel на Python
Для работы с Excel файлами из Python мне известны 2 варианта:
- Использование библиотек, таких как xlrd, xlwt, xlutils или openpyxl
- Работа с com-объектом
Рассмотрим работу с этими способами подробнее. В качестве примера будем использовать готовый файл excel из которого мы сначала считаем данные из первой ячейки, а затем запишем их во вторую. Таких простых примеров будет достаточно для первого ознакомления.
Использование библиотек
Итак, первый метод довольно простой и хорошо описан. Например, есть отличная статья для описания работы c xlrd, xlwt, xlutils. Поэтому в данном материале я приведу небольшой кусок кода с их использованием.
Для начала загрузим нужные библиотеки и откроем файл xls на чтение и выберем
нужный лист с данными:
import xlrd, xlwt
#открываем файл
rb = xlrd.open_workbook('../ArticleScripts/ExcelPython/xl.xls',formatting_info=True)
#выбираем активный лист
sheet = rb.sheet_by_index(0)
Теперь давайте посмотрим, как считать значения из нужных ячеек:
#получаем значение первой ячейки A1
val = sheet.row_values(0)[0]
#получаем список значений из всех записей
vals = [sheet.row_values(rownum) for rownum in range(sheet.nrows)]
Как видно чтение данных не составляет труда. Теперь запишем их в другой файл. Для этого создам новый excel файл с новой рабочей книгой:
wb = xlwt.Workbook()
ws = wb.add_sheet('Test')
Запишем в новый файл полученные ранее данные и сохраним изменения:
#в A1 записываем значение из ячейки A1 прошлого файла
ws.write(0, 0, val[0])
#в столбец B запишем нашу последовательность из столбца A исходного файла
i = 0
for rec in vals:
ws.write(i,1,rec[0])
i =+ i
#сохраняем рабочую книгу
wb.save('../ArticleScripts/ExcelPython/xl_rec.xls')
Из примера выше видно, что библиотека xlrd отвечает за чтение данных, а xlwt — за запись, поэтому нет возможности внести изменения в уже созданную книгу без ее копирования в новую. Кроме этого указанные библиотеки работают только с файлами формата xls (Excel 2003) и у них нет поддержки нового формата xlsx (Excel 2007 и выше).
Чтобы успешно работать с форматом xlsx, понадобится библиотека openpyxl. Для демонстрации ее работы проделаем действия, которые были показаны для предыдущих библиотек.
Для начала загрузим библиотеку и выберем нужную книгу и рабочий лист:
import openpyxl
wb = openpyxl.load_workbook(filename = '../ArticleScripts/ExcelPython/openpyxl.xlsx')
sheet = wb['test']
Как видно из вышеприведенного листинга сделать это не сложно. Теперь посмотрим как можно считать данные:
#считываем значение определенной ячейки
val = sheet['A1'].value
#считываем заданный диапазон
vals = [v[0].value for v in sheet.range('A1:A2')]
Отличие от прошлых библиотек в том, что openpyxl дает возможность отображаться к ячейкам и последовательностям через их имена, что довольно удобно и понятно при чтении программы.
Теперь посмотрим как нам произвести запись и сохранить данные:
#записываем значение в определенную ячейку
sheet['B1'] = val
#записываем последовательность
i = 0
for rec in vals:
sheet.cell(row=i, column=2).value = rec
i =+ 1
# сохраняем данные
wb.save('../ArticleScripts/ExcelPython/openpyxl.xlsx')
Из примера видно, что запись, тоже производится довольно легко. Кроме того, в коде выше, можно заметить, что openpyxl кроме имен ячеек может работать и с их индексами.
К недостаткам данной библиотеки можно отнести, то что, как и в предыдущем примере, нет возможности сохранить изменения без создания новой книги.
Как было показано выше, для более менее полноценной работы с excel файлами, в данном случае, нужно 4 библиотеки, и это не всегда удобно. Кроме этого, возможно нужен будет доступ к VBA (допустим для какой-либо последующей обработки) и с помощью этих библиотек его не получить.
Однако, работа с этими библиотеками достаточно проста и удобна для быстрого создания Excel файлов их форматирования, но если Вам надо больше возможностей, то следующий подпункт для Вас.
Работа с com-объектом
В своих отчетах я предпочитаю использовать второй способ, а именно использование файла Excel через com-объект с использованием библиотеки win32com. Его преимуществом, является то, что вы можете выполнять с файлом все операции, которые позволяет делать обычный Excel с использованием VBA.
Проиллюстрируем это на той же задаче, что и предыдущие примеры.
Для начала загрузим нужную библиотеку и создадим COM объект.
import win32com.client
Excel = win32com.client.Dispatch("Excel.Application")
Теперь мы можем работать с помощью объекта Excel мы можем получить доступ ко всем возможностям VBA. Давайте, для начала, откроем любую книгу и выберем активный лист. Это можно сделать так:
wb = Excel.Workbooks.Open(u'D:\Scripts\DataScience\ArticleScripts\ExcelPython\xl.xls')
sheet = wb.ActiveSheet
Давайте получим значение первой ячейки и последовательности:
#получаем значение первой ячейки
val = sheet.Cells(1,1).value
#получаем значения цепочки A1:A2
vals = [r[0].value for r in sheet.Range("A1:A2")]
Как можно заметить, мы оперируем здесь функциями чистого VBA. Это очень удобно если у вас есть написанные макросы и вы хотите использовать их при работе с Python при минимальных затратах на переделку кода.
Посмотрим, как можно произвести запись полученных значений:
#записываем значение в определенную ячейку
sheet.Cells(1,2).value = val
#записываем последовательность
i = 1
for rec in vals:
sheet.Cells(i,3).value = rec
i = i + 1
#сохраняем рабочую книгу
wb.Save()
#закрываем ее
wb.Close()
#закрываем COM объект
Excel.Quit()
Из примера видно, что данные операции тоже довольно просто реализовываются. Кроме этого, можно заметить, что изменения мы сохранили в той же книге, которую открыли для чтения, что достаточно удобно.
Однако, внимательный читатель, обратит внимание на переменную i, которая инициализируется не 0, как принято python, а 1. Это связано с тем, что мы работаем с индексами ячеек как из VBA, а там нумерация начинается не с 0, а с 1.
На этом закончим разбор способов работы с excel файлами в python и перейдем к обратной задаче.
Вызываем функции Python из MS Excel
Может возникнуть такая ситуация, что у вас уже есть какой-либо функция, которая обрабатывает данные на python, и нужно перенести ее функциональность в Excel. Конечно же можно переписать ее на VBA, но зачем?
Для использования функций python в Excel есть прекрасная надстройка ExcelPython. С ее помощью вы сможете вызывать функции написанные на python прямо из Excel, правда придется еще написать небольшую обертку на VBA, и все это будет показано ниже.
Итак, предположим у нас есть функция, написанная на python, которой мы хотим воспользоваться:
def get_unique(lists):
sm = 0
for i in lists:
sm = sm + int(i.pop())
return sm
На вход ей подается список, состоящий из списков, это одно из условий, которое должно выполняться для работы данной функции в Excel.
Сохраним функцию в файле plugin.py и положим его в ту же директорию, где будет лежать наш excel файл, с которым мы будем работать.
Теперь установим ExcelPython. Установка происходит через запуск exe-файла и не вызывает затруднений.
Когда все приготовления выполнены, открываем тестовый файл excel и вызовем редактор VBA (Alt+F11). Для работы с вышеуказанной надстройкой необходимо ее подключить, через Tools->References, как показано на рисунке:

Ну что же, теперь можно приступить к написанию функции-обертки для нашего Python-модуля plugin.py. Выглядеть она будет следующим образом:
Function sr(lists As Range)
On Error GoTo do_error
Set plugin = PyModule("plugin", AddPath:=ThisWorkbook.Path)
Set result = PyCall(plugin, "get_unique", PyTuple(lists.Value2))
sr = WorksheetFunction.Transpose(PyVar(result))
Exit Function
do_error:
sr = Err.Description
End Function
Итак, что же происходит в данной функции?
Для начала, с помощью PyModule, мы подключаем нужный модуль. Для этого в качестве параметров ей передается имя модуля без расширения, и путь до папки в которой он находится. На выходе работы PyModule мы получаем объект для работы с модулем.
Затем, с помощью PyCall, вызываем нужную нам функцию из указанного модуля. В качестве параметров PyCall получает следующее:
- Объект модуля, полученный на предыдущем шаге
- Имя вызываемой функции
- Параметры, передаваемые функции (передаются в виде списка)
Функция PyTuple, получает на вход какие-либо значения и преобразует их в объект tuple языка Python.
Ну и, соответственно, PyVar выполняет операцию преобразования результата функции python, к типу понятному Excel.
Теперь, чтобы убедиться в работоспособности нашей связки, вызовем нашу свежеиспеченую функцию на листе в Excel:

Как видно из рисунка все отработало правильно.
Надо отметить, что в данном материале используется старая версия ExcelPython, и на GitHub’e автора доступна новая версия.
Заключение
В качестве заключения, надо отметить, примеры в данной статье самые простые и для более глубоко изучения данных методов, я рекомендую обратиться к
документации по нужным пакетам.
Также хочу заметить, что указанные пакеты не являются единственными и в статье опущено рассмотрение, таких пакетов как xlsxwriter для генерации excel файлов или xlwings, который может работать с Excel файлами «на лету», а также же PyXLL, который выполняет аналогичные функции ExcelPython.
Кроме этого в статье я попытался несколько обобщить разборасанный по сети материал, т.к. такие вопросы часто фигурируют на форумах и думаю некоторым будет полезно иметь, такую «шпаргалку» под рукой.
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
One can retrieve information from a spreadsheet. Reading, writing, or modifying the data can be done in Python can be done in using different methods. Also, the user might have to go through various sheets and retrieve data based on some criteria or modify some rows and columns and do a lot of work. Here, we will see the different methods to read our excel file.
Required Module
pip install xlrd
Input File:

Method 1: Reading an excel file using Python using Pandas
In this method, We will first import the Pandas module then we will use Pandas to read our excel file. You can read more operations using the excel file using Pandas in this article. Click here
Python3
import pandas as pd
dataframe1 = pd.read_excel('book2.xlsx')
print(dataframe1)
Output:

Method 2: Reading an excel file using Python using openpyxl
The load_workbook() function opens the Books.xlsx file for reading. This file is passed as an argument to this function. The object of the dataframe.active has been created in the script to read the values of the max_row and the max_column properties. These values are used in the loops to read the content of the Books2.xlsx file. You can read other operations using openpyxl in this article.
Python3
import openpyxl
dataframe = openpyxl.load_workbook("Book2.xlsx")
dataframe1 = dataframe.active
for row in range(0, dataframe1.max_row):
for col in dataframe1.iter_cols(1, dataframe1.max_column):
print(col[row].value)
Output:

