
In computing, a word is the natural unit of data used by a particular processor design. A word is a fixed-sized datum handled as a unit by the instruction set or the hardware of the processor. The number of bits or digits[a] in a word (the word size, word width, or word length) is an important characteristic of any specific processor design or computer architecture.
The size of a word is reflected in many aspects of a computer’s structure and operation; the majority of the registers in a processor are usually word-sized and the largest datum that can be transferred to and from the working memory in a single operation is a word in many (not all) architectures. The largest possible address size, used to designate a location in memory, is typically a hardware word (here, «hardware word» means the full-sized natural word of the processor, as opposed to any other definition used).
Documentation for older computers with fixed word size commonly states memory sizes in words rather than bytes or characters. The documentation sometimes uses metric prefixes correctly, sometimes with rounding, e.g., 65 kilowords (KW) meaning for 65536 words, and sometimes uses them incorrectly, with kilowords (KW) meaning 1024 words (210) and megawords (MW) meaning 1,048,576 words (220). With standardization on 8-bit bytes and byte addressability, stating memory sizes in bytes, kilobytes, and megabytes with powers of 1024 rather than 1000 has become the norm, although there is some use of the IEC binary prefixes.
Several of the earliest computers (and a few modern as well) use binary-coded decimal rather than plain binary, typically having a word size of 10 or 12 decimal digits, and some early decimal computers have no fixed word length at all. Early binary systems tended to use word lengths that were some multiple of 6-bits, with the 36-bit word being especially common on mainframe computers. The introduction of ASCII led to the move to systems with word lengths that were a multiple of 8-bits, with 16-bit machines being popular in the 1970s before the move to modern processors with 32 or 64 bits.[1] Special-purpose designs like digital signal processors, may have any word length from 4 to 80 bits.[1]
The size of a word can sometimes differ from the expected due to backward compatibility with earlier computers. If multiple compatible variations or a family of processors share a common architecture and instruction set but differ in their word sizes, their documentation and software may become notationally complex to accommodate the difference (see Size families below).
Uses of wordsEdit
Depending on how a computer is organized, word-size units may be used for:
- Fixed-point numbers
- Holders for fixed point, usually integer, numerical values may be available in one or in several different sizes, but one of the sizes available will almost always be the word. The other sizes, if any, are likely to be multiples or fractions of the word size. The smaller sizes are normally used only for efficient use of memory; when loaded into the processor, their values usually go into a larger, word sized holder.
- Floating-point numbers
- Holders for floating-point numerical values are typically either a word or a multiple of a word.
- Addresses
- Holders for memory addresses must be of a size capable of expressing the needed range of values but not be excessively large, so often the size used is the word though it can also be a multiple or fraction of the word size.
- Registers
- Processor registers are designed with a size appropriate for the type of data they hold, e.g. integers, floating-point numbers, or addresses. Many computer architectures use general-purpose registers that are capable of storing data in multiple representations.
- Memory–processor transfer
- When the processor reads from the memory subsystem into a register or writes a register’s value to memory, the amount of data transferred is often a word. Historically, this amount of bits which could be transferred in one cycle was also called a catena in some environments (such as the Bull GAMMA 60 [fr]).[2][3] In simple memory subsystems, the word is transferred over the memory data bus, which typically has a width of a word or half-word. In memory subsystems that use caches, the word-sized transfer is the one between the processor and the first level of cache; at lower levels of the memory hierarchy larger transfers (which are a multiple of the word size) are normally used.
- Unit of address resolution
- In a given architecture, successive address values designate successive units of memory; this unit is the unit of address resolution. In most computers, the unit is either a character (e.g. a byte) or a word. (A few computers have used bit resolution.) If the unit is a word, then a larger amount of memory can be accessed using an address of a given size at the cost of added complexity to access individual characters. On the other hand, if the unit is a byte, then individual characters can be addressed (i.e. selected during the memory operation).
- Instructions
- Machine instructions are normally the size of the architecture’s word, such as in RISC architectures, or a multiple of the «char» size that is a fraction of it. This is a natural choice since instructions and data usually share the same memory subsystem. In Harvard architectures the word sizes of instructions and data need not be related, as instructions and data are stored in different memories; for example, the processor in the 1ESS electronic telephone switch has 37-bit instructions and 23-bit data words.
Word size choiceEdit
When a computer architecture is designed, the choice of a word size is of substantial importance. There are design considerations which encourage particular bit-group sizes for particular uses (e.g. for addresses), and these considerations point to different sizes for different uses. However, considerations of economy in design strongly push for one size, or a very few sizes related by multiples or fractions (submultiples) to a primary size. That preferred size becomes the word size of the architecture.
Character size was in the past (pre-variable-sized character encoding) one of the influences on unit of address resolution and the choice of word size. Before the mid-1960s, characters were most often stored in six bits; this allowed no more than 64 characters, so the alphabet was limited to upper case. Since it is efficient in time and space to have the word size be a multiple of the character size, word sizes in this period were usually multiples of 6 bits (in binary machines). A common choice then was the 36-bit word, which is also a good size for the numeric properties of a floating point format.
After the introduction of the IBM System/360 design, which uses eight-bit characters and supports lower-case letters, the standard size of a character (or more accurately, a byte) becomes eight bits. Word sizes thereafter are naturally multiples of eight bits, with 16, 32, and 64 bits being commonly used.
Variable-word architecturesEdit
Early machine designs included some that used what is often termed a variable word length. In this type of organization, an operand has no fixed length. Depending on the machine and the instruction, the length might be denoted by a count field, by a delimiting character, or by an additional bit called, e.g., flag, or word mark. Such machines often use binary-coded decimal in 4-bit digits, or in 6-bit characters, for numbers. This class of machines includes the IBM 702, IBM 705, IBM 7080, IBM 7010, UNIVAC 1050, IBM 1401, IBM 1620, and RCA 301.
Most of these machines work on one unit of memory at a time and since each instruction or datum is several units long, each instruction takes several cycles just to access memory. These machines are often quite slow because of this. For example, instruction fetches on an IBM 1620 Model I take 8 cycles (160 μs) just to read the 12 digits of the instruction (the Model II reduced this to 6 cycles, or 4 cycles if the instruction did not need both address fields). Instruction execution takes a variable number of cycles, depending on the size of the operands.
Word, bit and byte addressingEdit
The memory model of an architecture is strongly influenced by the word size. In particular, the resolution of a memory address, that is, the smallest unit that can be designated by an address, has often been chosen to be the word. In this approach, the word-addressable machine approach, address values which differ by one designate adjacent memory words. This is natural in machines which deal almost always in word (or multiple-word) units, and has the advantage of allowing instructions to use minimally sized fields to contain addresses, which can permit a smaller instruction size or a larger variety of instructions.
When byte processing is to be a significant part of the workload, it is usually more advantageous to use the byte, rather than the word, as the unit of address resolution. Address values which differ by one designate adjacent bytes in memory. This allows an arbitrary character within a character string to be addressed straightforwardly. A word can still be addressed, but the address to be used requires a few more bits than the word-resolution alternative. The word size needs to be an integer multiple of the character size in this organization. This addressing approach was used in the IBM 360, and has been the most common approach in machines designed since then.
When the workload involves processing fields of different sizes, it can be advantageous to address to the bit. Machines with bit addressing may have some instructions that use a programmer-defined byte size and other instructions that operate on fixed data sizes. As an example, on the IBM 7030[4] («Stretch»), a floating point instruction can only address words while an integer arithmetic instruction can specify a field length of 1-64 bits, a byte size of 1-8 bits and an accumulator offset of 0-127 bits.
In a byte-addressable machine with storage-to-storage (SS) instructions, there are typically move instructions to copy one or multiple bytes from one arbitrary location to another. In a byte-oriented (byte-addressable) machine without SS instructions, moving a single byte from one arbitrary location to another is typically:
- LOAD the source byte
- STORE the result back in the target byte
Individual bytes can be accessed on a word-oriented machine in one of two ways. Bytes can be manipulated by a combination of shift and mask operations in registers. Moving a single byte from one arbitrary location to another may require the equivalent of the following:
- LOAD the word containing the source byte
- SHIFT the source word to align the desired byte to the correct position in the target word
- AND the source word with a mask to zero out all but the desired bits
- LOAD the word containing the target byte
- AND the target word with a mask to zero out the target byte
- OR the registers containing the source and target words to insert the source byte
- STORE the result back in the target location
Alternatively many word-oriented machines implement byte operations with instructions using special byte pointers in registers or memory. For example, the PDP-10 byte pointer contained the size of the byte in bits (allowing different-sized bytes to be accessed), the bit position of the byte within the word, and the word address of the data. Instructions could automatically adjust the pointer to the next byte on, for example, load and deposit (store) operations.
Powers of twoEdit
Different amounts of memory are used to store data values with different degrees of precision. The commonly used sizes are usually a power of two multiple of the unit of address resolution (byte or word). Converting the index of an item in an array into the memory address offset of the item then requires only a shift operation rather than a multiplication. In some cases this relationship can also avoid the use of division operations. As a result, most modern computer designs have word sizes (and other operand sizes) that are a power of two times the size of a byte.
Size familiesEdit
As computer designs have grown more complex, the central importance of a single word size to an architecture has decreased. Although more capable hardware can use a wider variety of sizes of data, market forces exert pressure to maintain backward compatibility while extending processor capability. As a result, what might have been the central word size in a fresh design has to coexist as an alternative size to the original word size in a backward compatible design. The original word size remains available in future designs, forming the basis of a size family.
In the mid-1970s, DEC designed the VAX to be a 32-bit successor of the 16-bit PDP-11. They used word for a 16-bit quantity, while longword referred to a 32-bit quantity; this terminology is the same as the terminology used for the PDP-11. This was in contrast to earlier machines, where the natural unit of addressing memory would be called a word, while a quantity that is one half a word would be called a halfword. In fitting with this scheme, a VAX quadword is 64 bits. They continued this 16-bit word/32-bit longword/64-bit quadword terminology with the 64-bit Alpha.