Method 3: Reading an excel file using Python using Xlwings
Xlwings can be used to insert data in an Excel file similarly as it reads from an Excel file. Data can be provided as a list or a single input to a certain cell or a selection of cells. You can read other operations using Xlwings in this article.
Python3
import xlwings as xw
ws = xw.Book("Book2.xlsx").sheets['Sheet1']
v1 = ws.range("A1:A7").value
print("Result:", v1, v2)
Output:
Result: ['Name Age Stream Percentage', '0 Ankit 18 Math 95', '1 Rahul 19 Science 90', '2 Shaurya 20 Commerce 85', '3 Aishwarya 18 Math 80', '4 Priyanka 19 Science 75', None]
RECOMMENDED ARTICLE – How to Automate an Excel Sheet in Python?
Like Article
Save Article
Microsoft Excel is probably one of the highly used data storage applications. A huge proportion of small to medium size businesses fulfill their analytics requirement using Excel.
However, analyzing huge amount of data in Excel can become highly tedious and time-consuming. You could build customized data processing and analytics application using Visual Basic(VBA), the language that powers the Excel sheets. However, learning VBA could be difficult and perhaps, not worth it.
However, if you have a little knowledge of Python, you could build highly professional Business Intelligence using Excel data, without the need of a database. Using Python with Excel could be a game changer for your business.
Sections Covered
- Basic Information about Excel
- What is Openpyxl and how to install it?
- Reading data from Excel in Python
- Reading multiple cells from Excel in Python
- Find the max row and column number of an Excel sheet in Python
- How to iterate over Excel rows and columns in Python?
- Create a new Excel file with Python
- Writing data to Excel in Python
- Appending data to Excel in Python
- Manipulating Excel Sheets in Python
- Practical usage example of data analysis of Excel sheets in Python
Basic Information about Excel
Before beginning this Openpyxl tutorial, you need to keep the following details in mind.
- Excel files are called Workbooks.
- Each Workbook can contain multiple sheets.
- Every sheet consists of rows starting from 1 and columns starting from A.
- Rows and columns together make up a cell.
- Any type of data can be stored.
What is Openpyxl and how to install it?
The Openpyxl module in Python is used to handle Excel files without involving third-party Microsoft application software. It is arguably, the best python excel library that allows you to perform various Excel operations and automate excel reports using Python. You can perform all kinds of tasks using Openpyxl like:-
- Reading data
- Writing data
- Editing Excel files
- Drawing graphs and charts
- Working with multiple sheets
- Sheet Styling etc.
You can install Openpyxl module by typing pip install openpyxl in your command line.
pip install openpyxlReading data from Excel in Python
To import an excel file in Python, use the load_workbook method from Openpyxl library.
Let’s import an Excel file named wb1.xlsx in Python using Openpyxl module. It has the following data as shown in the image below.

Step 1 — Import the load_workbook method from Openpyxl.
from openpyxl import load_workbook
Step 2 — Provide the file location for the Excel file you want to open in Python.
wb = load_workbook('wb1.xlsx')If your Excel file is present in the same directory as the python file, you don’t need to provide to entire file location.
Step 3 — Choose the first active sheet present in the workbook using wb.active attribute.
sheet = wb.activeThe above points are a standard way of accessing Excel sheets using Python. You will see them being used multiple times through out this article.
Let’s read all the data present in Row 1 (header row).
Method 1 — Reading data through Excel cell name in Python
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
print(sheet["A1"].value)
print(sheet["B1"].value)
print(sheet["C1"].value)
print(sheet["D1"].value)Output
ProductId
ProductName
Cost per Unit
QuantityMethod 2 — Reading data from Excel using cell() method in Python
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
print(sheet.cell(row=1, column=1).value)
print(sheet.cell(row=1, column=2).value)
print(sheet.cell(row=1, column=3).value)
print(sheet.cell(row=1, column=4).value)Output
ProductId
ProductName
Cost per Unit
QuantityReading Multiple Cells from Excel in Python
You can also read multiple cells from an Excel workbook. Let’s understand this through various examples. Refer to the image of the wb1.xlsx file above for clarity.
Method 1 — Reading a range of cells in Excel using cell names
To read the data from a specific range of cells in your Excel sheet, you need to slice your sheet object through both the cells.
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
# Access all cells from A1 to D11
print(sheet["A1:D11"])Output
((<Cell 'Sheet1'.A1>, <Cell 'Sheet1'.B1>, <Cell 'Sheet1'.C1>, <Cell 'Sheet1'.D1>),
(<Cell 'Sheet1'.A2>, <Cell 'Sheet1'.B2>, <Cell 'Sheet1'.C2>, <Cell 'Sheet1'.D2>),
(<Cell 'Sheet1'.A3>, <Cell 'Sheet1'.B3>, <Cell 'Sheet1'.C3>, <Cell 'Sheet1'.D3>),
(<Cell 'Sheet1'.A4>, <Cell 'Sheet1'.B4>, <Cell 'Sheet1'.C4>, <Cell 'Sheet1'.D4>),
(<Cell 'Sheet1'.A5>, <Cell 'Sheet1'.B5>, <Cell 'Sheet1'.C5>, <Cell 'Sheet1'.D5>),
(<Cell 'Sheet1'.A6>, <Cell 'Sheet1'.B6>, <Cell 'Sheet1'.C6>, <Cell 'Sheet1'.D6>),
(<Cell 'Sheet1'.A7>, <Cell 'Sheet1'.B7>, <Cell 'Sheet1'.C7>, <Cell 'Sheet1'.D7>),
(<Cell 'Sheet1'.A8>, <Cell 'Sheet1'.B8>, <Cell 'Sheet1'.C8>, <Cell 'Sheet1'.D8>),
(<Cell 'Sheet1'.A9>, <Cell 'Sheet1'.B9>, <Cell 'Sheet1'.C9>, <Cell 'Sheet1'.D9>),
(<Cell 'Sheet1'.A10>, <Cell 'Sheet1'.B10>, <Cell 'Sheet1'.C10>, <Cell 'Sheet1'.D10>),
(<Cell 'Sheet1'.A11>, <Cell 'Sheet1'.B11>, <Cell 'Sheet1'.C11>, <Cell 'Sheet1'.D11>))You can see that by slicing the sheet data from A1:D11, it returned us tuples of row data inside a tuple. In order to read the values of every cell returned, you can iterate over each row and use .value.
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
# Access all cells from A1 to D11
for row in sheet["A1:D11"]:
print ([x.value for x in row])Output
['ProductId', 'ProductName', 'Cost per Unit', 'Quantity']
[1, 'Pencil', '$0.5', 200]
[2, 'Pen', '$1', 500]
[3, 'Eraser', '$0.25', 100]
[4, 'Sharpner', '$0.75', 100]
[5, 'Files', '$3', 50]
[6, 'A4 Size Paper', '$9', 10]
[7, 'Pencil Box', '$12', 20]
[8, 'Pen Stand', '$5.5', 10]
[9, 'Notebook', '$2', 50]
[10, 'Marker', '$1', 75]Method 2 — Reading a single row in Excel using cell name
To read a single row in your Excel sheet, just access the single row number from your sheet object.
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
# Access all cells in row 1
for data in sheet["1"]:
print(data.value)Output
ProductId
ProductName
Cost per Unit
QuantityMethod 3 — Reading all rows in Excel using rows attribute
To read all the rows, use sheet.rows to iterate over rows with Openpyxl. You receive a tuple element per row by using the sheet.rows attribute.
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
# Access all cells in row 1
for row in sheet.rows:
print([data.value for data in row])Output
['ProductId', 'ProductName', 'Cost per Unit', 'Quantity']
[1, 'Pencil', '$0.5', 200]
[2, 'Pen', '$1', 500]
[3, 'Eraser', '$0.25', 100]
[4, 'Sharpner', '$0.75', 100]
[5, 'Files', '$3', 50]
[6, 'A4 Size Paper', '$9', 10]
[7, 'Pencil Box', '$12', 20]
[8, 'Pen Stand', '$5.5', 10]
[9, 'Notebook', '$2', 50]
[10, 'Marker', '$1', 75]Method 4 — Reading a single column in Excel using cell name
Similar to reading a single row, you can read the data in a single column of your Excel sheet by its alphabet.
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
# Access all cells in column A
for data in sheet["A"]:
print(data.value)Output
ProductId
1
2
3
4
5
6
7
8
9
10Method 5 — Reading all the columns in Excel using columns attribute
To read all the data as a tuple of the columns in your Excel sheet, use sheet.columns attribute to iterate over all columns with Openpyxl.
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
# Access all columns
for col in sheet.columns:
print([data.value for data in col])Output
['ProductId', 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
['ProductName', 'Pencil', 'Pen', 'Eraser', 'Sharpner', 'Files', 'A4 Size Paper', 'Pencil Box', 'Pen Stand', 'Notebook', 'Marker']
['Cost per Unit', '$0.5', '$1', '$0.25', '$0.75', '$3', '$9', '$12', '$5.5', '$2', '$1']
['Quantity', 200, 500, 100, 100, 50, 10, 20, 10, 50, 75]Method 6 — Reading all the data in Excel
To read all the data present in your Excel sheet, you don’t need to index the sheet object. You can just iterate over it.
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
# Access all cells in Excel
for row in sheet:
print([data.value for data in row])Output
['ProductId', 'ProductName', 'Cost per Unit', 'Quantity']
[1, 'Pencil', '$0.5', 200]
[2, 'Pen', '$1', 500]
[3, 'Eraser', '$0.25', 100]
[4, 'Sharpner', '$0.75', 100]
[5, 'Files', '$3', 50]
[6, 'A4 Size Paper', '$9', 10]
[7, 'Pencil Box', '$12', 20]
[8, 'Pen Stand', '$5.5', 10]
[9, 'Notebook', '$2', 50]
[10, 'Marker', '$1', 75]Find the max row and column number of an Excel Sheet in Python
To find the max row and column number from your Excel sheet in Python, use sheet.max_row and sheet.max_column attributes in Openpyxl.
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
print(f"Max row in the active sheet is {sheet.max_row}")
print(f"Max column in the active sheet is {sheet.max_column}")Output
Max row in the active sheet is 11
Max column in the active sheet is 4Note — If you update a cell with a value, the sheet.max_row and sheet.max_column values also change, even though you haven’t saved your changes.
Code
from openpyxl import load_workbook
wb = load_workbook('pylenin.xlsx')
sheet = wb.active
sheet["A1"].value = "Lenin"
print(sheet.max_row)
sheet["A2"].value = "Mishra"
print(sheet.max_row)
# wb.save('pylenin.xlsx')Output
1
2How to iterate over Excel rows and columns in Python?
Openpyxl offers two commonly used methods called iter_rows and iter_cols to iterate over Excel rows and columns in Python.
iter_rows()— Returns one tuple element per row selected.iter_cols()— Returns one tuple element per column selected.
Both the above mentioned methods can receive the following arguments for setting boundaries for iteration:
- min_row
- max_row
- min_col
- max_col
Example 1 — iter_rows()
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
# Access all cells from between
# "Row 1 and Row 2" and "Column 1 and Column 3"
for row in sheet.iter_rows(min_row=1,
max_row=2,
min_col=1,
max_col=3):
print([data.value for data in row])Output
['ProductId', 'ProductName', 'Cost per Unit']
[1, 'Pencil', '$0.5']As you can see, only the first 3 columns of the first 2 rows are returned. The tuples are row based.
You can also choose to not pass in some or any arguments in iter_rows method.
Code — Not passing min_col and max_col
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
# min_col and max_col arguments are not provided
for row in sheet.iter_rows(min_row=1,
max_row=2):
print([data.value for data in row])Output
['ProductId', 'ProductName', 'Cost per Unit', 'Quantity']
[1, 'Pencil', '$0.5', 200]All the columns from the first 2 rows are being printed.
Example 2 — iter_cols()
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
# Access all cells from A1 to D11
for row in sheet.iter_cols(min_row=1,
max_row=2,
min_col=1,
max_col=3):
print([data.value for data in row])Output
['ProductId', 1]
['ProductName', 'Pencil']
['Cost per Unit', '$0.5']The tuples returned are column based on using iter_cols() method.
You can also choose to not pass in some or any arguments in iter_cols() method.
Code — Not passing any argument
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
# min_col and max_col arguments are not provided
for row in sheet.iter_cols():
print([data.value for data in row])Output
['ProductId', 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
['ProductName', 'Pencil', 'Pen', 'Eraser', 'Sharpner', 'Files', 'A4 Size Paper', 'Pencil Box', 'Pen Stand', 'Notebook', 'Marker']
['Cost per Unit', '$0.5', '$1', '$0.25', '$0.75', '$3', '$9', '$12', '$5.5', '$2', '$1']
['Quantity', 200, 500, 100, 100, 50, 10, 20, 10, 50, 75]Create a new Excel file with Python
To create a new Excel file in Python, you need to import the Workbook class from Openpyxl library.
Code
from openpyxl import Workbook
wb = Workbook()
sheet = wb.active
sheet['A1'] = "Pylenin"
sheet['B1'] = "loves"
sheet['C1'] = "Python"
wb.save("pylenin.xlsx")This should create a new Excel workbook called pylenin.xlsx with the provided data.

Writing data to Excel in Python
There are multiple ways to write data to an Excel file in Python.
Method 1 — Writing data to Excel using cell names
Code
from openpyxl import Workbook
wb = Workbook()
sheet = wb.active
sheet['A1'] = "Pylenin"
sheet['B1'] = "loves"
sheet['C1'] = "Python"
wb.save("pylenin.xlsx")Output

Method 2 — Writing data to Excel using the cell() method
Code
from openpyxl import Workbook
wb = Workbook()
sheet = wb.active
sheet.cell(row=1, column=1).value = "Pylenin"
sheet.cell(row=1, column=2).value = "loves"
sheet.cell(row=1, column=3).value = "Python"
wb.save("pylenin.xlsx")Output

Method 3 — Writing data to Excel by iterating over rows
Code — Example 1
from openpyxl import Workbook
wb = Workbook()
sheet = wb.active
for row in sheet["A1:D3"]:
row[0].value = "Pylenin"
row[1].value = "loves"
row[2].value = "Python"
wb.save("pylenin.xlsx")Output

You can also use methods like iter_rows() and iter_cols() to write data to Excel.
Code — Example 2 — using iter_rows() method
from openpyxl import Workbook
wb = Workbook()
sheet = wb.active
for row in sheet.iter_rows(min_row=1,
max_row=3,
min_col=1,
max_col=3):
row[0].value = "Pylenin"
row[1].value = "loves"
row[2].value = "Python"
wb.save("pylenin.xlsx")Output

Code — Example 3 — using iter_cols() method
from openpyxl import Workbook
wb = Workbook()
sheet = wb.active
for col in sheet.iter_cols(min_row=1,
max_row=3,
min_col=1,
max_col=3):
col[0].value = "Pylenin"
col[1].value = "loves"
col[2].value = "Python"
wb.save("pylenin.xlsx")Output

Appending data to Excel in Python
Openpyxl provides an append() method, which is used to append values to an existing Excel sheet in Python.
Code
from openpyxl import load_workbook
wb = load_workbook('pylenin.xlsx')
sheet = wb.active
data = (
("Pylenin", "likes", "icecream"),
("Pylenin", "likes", "Cricket")
)
for row in data:
sheet.append(row)
wb.save('pylenin.xlsx')Output

Manipulating Excel Sheets in Python
Each Excel workbook can contain multiple sheets. To get a list of all the sheet names in an Excel workbook, you can use the wb.sheetnames.
Code
from openpyxl import load_workbook
wb = load_workbook('pylenin.xlsx')
print(wb.sheetnames)Output
['Sheet']As you can see, pylenin.xlsx has only one sheet.
To create a new sheet in Python, use the create_sheet() method from the Openpyxl library.
Code
from openpyxl import load_workbook
wb = load_workbook('pylenin.xlsx')
wb.create_sheet('Pylenin')
wb.save('pylenin.xlsx')Output

You can also create sheets at different positions in the Excel Workbook.
Code
from openpyxl import load_workbook
wb = load_workbook('pylenin.xlsx')
# insert sheet at 2nd to last position
wb.create_sheet('Lenin Mishra', -1)
wb.save('pylenin.xlsx')Output

If your Excel workbook contains multiple sheets and you want to work with a particular sheet, you can refer the title of that sheet in your workbook object.
Code
from openpyxl import load_workbook
wb = load_workbook('pylenin.xlsx')
ws = wb["Pylenin"]
ws["A1"].value = "Pylenin"
ws["A2"].value = "loves"
ws["A3"].value = "Python"
wb.save('pylenin.xlsx')Output

Practical usage example of data analysis of Excel sheets in Python
Let’s perform some data analysis with wb1.xlsx file as shown in the first image.
Objective
- Add a new column showing
Total Price per Product. - Calculate the
Total Costof all the items bought.
The resulting Excel sheet should look like the below image.

Step 1 — Find the max row and max column of the Excel sheet
As mentioned before, you can use the sheet.max_row and sheet.max_column attributes to find the max row and max column for any Excel sheet with Openpyxl.
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
print(f"Max row in the active sheet is {sheet.max_row}")
print(f"Max column in the active sheet is {sheet.max_column}")Output
Max row in the active sheet is 11
Max column in the active sheet is 4
Step 2 — Add an extra column in Excel with Python

To add an extra column in the active Excel sheet, with calculations, you need to first create a new column header in the first empty cell and then iterate over all rows to multiply Quantity with Cost per Unit.
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
# Add new column header
sheet.cell(row=1, column=sheet.max_column+1).value = "Total Price per Product"
wb.save("wb1.xlsx")Output

Now that an extra column header has been created, the sheet.max_column value will change to 5.
Now you can calculate the Total Price per Product using iter_rows() method.
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
# Calculate Total Price per Product
for id, row in enumerate(sheet.iter_rows(min_row=2,
max_row = sheet.max_row)):
row_number = id + 2 # index for enumerate will start at 0
product_name = row[1].value
cost_per_unit = row[2].value
quantity = row[3].value
print(f"Total cost for {product_name} is {cost_per_unit*quantity}")
# Update cell value in the last column
current_cell = sheet.cell(row=row_number, column=sheet.max_column)
current_cell.value = cost_per_unit*quantity
# Format cell from number to $ currency
current_cell.number_format = '$#,#0.0'
print("nSuccesfully updated Excel")
wb.save('wb1.xlsx')Output
Total cost for Pencil is 100.0
Total cost for Pen is 500
Total cost for Eraser is 25.0
Total cost for Sharpner is 75.0
Total cost for Files is 150
Total cost for A4 Size Paper is 90
Total cost for Pencil Box is 240
Total cost for Pen Stand is 55.0
Total cost for Notebook is 100
Total cost for Marker is 75
Succesfully updated Excel
Step 3 — Calculate sum of a column in Excel with Python
The last step is to calculate the Total Cost of the last column in the Excel file.
Access the last column and add up all the cost.
You can read the last column by accessing the sheet.columns attribute. Since it returns a generator, you first convert it to a python list and access the last column.
last_column_data = list(sheet.columns)[-1]
# Ignore header cell
total_cost = sum([x.value for x in last_column_data[1:]])Create a new row 2 places down from the max_row and fill in Total Cost.
max_row = sheet.max_row
total_cost_descr_cell = sheet.cell(row = max_row +2, column = sheet.max_column -1)
total_cost_descr_cell.value = "Total Cost"
total_cost_cell = sheet.cell(row = max_row +2, column = sheet.max_column)
total_cost_cell.value = total_costImport Font class from openpyxl.styles to make the last row Bold.
# Import the Font class from Openpyxl
from openpyxl.styles import Font
bold_font = Font(bold=True)
total_cost_descr_cell.font = bold_font
total_cost_cell.font = bold_font
total_cost_cell.number_format = "$#,#0.0"Final Code
Code
from openpyxl import load_workbook
wb = load_workbook('wb1.xlsx')
sheet = wb.active
last_column_data = list(sheet.columns)[-1]
# Ignore header cell
total_cost = sum([x.value for x in last_column_data[1:]])
max_row = sheet.max_row
total_cost_descr_cell = sheet.cell(row = max_row + 2, column = sheet.max_column -1)
total_cost_descr_cell.value = "Total Cost"
total_cost_cell = sheet.cell(row = max_row + 2, column = sheet.max_column)
total_cost_cell.value = total_cost
# Import the Font class from Openpyxl
from openpyxl.styles import Font
bold_font = Font(bold=True)
total_cost_descr_cell.font = bold_font
total_cost_cell.font = bold_font
total_cost_cell.number_format = "$#,#0.0"
print("nSuccesfully updated Excel")
wb.save('wb1.xlsx')When you run the above code, you should see all the relevant updates to your Excel sheet.

Microsoft Excel is one of the most powerful spreadsheet software applications in the world, and it has become critical in all business processes. Companies across the world, both big and small, are using Microsoft Excel to store, organize, analyze, and visualize data.
As a data professional, when you combine Python with Excel, you create a unique data analysis bundle that unlocks the value of the enterprise data.
In this tutorial, we’re going to learn how to read and work with Excel files in Python.
After you finish this tutorial, you’ll understand the following:
- Loading Excel spreadsheets into pandas DataFrames
- Working with an Excel workbook with multiple spreadsheets
- Combining multiple spreadsheets
- Reading Excel files using the
xlrdpackage
In this tutorial, we assume you know the fundamentals of pandas DataFrames. If you aren’t familiar with the pandas library, you might like to try our Pandas and NumPy Fundamentals – Dataquest.
Let’s dive in.
Reading Spreadsheets with Pandas
Technically, multiple packages allow us to work with Excel files in Python. However, in this tutorial, we’ll use pandas and xlrd libraries to interact with Excel workbooks. Essentially, you can think of a pandas DataFrame as a spreadsheet with rows and columns stored in Series objects. Traversability of Series as iterable objects allows us to grab specific data easily. Once we load an Excel workbook into a pandas DataFrame, we can perform any kind of data analysis on the data.
Before we proceed to the next step, let’s first download the following spreadsheet:
Sales Data Excel Workbook — xlsx ver.
The Excel workbook consists of two sheets that contain stationery sales data for 2020 and 2021.
NOTE
Although Excel spreadsheets can contain formula and also support formatting, pandas only imports Excel spreadsheets as flat files, and it doesn’t support spreadsheet formatting.
To import the Excel spreadsheet into a pandas DataFrame, first, we need to import the pandas package and then use the read_excel() method:
import pandas as pd
df = pd.read_excel('sales_data.xlsx')
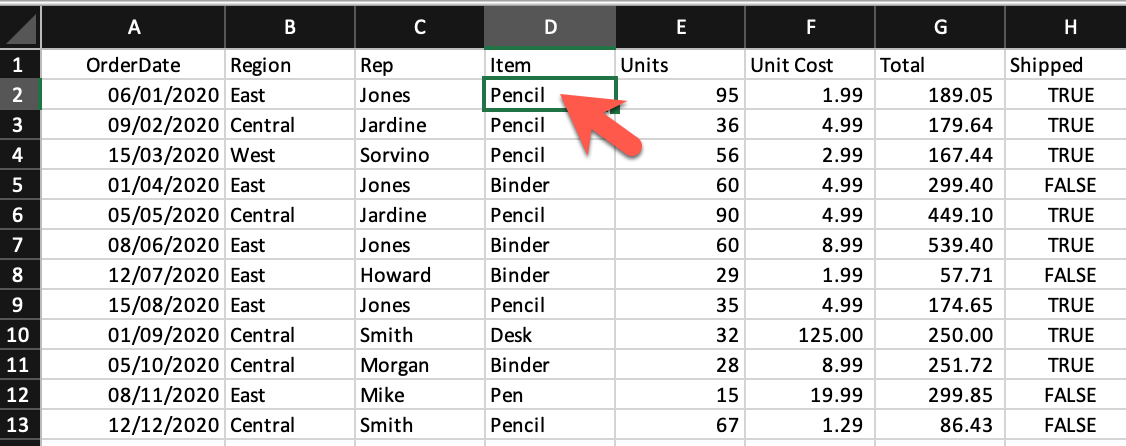
display(df)| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-01-06 | East | Jones | Pencil | 95 | 1.99 | 189.05 | True |
| 1 | 2020-02-09 | Central | Jardine | Pencil | 36 | 4.99 | 179.64 | True |
| 2 | 2020-03-15 | West | Sorvino | Pencil | 56 | 2.99 | 167.44 | True |
| 3 | 2020-04-01 | East | Jones | Binder | 60 | 4.99 | 299.40 | False |
| 4 | 2020-05-05 | Central | Jardine | Pencil | 90 | 4.99 | 449.10 | True |
| 5 | 2020-06-08 | East | Jones | Binder | 60 | 8.99 | 539.40 | True |
| 6 | 2020-07-12 | East | Howard | Binder | 29 | 1.99 | 57.71 | False |
| 7 | 2020-08-15 | East | Jones | Pencil | 35 | 4.99 | 174.65 | True |
| 8 | 2020-09-01 | Central | Smith | Desk | 32 | 125.00 | 250.00 | True |
| 9 | 2020-10-05 | Central | Morgan | Binder | 28 | 8.99 | 251.72 | True |
| 10 | 2020-11-08 | East | Mike | Pen | 15 | 19.99 | 299.85 | False |
| 11 | 2020-12-12 | Central | Smith | Pencil | 67 | 1.29 | 86.43 | False |
If you want to load only a limited number of rows into the DataFrame, you can specify the number of rows using the nrows argument:
df = pd.read_excel('sales_data.xlsx', nrows=5)
display(df)| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-01-06 | East | Jones | Pencil | 95 | 1.99 | 189.05 | True |
| 1 | 2020-02-09 | Central | Jardine | Pencil | 36 | 4.99 | 179.64 | True |
| 2 | 2020-03-15 | West | Sorvino | Pencil | 56 | 2.99 | 167.44 | True |
| 3 | 2020-04-01 | East | Jones | Binder | 60 | 4.99 | 299.40 | False |
| 4 | 2020-05-05 | Central | Jardine | Pencil | 90 | 4.99 | 449.10 | True |
Skipping a specific number of rows from the begining of a spreadsheet or skipping over a list of particular rows is available through the skiprows argument, as follows:
df = pd.read_excel('sales_data.xlsx', skiprows=range(5))
display(df)| 2020-05-05 00:00:00 | Central | Jardine | Pencil | 90 | 4.99 | 449.1 | True | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-06-08 | East | Jones | Binder | 60 | 8.99 | 539.40 | True |
| 1 | 2020-07-12 | East | Howard | Binder | 29 | 1.99 | 57.71 | False |
| 2 | 2020-08-15 | East | Jones | Pencil | 35 | 4.99 | 174.65 | True |
| 3 | 2020-09-01 | Central | Smith | Desk | 32 | 125.00 | 250.00 | True |
| 4 | 2020-10-05 | Central | Morgan | Binder | 28 | 8.99 | 251.72 | True |
| 5 | 2020-11-08 | East | Mike | Pen | 15 | 19.99 | 299.85 | False |
| 6 | 2020-12-12 | Central | Smith | Pencil | 67 | 1.29 | 86.43 | False |
The code above skips the first five rows and returns the rest of the data. Instead, the following code returns all the rows except for those with the mentioned indices:
df = pd.read_excel('sales_data.xlsx', skiprows=[1, 4,7,10])
display(df)| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-02-09 | Central | Jardine | Pencil | 36 | 4.99 | 179.64 | True |
| 1 | 2020-03-15 | West | Sorvino | Pencil | 56 | 2.99 | 167.44 | True |
| 2 | 2020-05-05 | Central | Jardine | Pencil | 90 | 4.99 | 449.10 | True |
| 3 | 2020-06-08 | East | Jones | Binder | 60 | 8.99 | 539.40 | True |
| 4 | 2020-08-15 | East | Jones | Pencil | 35 | 4.99 | 174.65 | True |
| 5 | 2020-09-01 | Central | Smith | Desk | 32 | 125.00 | 250.00 | True |
| 6 | 2020-11-08 | East | Mike | Pen | 15 | 19.99 | 299.85 | False |
| 7 | 2020-12-12 | Central | Smith | Pencil | 67 | 1.29 | 86.43 | False |
Another useful argument is usecols, which allows us to select spreadsheet columns with their letters, names, or positional numbers. Let’s see how it works:
df = pd.read_excel('sales_data.xlsx', usecols='A:C,G')
display(df)| OrderDate | Region | Rep | Total | |
|---|---|---|---|---|
| 0 | 2020-01-06 | East | Jones | 189.05 |
| 1 | 2020-02-09 | Central | Jardine | 179.64 |
| 2 | 2020-03-15 | West | Sorvino | 167.44 |
| 3 | 2020-04-01 | East | Jones | 299.40 |
| 4 | 2020-05-05 | Central | Jardine | 449.10 |
| 5 | 2020-06-08 | East | Jones | 539.40 |
| 6 | 2020-07-12 | East | Howard | 57.71 |
| 7 | 2020-08-15 | East | Jones | 174.65 |
| 8 | 2020-09-01 | Central | Smith | 250.00 |
| 9 | 2020-10-05 | Central | Morgan | 251.72 |
| 10 | 2020-11-08 | East | Mike | 299.85 |
| 11 | 2020-12-12 | Central | Smith | 86.43 |
In the code above, the string assigned to the usecols argument contains a range of columns with : plus column G separated by a comma. Also, we’re able to provide a list of column names and assign it to the usecols argument, as follows:
df = pd.read_excel('sales_data.xlsx', usecols=['OrderDate', 'Region', 'Rep', 'Total'])
display(df)| OrderDate | Region | Rep | Total | |
|---|---|---|---|---|
| 0 | 2020-01-06 | East | Jones | 189.05 |
| 1 | 2020-02-09 | Central | Jardine | 179.64 |
| 2 | 2020-03-15 | West | Sorvino | 167.44 |
| 3 | 2020-04-01 | East | Jones | 299.40 |
| 4 | 2020-05-05 | Central | Jardine | 449.10 |
| 5 | 2020-06-08 | East | Jones | 539.40 |
| 6 | 2020-07-12 | East | Howard | 57.71 |
| 7 | 2020-08-15 | East | Jones | 174.65 |
| 8 | 2020-09-01 | Central | Smith | 250.00 |
| 9 | 2020-10-05 | Central | Morgan | 251.72 |
| 10 | 2020-11-08 | East | Mike | 299.85 |
| 11 | 2020-12-12 | Central | Smith | 86.43 |
The usecols argument accepts a list of column numbers, too. The following code shows how we can pick up specific columns using their indices:
df = pd.read_excel('sales_data.xlsx', usecols=[0, 1, 2, 6])
display(df)| OrderDate | Region | Rep | Total | |
|---|---|---|---|---|
| 0 | 2020-01-06 | East | Jones | 189.05 |
| 1 | 2020-02-09 | Central | Jardine | 179.64 |
| 2 | 2020-03-15 | West | Sorvino | 167.44 |
| 3 | 2020-04-01 | East | Jones | 299.40 |
| 4 | 2020-05-05 | Central | Jardine | 449.10 |
| 5 | 2020-06-08 | East | Jones | 539.40 |
| 6 | 2020-07-12 | East | Howard | 57.71 |
| 7 | 2020-08-15 | East | Jones | 174.65 |
| 8 | 2020-09-01 | Central | Smith | 250.00 |
| 9 | 2020-10-05 | Central | Morgan | 251.72 |
| 10 | 2020-11-08 | East | Mike | 299.85 |
| 11 | 2020-12-12 | Central | Smith | 86.43 |
Working with Multiple Spreadsheets
Excel files or workbooks usually contain more than one spreadsheet. The pandas library allows us to load data from a specific sheet or combine multiple spreadsheets into a single DataFrame. In this section, we’ll explore how to use these valuable capabilities.
By default, the read_excel() method reads the first Excel sheet with the index 0. However, we can choose the other sheets by assigning a particular sheet name, sheet index, or even a list of sheet names or indices to the sheet_name argument. Let’s try it:
df = pd.read_excel('sales_data.xlsx', sheet_name='2021')
display(df)| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2021-01-15 | Central | Gill | Binder | 46 | 8.99 | 413.54 | True |
| 1 | 2021-02-01 | Central | Smith | Binder | 87 | 15.00 | 1305.00 | True |
| 2 | 2021-03-07 | West | Sorvino | Binder | 27 | 19.99 | 139.93 | True |
| 3 | 2021-04-10 | Central | Andrews | Pencil | 66 | 1.99 | 131.34 | False |
| 4 | 2021-05-14 | Central | Gill | Pencil | 53 | 1.29 | 68.37 | False |
| 5 | 2021-06-17 | Central | Tom | Desk | 15 | 125.00 | 625.00 | True |
| 6 | 2021-07-04 | East | Jones | Pen Set | 62 | 4.99 | 309.38 | True |
| 7 | 2021-08-07 | Central | Tom | Pen Set | 42 | 23.95 | 1005.90 | True |
| 8 | 2021-09-10 | Central | Gill | Pencil | 47 | 1.29 | 9.03 | True |
| 9 | 2021-10-14 | West | Thompson | Binder | 57 | 19.99 | 1139.43 | False |
| 10 | 2021-11-17 | Central | Jardine | Binder | 11 | 4.99 | 54.89 | False |
| 11 | 2021-12-04 | Central | Jardine | Binder | 94 | 19.99 | 1879.06 | False |
The code above reads the second spreadsheet in the workbook, whose name is 2021. As mentioned before, we also can assign a sheet position number (zero-indexed) to the sheet_name argument. Let’s see how it works:
df = pd.read_excel('sales_data.xlsx', sheet_name=1)
display(df)| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2021-01-15 | Central | Gill | Binder | 46 | 8.99 | 413.54 | True |
| 1 | 2021-02-01 | Central | Smith | Binder | 87 | 15.00 | 1305.00 | True |
| 2 | 2021-03-07 | West | Sorvino | Binder | 27 | 19.99 | 139.93 | True |
| 3 | 2021-04-10 | Central | Andrews | Pencil | 66 | 1.99 | 131.34 | False |
| 4 | 2021-05-14 | Central | Gill | Pencil | 53 | 1.29 | 68.37 | False |
| 5 | 2021-06-17 | Central | Tom | Desk | 15 | 125.00 | 625.00 | True |
| 6 | 2021-07-04 | East | Jones | Pen Set | 62 | 4.99 | 309.38 | True |
| 7 | 2021-08-07 | Central | Tom | Pen Set | 42 | 23.95 | 1005.90 | True |
| 8 | 2021-09-10 | Central | Gill | Pencil | 47 | 1.29 | 9.03 | True |
| 9 | 2021-10-14 | West | Thompson | Binder | 57 | 19.99 | 1139.43 | False |
| 10 | 2021-11-17 | Central | Jardine | Binder | 11 | 4.99 | 54.89 | False |
| 11 | 2021-12-04 | Central | Jardine | Binder | 94 | 19.99 | 1879.06 | False |
As you can see, both statements take in either the actual sheet name or sheet index to return the same result.
Sometimes, we want to import all the spreadsheets stored in an Excel file into pandas DataFrames simultaneously. The good news is that the read_excel() method provides this feature for us. In order to do this, we can assign a list of sheet names or their indices to the sheet_name argument. But there is a much easier way to do the same: to assign None to the sheet_name argument. Let’s try it:
all_sheets = pd.read_excel('sales_data.xlsx', sheet_name=None)Before exploring the data stored in the all_sheets variable, let’s check its data type:
type(all_sheets)dictAs you can see, the variable is a dictionary. Now, let’s reveal what is stored in this dictionary:
for key, value in all_sheets.items():
print(key, type(value))2020 <class 'pandas.core.frame.DataFrame'>
2021 <class 'pandas.core.frame.DataFrame'>The code above shows that the dictionary’s keys are the Excel workbook sheet names, and its values are pandas DataFrames for each spreadsheet. To print out the content of the dictionary, we can use the following code:
for key, value in all_sheets.items():
print(key)
display(value)2020| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-01-06 | East | Jones | Pencil | 95 | 1.99 | 189.05 | True |
| 1 | 2020-02-09 | Central | Jardine | Pencil | 36 | 4.99 | 179.64 | True |
| 2 | 2020-03-15 | West | Sorvino | Pencil | 56 | 2.99 | 167.44 | True |
| 3 | 2020-04-01 | East | Jones | Binder | 60 | 4.99 | 299.40 | False |
| 4 | 2020-05-05 | Central | Jardine | Pencil | 90 | 4.99 | 449.10 | True |
| 5 | 2020-06-08 | East | Jones | Binder | 60 | 8.99 | 539.40 | True |
| 6 | 2020-07-12 | East | Howard | Binder | 29 | 1.99 | 57.71 | False |
| 7 | 2020-08-15 | East | Jones | Pencil | 35 | 4.99 | 174.65 | True |
| 8 | 2020-09-01 | Central | Smith | Desk | 32 | 125.00 | 250.00 | True |
| 9 | 2020-10-05 | Central | Morgan | Binder | 28 | 8.99 | 251.72 | True |
| 10 | 2020-11-08 | East | Mike | Pen | 15 | 19.99 | 299.85 | False |
| 11 | 2020-12-12 | Central | Smith | Pencil | 67 | 1.29 | 86.43 | False |
2021| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2021-01-15 | Central | Gill | Binder | 46 | 8.99 | 413.54 | True |
| 1 | 2021-02-01 | Central | Smith | Binder | 87 | 15.00 | 1305.00 | True |
| 2 | 2021-03-07 | West | Sorvino | Binder | 27 | 19.99 | 139.93 | True |
| 3 | 2021-04-10 | Central | Andrews | Pencil | 66 | 1.99 | 131.34 | False |
| 4 | 2021-05-14 | Central | Gill | Pencil | 53 | 1.29 | 68.37 | False |
| 5 | 2021-06-17 | Central | Tom | Desk | 15 | 125.00 | 625.00 | True |
| 6 | 2021-07-04 | East | Jones | Pen Set | 62 | 4.99 | 309.38 | True |
| 7 | 2021-08-07 | Central | Tom | Pen Set | 42 | 23.95 | 1005.90 | True |
| 8 | 2021-09-10 | Central | Gill | Pencil | 47 | 1.29 | 9.03 | True |
| 9 | 2021-10-14 | West | Thompson | Binder | 57 | 19.99 | 1139.43 | False |
| 10 | 2021-11-17 | Central | Jardine | Binder | 11 | 4.99 | 54.89 | False |
| 11 | 2021-12-04 | Central | Jardine | Binder | 94 | 19.99 | 1879.06 | False |
Combining Multiple Excel Spreadsheets into a Single Pandas DataFrame
Having one DataFrame per sheet allows us to have different columns or content in different sheets.
But what if we prefer to store all the spreadsheets’ data in a single DataFrame? In this tutorial, the workbook spreadsheets have the same columns, so we can combine them with the concat() method of pandas.
If you run the code below, you’ll see that the two DataFrames stored in the dictionary are concatenated:
combined_df = pd.concat(all_sheets.values(), ignore_index=True)
display(combined_df)| OrderDate | Region | Rep | Item | Units | Unit Cost | Total | Shipped | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2020-01-06 | East | Jones | Pencil | 95 | 1.99 | 189.05 | True |
| 1 | 2020-02-09 | Central | Jardine | Pencil | 36 | 4.99 | 179.64 | True |
| 2 | 2020-03-15 | West | Sorvino | Pencil | 56 | 2.99 | 167.44 | True |
| 3 | 2020-04-01 | East | Jones | Binder | 60 | 4.99 | 299.40 | False |
| 4 | 2020-05-05 | Central | Jardine | Pencil | 90 | 4.99 | 449.10 | True |
| 5 | 2020-06-08 | East | Jones | Binder | 60 | 8.99 | 539.40 | True |
| 6 | 2020-07-12 | East | Howard | Binder | 29 | 1.99 | 57.71 | False |
| 7 | 2020-08-15 | East | Jones | Pencil | 35 | 4.99 | 174.65 | True |
| 8 | 2020-09-01 | Central | Smith | Desk | 32 | 125.00 | 250.00 | True |
| 9 | 2020-10-05 | Central | Morgan | Binder | 28 | 8.99 | 251.72 | True |
| 10 | 2020-11-08 | East | Mike | Pen | 15 | 19.99 | 299.85 | False |
| 11 | 2020-12-12 | Central | Smith | Pencil | 67 | 1.29 | 86.43 | False |
| 12 | 2021-01-15 | Central | Gill | Binder | 46 | 8.99 | 413.54 | True |
| 13 | 2021-02-01 | Central | Smith | Binder | 87 | 15.00 | 1305.00 | True |
| 14 | 2021-03-07 | West | Sorvino | Binder | 27 | 19.99 | 139.93 | True |
| 15 | 2021-04-10 | Central | Andrews | Pencil | 66 | 1.99 | 131.34 | False |
| 16 | 2021-05-14 | Central | Gill | Pencil | 53 | 1.29 | 68.37 | False |
| 17 | 2021-06-17 | Central | Tom | Desk | 15 | 125.00 | 625.00 | True |
| 18 | 2021-07-04 | East | Jones | Pen Set | 62 | 4.99 | 309.38 | True |
| 19 | 2021-08-07 | Central | Tom | Pen Set | 42 | 23.95 | 1005.90 | True |
| 20 | 2021-09-10 | Central | Gill | Pencil | 47 | 1.29 | 9.03 | True |
| 21 | 2021-10-14 | West | Thompson | Binder | 57 | 19.99 | 1139.43 | False |
| 22 | 2021-11-17 | Central | Jardine | Binder | 11 | 4.99 | 54.89 | False |
| 23 | 2021-12-04 | Central | Jardine | Binder | 94 | 19.99 | 1879.06 | False |
Now the data stored in the combined_df DataFrame is ready for further processing or visualization. In the following piece of code, we’re going to create a simple bar chart that shows the total sales amount made by each representative. Let’s run it and see the output plot:
total_sales_amount = combined_df.groupby('Rep').Total.sum()
total_sales_amount.plot.bar(figsize=(10, 6))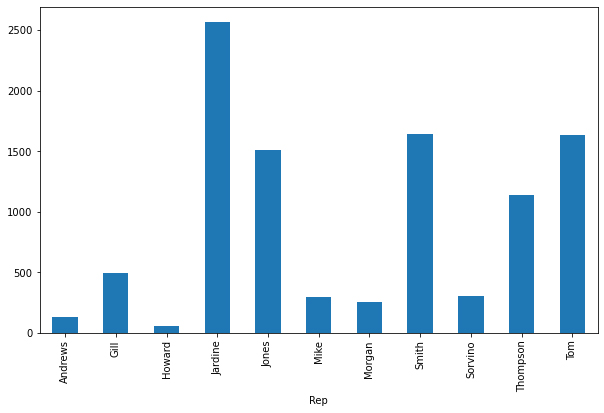
Reading Excel Files Using xlrd
Although importing data into a pandas DataFrame is much more common, another helpful package for reading Excel files in Python is xlrd. In this section, we’re going to scratch the surface of how to read Excel spreadsheets using this package.
NOTE
The xlrd package doesn’t support xlsx files due to a potential security vulnerability. So, we use the xls version of the sales data. You can download the xls version from the link below:
Sales Data Excel Workbook — xls ver.
Let’s see how it works:
import xlrd
excel_workbook = xlrd.open_workbook('sales_data.xls')Above, the first line imports the xlrd package, then the open_workbook method reads the sales_data.xls file.
We can also open an individual sheet containing the actual data. There are two ways to do so: opening a sheet by index or by name. Let’s open the first sheet by index and the second one by name:
excel_worksheet_2020 = excel_workbook.sheet_by_index(0)
excel_worksheet_2021 = excel_workbook.sheet_by_name('2021')Now, let’s see how we can print a cell value. The xlrd package provides a method called cell_value() that takes in two arguments: the cell’s row index and column index. Let’s explore it:
print(excel_worksheet_2020.cell_value(1, 3))PencilWe can see that the cell_value function returned the value of the cell at row index 1 (the 2nd row) and column index 3 (the 4th column).
The xlrd package provides two helpful properties: nrows and ncols, returning the number of nonempty spreadsheet’s rows and columns respectively:
print('Columns#:', excel_worksheet_2020.ncols)
print('Rows#:', excel_worksheet_2020.nrows)Columns#: 8
Rows#: 13Knowing the number of nonempty rows and columns in a spreadsheet helps us with iterating over the data using nested for loops. This makes all the Excel sheet data accessible via the cell_value() method.
Conclusion
This tutorial discussed how to load Excel spreadsheets into pandas DataFrames, work with multiple Excel sheets, and combine them into a single pandas DataFrame. We also explored the main aspects of the xlrd package as one of the simplest tools for accessing the Excel spreadsheets data.
Узнайте, как читать и импортировать файлы Excel в Python, как записывать данные в эти таблицы и какие библиотеки лучше всего подходят для этого.
Известный вам инструмент для организации, анализа и хранения ваших данных в таблицах — Excel — применяется и в data science. В какой-то момент вам придется иметь дело с этими таблицами, но работать именно с ними вы будете не всегда. Вот почему разработчики Python реализовали способы чтения, записи и управления не только этими файлами, но и многими другими типами файлов.
Из этого учебника узнаете, как можете работать с Excel и Python. Внутри найдете обзор библиотек, которые вы можете использовать для загрузки и записи этих таблиц в файлы с помощью Python. Вы узнаете, как работать с такими библиотеками, как pandas, openpyxl, xlrd, xlutils и pyexcel.
Данные как ваша отправная точка
Когда вы начинаете проект по data science, вам придется работать с данными, которые вы собрали по всему интернету, и с наборами данных, которые вы загрузили из других мест — Kaggle, Quandl и тд
Но чаще всего вы также найдете данные в Google или в репозиториях, которые используются другими пользователями. Эти данные могут быть в файле Excel или сохранены в файл с расширением .csv … Возможности могут иногда казаться бесконечными, но когда у вас есть данные, в первую очередь вы должны убедиться, что они качественные.
В случае с электронной таблицей вы можете не только проверить, могут ли эти данные ответить на вопрос исследования, который вы имеете в виду, но также и можете ли вы доверять данным, которые хранятся в электронной таблице.
Проверяем качество таблицы
- Представляет ли электронная таблица статические данные?
- Смешивает ли она данные, расчеты и отчетность?
- Являются ли данные в вашей электронной таблице полными и последовательными?
- Имеет ли ваша таблица систематизированную структуру рабочего листа?
- Проверяли ли вы действительные формулы в электронной таблице?
Этот список вопросов поможет убедиться, что ваша таблица не грешит против лучших практик, принятых в отрасли. Конечно, этот список не исчерпывающий, но позволит провести базовую проверку таблицы.
Лучшие практики для данных электронных таблиц
Прежде чем приступить к чтению вашей электронной таблицы на Python, вы также должны подумать о том, чтобы настроить свой файл в соответствии с некоторыми основными принципами, такими как:
- Первая строка таблицы обычно зарезервирована для заголовка, а первый столбец используется для идентификации единицы выборки;
- Избегайте имен, значений или полей с пробелами. В противном случае каждое слово будет интерпретироваться как отдельная переменная, что приведет к ошибкам, связанным с количеством элементов на строку в вашем наборе данных. По возможности, используйте:
- подчеркивания,
- тире,
- горбатый регистр, где первая буква каждого слова пишется с большой буквы
- объединяющие слова
- Короткие имена предпочтительнее длинных имен;
- старайтесь не использовать имена, которые содержат символы ?, $,%, ^, &, *, (,), -, #,? ,,, <,>, /, |, , [,], {, и };
- Удалите все комментарии, которые вы сделали в вашем файле, чтобы избежать добавления в ваш файл лишних столбцов или NA;
- Убедитесь, что все пропущенные значения в вашем наборе данных обозначены как NA.
Затем, после того, как вы внесли необходимые изменения или тщательно изучили свои данные, убедитесь, что вы сохранили внесенные изменения. Сделав это, вы можете вернуться к данным позже, чтобы отредактировать их, добавить дополнительные данные или изменить их, сохранив формулы, которые вы, возможно, использовали для расчета данных и т.д.
Если вы работаете с Microsoft Excel, вы можете сохранить файл в разных форматах: помимо расширения по умолчанию .xls или .xlsx, вы можете перейти на вкладку «Файл», нажать «Сохранить как» и выбрать одно из расширений, которые указаны в качестве параметров «Сохранить как тип». Наиболее часто используемые расширения для сохранения наборов данных в data science — это .csv и .txt (в виде текстового файла с разделителями табуляции). В зависимости от выбранного варианта сохранения поля вашего набора данных разделяются вкладками или запятыми, которые образуют символы-разделители полей вашего набора данных.
Теперь, когда вы проверили и сохранили ваши данные, вы можете начать с подготовки вашего рабочего окружения.
Готовим рабочее окружение
Как убедиться, что вы все делаете хорошо? Проверить рабочее окружение!
Когда вы работаете в терминале, вы можете сначала перейти в каталог, в котором находится ваш файл, а затем запустить Python. Убедитесь, что файл лежит именно в том каталоге, к которому вы обратились.
Возможно, вы уже начали сеанс Python и у вас нет подсказок о каталоге, в котором вы работаете. Тогда можно выполнить следующие команды:
# Import `os`
import os
# Retrieve current working directory (`cwd`)
cwd = os.getcwd()
cwd
# Change directory
os.chdir("/path/to/your/folder")
# List all files and directories in current directory
os.listdir('.')Круто, да?
Вы увидите, что эти команды очень важны не только для загрузки ваших данных, но и для дальнейшего анализа. А пока давайте продолжим: вы прошли все проверки, вы сохранили свои данные и подготовили рабочее окружение.
Можете ли вы начать с чтения данных в Python?
Установите библиотеки для чтения и записи файлов Excel
Даже если вы еще не знаете, какие библиотеки вам понадобятся для импорта ваших данных, вы должны убедиться, что у вас есть все, что нужно для установки этих библиотек, когда придет время.
Подготовка к дополнительной рабочей области: pip
Вот почему вам нужно установить pip и setuptools. Если у вас установлен Python2 ⩾ 2.7.9 или Python3 ⩾ 3.4, то можно не беспокоиться — просто убедитесь, что вы обновились до последней версии.
Для этого выполните следующую команду в своем терминале:
# Для Linux/OS X
pip install -U pip setuptools
# Для Windows
python -m pip install -U pip setuptoolsЕсли вы еще не установили pip, запустите скрипт python get-pip.py, который вы можете найти здесь. Следуйте инструкциям по установке.
Установка Anaconda
Другой вариант для работы в data science — установить дистрибутив Anaconda Python. Сделав это, вы получите простой и быстрый способ начать заниматься data science, потому что вам не нужно беспокоиться об установке отдельных библиотек, необходимых для работы.
Это особенно удобно, если вы новичок, но даже для более опытных разработчиков это способ быстро протестировать некоторые вещи без необходимости устанавливать каждую библиотеку отдельно.
Anaconda включает в себя 100 самых популярных библиотек Python, R и Scala для науки о данных и несколько сред разработки с открытым исходным кодом, таких как Jupyter и Spyder.
Установить Anaconda можно здесь. Следуйте инструкциям по установке, и вы готовы начать!
Загрузить файлы Excel в виде фреймов Pandas
Все, среда настроена, вы готовы начать импорт ваших файлов.
Один из способов, который вы часто используете для импорта ваших файлов для обработки данных, — с помощью библиотеки Pandas. Она основана на NumPy и предоставляет простые в использовании структуры данных и инструменты анализа данных Python.
Эта мощная и гибкая библиотека очень часто используется дата-инженерами для передачи своих данных в структуры данных, очень выразительных для их анализа.
Если у вас уже есть Pandas, доступные через Anaconda, вы можете просто загрузить свои файлы в Pandas DataFrames с помощью pd.Excelfile():
# импорт библиотеки pandas
import pandas as pd
# Загружаем ваш файл в переменную `file` / вместо 'example' укажите название свого файла из текущей директории
file = 'example.xlsx'
# Загружаем spreadsheet в объект pandas
xl = pd.ExcelFile(file)
# Печатаем название листов в данном файле
print(xl.sheet_names)
# Загрузить лист в DataFrame по его имени: df1
df1 = xl.parse('Sheet1')Если вы не установили Anaconda, просто выполните pip install pandas, чтобы установить библиотеку Pandas в вашей среде, а затем выполните команды, которые включены в фрагмент кода выше.
Проще простого, да?
Для чтения в файлах .csv у вас есть аналогичная функция для загрузки данных в DataFrame: read_csv(). Вот пример того, как вы можете использовать эту функцию:
# Импорт библиотеки pandas
import pandas as pd
# Загрузить csv файл
df = pd.read_csv("example.csv") Разделитель, который будет учитывать эта функция, по умолчанию является запятой, но вы можете указать альтернативный разделитель, если хотите. Перейдите к документации, чтобы узнать, какие другие аргументы вы можете указать для успешного импорта!
Обратите внимание, что есть также функции read_table() и read_fwf() для чтения файлов и таблиц с фиксированной шириной в формате DataFrames с общим разделителем. Для первой функции разделителем по умолчанию является вкладка, но вы можете снова переопределить это, а также указать альтернативный символ-разделитель. Более того, есть и другие функции, которые вы можете использовать для получения данных в DataFrames: вы можете найти их здесь.
Как записать Pandas DataFrames в файлы Excel
Допустим, что после анализа данных вы хотите записать данные обратно в новый файл. Есть также способ записать ваши Pandas DataFrames обратно в файлы с помощью функции to_excel().
Но, прежде чем использовать эту функцию, убедитесь, что у вас установлен XlsxWriter, если вы хотите записать свои данные в несколько листов в файле .xlsx:
# Установим `XlsxWriter`
pip install XlsxWriter
# Указать writer библиотеки
writer = pd.ExcelWriter('example.xlsx', engine='xlsxwriter')
# Записать ваш DataFrame в файл
yourData.to_excel(writer, 'Sheet1')
# Сохраним результат
writer.save()Обратите внимание, что в приведенном выше фрагменте кода вы используете объект ExcelWriter для вывода DataFrame.
Иными словами, вы передаете переменную Writer в функцию to_excel() и также указываете имя листа. Таким образом, вы добавляете лист с данными в существующую рабочую книгу: вы можете использовать ExcelWriter для сохранения нескольких (немного) разных DataFrames в одной рабочей книге.
Все это означает, что если вы просто хотите сохранить один DataFrame в файл, вы также можете обойтись без установки пакета XlsxWriter. Затем вы просто не указываете аргумент движка, который вы передаете в функцию pd.ExcelWriter(). Остальные шаги остаются прежними.
Аналогично функциям, которые вы использовали для чтения в файлах .csv, у вас также есть функция to_csv() для записи результатов обратно в файл, разделенный запятыми. Он снова работает так же, как когда вы использовали его для чтения в файле:
# Запишите DataFrame в csv
df.to_csv("example.csv")Если вы хотите иметь файл, разделенный табуляцией, вы также можете передать t аргументу sep. Обратите внимание, что есть другие функции, которые вы можете использовать для вывода ваших файлов. Вы можете найти их все здесь.
Пакеты для разбора файлов Excel и обратной записи с помощью Python
Помимо библиотеки Pandas, который вы будете использовать очень часто для загрузки своих данных, вы также можете использовать другие библиотеки для получения ваших данных в Python. Наш обзор основан на этой странице со списком доступных библиотек, которые вы можете использовать для работы с файлами Excel в Python.
Далее вы увидите, как использовать эти библиотеки с помощью некоторых реальных, но упрощенных примеров.
Использование виртуальных сред
Общий совет для установки — делать это в Python virtualenv без системных пакетов. Вы можете использовать virtualenv для создания изолированных сред Python: он создает папку, содержащую все необходимые исполняемые файлы для использования пакетов, которые потребуются проекту Python.
Чтобы начать работать с virtualenv, вам сначала нужно установить его. Затем перейдите в каталог, в который вы хотите поместить свой проект. Создайте virtualenv в этой папке и загрузите в определенную версию Python, если вам это нужно. Затем вы активируете виртуальную среду. После этого вы можете начать загрузку в другие библиотеки, начать работать с ними и т. д.
Совет: не забудьте деактивировать среду, когда закончите!
# Install virtualenv
$ pip install virtualenv
# Go to the folder of your project
$ cd my_folder
# Create a virtual environment `venv`
$ virtualenv venv
# Indicate the Python interpreter to use for `venv`
$ virtualenv -p /usr/bin/python2.7 venv
# Activate `venv`
$ source venv/bin/activate
# Deactivate `venv`
$ deactivateОбратите внимание, что виртуальная среда может показаться немного проблемной на первый взгляд, когда вы только начинаете работать с данными с Python. И, особенно если у вас есть только один проект, вы можете не понять, зачем вам вообще нужна виртуальная среда.
С ней будет гораздо легче, когда у вас одновременно запущено несколько проектов, и вы не хотите, чтобы они использовали одну и ту же установку Python. Или когда ваши проекты имеют противоречащие друг другу требования, виртуальная среда пригодится!
Теперь вы можете, наконец, начать установку и импорт библиотек, о которых вы читали, и загрузить их в таблицу.
Как читать и записывать файлы Excel с openpyxl
Этот пакет обычно рекомендуется, если вы хотите читать и записывать файлы .xlsx, xlsm, xltx и xltm.
Установите openpyxl с помощью pip: вы видели, как это сделать в предыдущем разделе.
Общий совет для установки этой библиотеки — делать это в виртуальной среде Python без системных библиотек. Вы можете использовать виртуальную среду для создания изолированных сред Python: она создает папку, которая содержит все необходимые исполняемые файлы для использования библиотек, которые потребуются проекту Python.
Перейдите в каталог, в котором находится ваш проект, и повторно активируйте виртуальную среду venv. Затем продолжите установку openpyxl с pip, чтобы убедиться, что вы можете читать и записывать файлы с ним:
# Активируйте virtualenv
$ source activate venv
# Установим `openpyxl` в `venv`
$ pip install openpyxlТеперь, когда вы установили openpyxl, вы можете загружать данные. Но что это за данные?
Доспутим Excel с данными, которые вы пытаетесь загрузить в Python, содержит следующие листы:
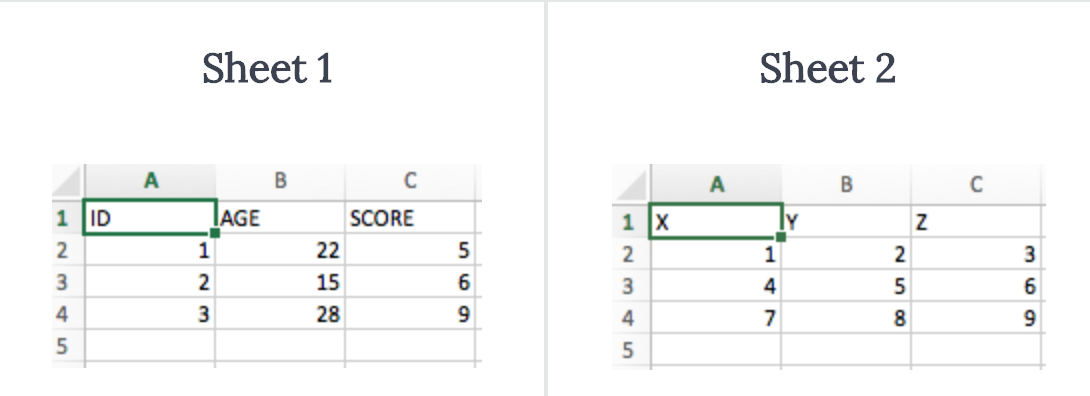
Функция load_workbook() принимает имя файла в качестве аргумента и возвращает объект рабочей книги, который представляет файл. Вы можете проверить это, запустив type (wb). Убедитесь, что вы находитесь в том каталоге, где находится ваша таблица, иначе вы получите error при импорте.
# Import `load_workbook` module from `openpyxl`
from openpyxl import load_workbook
# Load in the workbook
wb = load_workbook('./test.xlsx')
# Get sheet names
print(wb.get_sheet_names())Помните, что вы можете изменить рабочий каталог с помощью os.chdir().
Вы видите, что фрагмент кода выше возвращает имена листов книги, загруженной в Python.Можете использовать эту информацию, чтобы также получить отдельные листы рабочей книги.
Вы также можете проверить, какой лист в настоящее время активен с wb.active. Как видно из кода ниже, вы можете использовать его для загрузки другого листа из вашей книги:
# Get a sheet by name
sheet = wb.get_sheet_by_name('Sheet3')
# Print the sheet title
sheet.title
# Get currently active sheet
anotherSheet = wb.active
# Check `anotherSheet`
anotherSheetНа первый взгляд, с этими объектами рабочего листа вы не сможете многое сделать.. Однако вы можете извлечь значения из определенных ячеек на листе вашей книги, используя квадратные скобки [], в которые вы передаете точную ячейку, из которой вы хотите получить значение.
Обратите внимание, что это похоже на выбор, получение и индексирование массивов NumPy и Pandas DataFrames, но это не все, что вам нужно сделать, чтобы получить значение. Вам нужно добавить атрибут value:
# Retrieve the value of a certain cell
sheet['A1'].value
# Select element 'B2' of your sheet
c = sheet['B2']
# Retrieve the row number of your element
c.row
# Retrieve the column letter of your element
c.column
# Retrieve the coordinates of the cell
c.coordinateКак вы можете видеть, помимо значения, есть и другие атрибуты, которые вы можете использовать для проверки вашей ячейки, а именно: row, column и coordinate.
Атрибут row вернет 2;
Добавление атрибута column к c даст вам ‘B’
coordinate вернет ‘B2’.
Вы также можете получить значения ячеек с помощью функции cell(). Передайте row и column, добавьте к этим аргументам значения, соответствующие значениям ячейки, которую вы хотите получить, и, конечно же, не забудьте добавить атрибут value:
# Retrieve cell value
sheet.cell(row=1, column=2).value
# Print out values in column 2
for i in range(1, 4):
print(i, sheet.cell(row=i, column=2).value)Обратите внимание, что если вы не укажете атрибут value, вы получите <Cell Sheet3.B1>, который ничего не говорит о значении, которое содержится в этой конкретной ячейке.
Вы видите, что вы используете цикл for с помощью функции range(), чтобы помочь вам распечатать значения строк, имеющих значения в столбце 2. Если эти конкретные ячейки пусты, вы просто вернете None. Если вы хотите узнать больше о циклах for, пройдите наш курс Intermediate Python для Data Science.
Есть специальные функции, которые вы можете вызывать для получения некоторых других значений, например, get_column_letter() и column_index_from_string.
Две функции указывают примерно то, что вы можете получить, используя их, но лучше сделать их четче: хотя вы можете извлечь букву столбца с предшествующего, вы можете сделать обратное или получить адрес столбца, когда вы задаёте букву последнему. Вы можете увидеть, как это работает ниже:
# Импорт необходимых модулей из `openpyxl.utils`
from openpyxl.utils import get_column_letter, column_index_from_string
# Вывод 'A'
get_column_letter(1)
# Return '1'
column_index_from_string('A')Вы уже получили значения для строк, которые имеют значения в определенном столбце, но что вам нужно сделать, если вы хотите распечатать строки вашего файла, не сосредотачиваясь только на одном столбце? Использовать другой цикл, конечно!
Например, вы говорите, что хотите сфокусироваться на области между «А1» и «С3», где первая указывает на левый верхний угол, а вторая — на правый нижний угол области, на которой вы хотите сфокусироваться. ,
Эта область будет так называемым cellObj, который вы видите в первой строке кода ниже. Затем вы говорите, что для каждой ячейки, которая находится в этой области, вы печатаете координату и значение, которое содержится в этой ячейке. После конца каждой строки вы печатаете сообщение, которое указывает, что строка этой области cellObj напечатана.
# Напечатать строчку за строчкой
for cellObj in sheet['A1':'C3']:
for cell in cellObj:
print(cells.coordinate, cells.value)
print('--- END ---')Еще раз обратите внимание, что выбор области очень похож на выбор, получение и индексирование списка и элементов массива NumPy, где вы также используете [] и : для указания области, значения которой вы хотите получить. Кроме того, вышеприведенный цикл также хорошо использует атрибуты ячейки!
Чтобы сделать вышеприведенное объяснение и код наглядным, вы можете проверить результат, который вы получите после завершения цикла:
('A1', u'M')
('B1', u'N')
('C1', u'O')
--- END ---
('A2', 10L)
('B2', 11L)
('C2', 12L)
--- END ---
('A3', 14L)
('B3', 15L)
('C3', 16L)
--- END ---Наконец, есть некоторые атрибуты, которые вы можете использовать для проверки результата вашего импорта, а именно max_row и max_column. Эти атрибуты, конечно, и так — общие способы проверки правильности загрузки данных, но они все равно полезны.
# Вывести максимальное количество строк
sheet.max_row
# Вывести максимальное количество колонок
sheet.max_columnНаверное, вы думаете, что такой способ работы с этими файлами сложноват, особенно если вы еще хотите манипулировать данными.
Должно быть что-то попроще, верно? Так и есть!
openpyxl поддерживает Pandas DataFrames! Вы можете использовать функцию DataFrame() из библиотеки Pandas, чтобы поместить значения листа в DataFrame:
# Import `pandas`
import pandas as pd
# конвертировать Лист в DataFrame
df = pd.DataFrame(sheet.values)Если вы хотите указать заголовки и индексы, вам нужно добавить немного больше кода:
# Put the sheet values in `data`
data = sheet.values
# Indicate the columns in the sheet values
cols = next(data)[1:]
# Convert your data to a list
data = list(data)
# Read in the data at index 0 for the indices
idx = [r[0] for r in data]
# Slice the data at index 1
data = (islice(r, 1, None) for r in data)
# Make your DataFrame
df = pd.DataFrame(data, index=idx, columns=cols)Затем вы можете начать манипулировать данными со всеми функциями, которые предлагает библиотека Pandas. Но помните, что вы находитесь в виртуальной среде, поэтому, если библиотека еще не представлена, вам нужно будет установить ее снова через pip.
Чтобы записать ваши Pandas DataFrames обратно в файл Excel, вы можете легко использовать функцию dataframe_to_rows() из модуля utils:
# Import `dataframe_to_rows`
from openpyxl.utils.dataframe import dataframe_to_rows
# Initialize a workbook
wb = Workbook()
# Get the worksheet in the active workbook
ws = wb.active
# Append the rows of the DataFrame to your worksheet
for r in dataframe_to_rows(df, index=True, header=True):
ws.append(r)Но это точно не все! Библиотека openpyxl предлагает вам высокую гибкость при записи ваших данных обратно в файлы Excel, изменении стилей ячеек или использовании режима write-only. Эту библиотеку обязательно нужно знать, когда вы часто работаете с электронными таблицами ,
Совет: читайте больше о том, как вы можете изменить стили ячеек, перейти в режим write-only или как библиотека работает с NumPy здесь.
Теперь давайте также рассмотрим некоторые другие библиотеки, которые вы можете использовать для получения данных вашей электронной таблицы в Python.
Прежде чем закрыть этот раздел, не забудьте отключить виртуальную среду, когда закончите!
Чтение и форматирование Excel-файлов: xlrd
Эта библиотека идеально подходит для чтения и форматирования данных из Excel с расширением xls или xlsx.
# Import `xlrd`
import xlrd
# Open a workbook
workbook = xlrd.open_workbook('example.xls')
# Loads only current sheets to memory
workbook = xlrd.open_workbook('example.xls', on_demand = True)Когда вам не нужны данные из всей Excel-книги, вы можете использовать функции sheet_by_name() или sheet_by_index() для получения листов, которые вы хотите получить в своём анализе
# Load a specific sheet by name
worksheet = workbook.sheet_by_name('Sheet1')
# Load a specific sheet by index
worksheet = workbook.sheet_by_index(0)
# Retrieve the value from cell at indices (0,0)
sheet.cell(0, 0).valueТакже можно получить значение в определённых ячейках с вашего листа.
Перейдите к xlwt и xlutils, чтобы узнать больше о том, как они относятся к библиотеке xlrd.
Запись данных в Excel-файлы с xlwt
Если вы хотите создать таблицу со своими данными, вы можете использовать не только библиотеку XlsWriter, но и xlwt. xlwt идеально подходит для записи данных и форматирования информации в файлах с расширением .xls
Когда вы вручную создаёте файл:
# Import `xlwt`
import xlwt
# Initialize a workbook
book = xlwt.Workbook(encoding="utf-8")
# Add a sheet to the workbook
sheet1 = book.add_sheet("Python Sheet 1")
# Write to the sheet of the workbook
sheet1.write(0, 0, "This is the First Cell of the First Sheet")
# Save the workbook
book.save("spreadsheet.xls")Если вы хотите записать данные в файл, но не хотите делать все самостоятельно, вы всегда можете прибегнуть к циклу for, чтобы автоматизировать весь процесс. Составьте сценарий, в котором вы создаёте книгу и в которую добавляете лист. Укажите список со столбцами и один со значениями, которые будут заполнены на листе.
Далее у вас есть цикл for, который гарантирует, что все значения попадают в файл: вы говорите, что для каждого элемента в диапазоне от 0 до 4 (5 не включительно) вы собираетесь что-то делать. Вы будете заполнять значения построчно. Для этого вы указываете элемент строки, который появляется в каждом цикле. Далее у вас есть еще один цикл for, который будет проходить по столбцам вашего листа. Вы говорите, что для каждой строки на листе, вы будете смотреть на столбцы, которые идут с ним, и вы будете заполнять значение для каждого столбца в строке. Заполнив все столбцы строки значениями, вы перейдете к следующей строке, пока не останется строк.
# Initialize a workbook
book = xlwt.Workbook()
# Add a sheet to the workbook
sheet1 = book.add_sheet("Sheet1")
# The data
cols = ["A", "B", "C", "D", "E"]
txt = [0,1,2,3,4]
# Loop over the rows and columns and fill in the values
for num in range(5):
row = sheet1.row(num)
for index, col in enumerate(cols):
value = txt[index] + num
row.write(index, value)
# Save the result
book.save("test.xls")На скриншоте ниже представлен результат выполнения этого кода:
Теперь, когда вы увидели, как xlrd и xlwt работают друг с другом, пришло время взглянуть на библиотеку, которая тесно связана с этими двумя: xlutils.
Сборник утилит: xlutils
Эта библиотека — сборник утилит, для которого требуются и xlrd и xlwt, и которая может копировать, изменять и фильтровать существующие данные. О том, как пользоваться этими командами рассказано в разделе по openpyxl.
Вернитесь в раздел openpyxl, чтобы получить больше информации о том, как использовать этот пакет для получения данных в Python.
Использование pyexcel для чтения .xls или .xlsx файлов
Еще одна библиотека, которую можно использовать для чтения данных электронных таблиц в Python — это pyexcel; Python Wrapper, который предоставляет один API для чтения, записи и работы с данными в файлах .csv, .ods, .xls, .xlsx и .xlsm. Конечно, для этого урока вы просто сосредоточитесь на файлах .xls и .xls.
Чтобы получить ваши данные в массиве, вы можете использовать функцию get_array(), которая содержится в пакете pyexcel:
# Import `pyexcel`
import pyexcel
# Get an array from the data
my_array = pyexcel.get_array(file_name="test.xls")Вы также можете получить свои данные в упорядоченном словаре списков. Вы можете использовать функцию get_dict():
# Import `OrderedDict` module
from pyexcel._compact import OrderedDict
# Get your data in an ordered dictionary of lists
my_dict = pyexcel.get_dict(file_name="test.xls", name_columns_by_row=0)
# Get your data in a dictionary of 2D arrays
book_dict = pyexcel.get_book_dict(file_name="test.xls")Здесь видно, что если вы хотите получить словарь двумерных массивов или получить все листы рабочей книги в одном словаре, вы можете прибегнуть к get_book_dict().
Помните, что эти две структуры данных, которые были упомянуты выше, массивы и словари вашей таблицы, позволяют вам создавать DataFrames ваших данных с помощью pd.DataFrame(). Это облегчит обработку данных.
Кроме того, вы можете просто получить записи из таблицы с помощью pyexcel благодаря функции get_records(). Просто передайте аргумент file_name в функцию, и вы получите список словарей:
# Retrieve the records of the file
records = pyexcel.get_records(file_name="test.xls")Чтобы узнать, как управлять списками Python, ознакомьтесь с примерами из документации о списках Python.
Запись в файл с pyexcel
С помощью этой библиотеки можно не только загружать данные в массивы, вы также можете экспортировать свои массивы обратно в таблицу. Используйте функцию save_as() и передайте массив и имя файла назначения в аргумент dest_file_name:
# Get the data
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# Save the array to a file
pyexcel.save_as(array=data, dest_file_name="array_data.xls")Обратите внимание, что если вы хотите указать разделитель, вы можете добавить аргумент dest_delimiter и передать символ, который вы хотите использовать в качестве разделителя между «».
Однако если у вас есть словарь, вам нужно использовать функцию save_book_as(). Передайте двумерный словарь в bookdict и укажите имя файла:
# The data
2d_array_dictionary = {'Sheet 1': [
['ID', 'AGE', 'SCORE']
[1, 22, 5],
[2, 15, 6],
[3, 28, 9]
],
'Sheet 2': [
['X', 'Y', 'Z'],
[1, 2, 3],
[4, 5, 6]
[7, 8, 9]
],
'Sheet 3': [
['M', 'N', 'O', 'P'],
[10, 11, 12, 13],
[14, 15, 16, 17]
[18, 19, 20, 21]
]}
# Save the data to a file
pyexcel.save_book_as(bookdict=2d_array_dictionary, dest_file_name="2d_array_data.xls")При использовании кода, напечатанного в приведенном выше примере, важно помнить, что порядок ваших данных в словаре не будет сохранен. Если вы не хотите этого, вам нужно сделать небольшой обход. Вы можете прочитать все об этом здесь.
Чтение и запись .csv файлов
Если вы все еще ищете библиотеки, которые позволяют загружать и записывать данные в файлы .csv, кроме Pandas, лучше всего использовать пакет csv:
# import `csv`
import csv
# Read in csv file
for row in csv.reader(open('data.csv'), delimiter=','):
print(row)
# Write csv file
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
outfile = open('data.csv', 'w')
writer = csv.writer(outfile, delimiter=';', quotechar='"')
writer.writerows(data)
outfile.close()Обратите внимание, что в пакете NumPy есть функция genfromtxt(), которая позволяет загружать данные, содержащиеся в файлах .csv, в массивы, которые затем можно поместить в DataFrames.
Финальная проверка данных
Когда у вас есть данные, не забудьте последний шаг: проверить, правильно ли загружены данные. Если вы поместили свои данные в DataFrame, вы можете легко и быстро проверить, был ли импорт успешным, выполнив следующие команды:
# Check the first entries of the DataFrame
df1.head()
# Check the last entries of the DataFrame
df1.tail()Если у вас есть данные в массиве, вы можете проверить их, используя следующие атрибуты массива: shape, ndim, dtype и т.д .:
# Inspect the shape
data.shape
# Inspect the number of dimensions
data.ndim
# Inspect the data type
data.dtype
Что дальше?
Поздравляем! Вы успешно прошли наш урок и научились читать файлы Excel на Python.
Если вы хотите продолжить работу над этой темой, попробуйте воспользоваться PyXll, который позволяет писать функции в Python и вызывать их в Excel.