Another example is the x86 family, of which processors of three different word lengths (16-bit, later 32- and 64-bit) have been released, while word continues to designate a 16-bit quantity. As software is routinely ported from one word-length to the next, some APIs and documentation define or refer to an older (and thus shorter) word-length than the full word length on the CPU that software may be compiled for. Also, similar to how bytes are used for small numbers in many programs, a shorter word (16 or 32 bits) may be used in contexts where the range of a wider word is not needed (especially where this can save considerable stack space or cache memory space). For example, Microsoft’s Windows API maintains the programming language definition of WORD as 16 bits, despite the fact that the API may be used on a 32- or 64-bit x86 processor, where the standard word size would be 32 or 64 bits, respectively. Data structures containing such different sized words refer to them as:
- WORD (16 bits/2 bytes)
- DWORD (32 bits/4 bytes)
- QWORD (64 bits/8 bytes)
A similar phenomenon has developed in Intel’s x86 assembly language – because of the support for various sizes (and backward compatibility) in the instruction set, some instruction mnemonics carry «d» or «q» identifiers denoting «double-«, «quad-» or «double-quad-«, which are in terms of the architecture’s original 16-bit word size.
An example with a different word size is the IBM System/360 family. In the System/360 architecture, System/370 architecture and System/390 architecture, there are 8-bit bytes, 16-bit halfwords, 32-bit words and 64-bit doublewords. The z/Architecture, which is the 64-bit member of that architecture family, continues to refer to 16-bit halfwords, 32-bit words, and 64-bit doublewords, and additionally features 128-bit quadwords.
In general, new processors must use the same data word lengths and virtual address widths as an older processor to have binary compatibility with that older processor.
Often carefully written source code – written with source-code compatibility and software portability in mind – can be recompiled to run on a variety of processors, even ones with different data word lengths or different address widths or both.
Table of word sizesEdit
| key: bit: bits, c: characters, d: decimal digits, w: word size of architecture, n: variable size, wm: Word mark | |||||||
|---|---|---|---|---|---|---|---|
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| 1837 | Babbage Analytical engine |
50 d | w | — | Five different cards were used for different functions, exact size of cards not known. | w | — |
| 1941 | Zuse Z3 | 22 bit | — | w | 8 bit | w | — |
| 1942 | ABC | 50 bit | w | — | — | — | — |
| 1944 | Harvard Mark I | 23 d | w | — | 24 bit | — | — |
| 1946 (1948) {1953} |
ENIAC (w/Panel #16[5]) {w/Panel #26[6]} |
10 d | w, 2w (w) {w} |
— | — (2 d, 4 d, 6 d, 8 d) {2 d, 4 d, 6 d, 8 d} |
— — {w} |
— |
| 1948 | Manchester Baby | 32 bit | w | — | w | w | — |
| 1951 | UNIVAC I | 12 d | w | — | 1⁄2w | w | 1 d |
| 1952 | IAS machine | 40 bit | w | — | 1⁄2w | w | 5 bit |
| 1952 | Fast Universal Digital Computer M-2 | 34 bit | w? | w | 34 bit = 4-bit opcode plus 3×10 bit address | 10 bit | — |
| 1952 | IBM 701 | 36 bit | 1⁄2w, w | — | 1⁄2w | 1⁄2w, w | 6 bit |
| 1952 | UNIVAC 60 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1952 | ARRA I | 30 bit | w | — | w | w | 5 bit |
| 1953 | IBM 702 | n c | 0 c, … 511 c | — | 5 c | c | 6 bit |
| 1953 | UNIVAC 120 | n d | 1 d, … 10 d | — | — | — | 2 d, 3 d |
| 1953 | ARRA II | 30 bit | w | 2w | 1⁄2w | w | 5 bit |
| 1954 (1955) |
IBM 650 (w/IBM 653) |
10 d | w | — (w) |
w | w | 2 d |
| 1954 | IBM 704 | 36 bit | w | w | w | w | 6 bit |
| 1954 | IBM 705 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1954 | IBM NORC | 16 d | w | w, 2w | w | w | — |
| 1956 | IBM 305 | n d | 1 d, … 100 d | — | 10 d | d | 1 d |
| 1956 | ARMAC | 34 bit | w | w | 1⁄2w | w | 5 bit, 6 bit |
| 1956 | LGP-30 | 31 bit | w | — | 16 bit | w | 6 bit |
| 1957 | Autonetics Recomp I | 40 bit | w, 79 bit, 8 d, 15 d | — | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | UNIVAC II | 12 d | w | — | 1⁄2w | w | 1 d |
| 1958 | SAGE | 32 bit | 1⁄2w | — | w | w | 6 bit |
| 1958 | Autonetics Recomp II | 40 bit | w, 79 bit, 8 d, 15 d | 2w | 1⁄2w | 1⁄2w, w | 5 bit |
| 1958 | Setun | 6 trit (~9.5 bits)[b] | up to 6 tryte | up to 3 trytes | 4 trit? | ||
| 1958 | Electrologica X1 | 27 bit | w | 2w | w | w | 5 bit, 6 bit |
| 1959 | IBM 1401 | n c | 1 c, … | — | 1 c, 2 c, 4 c, 5 c, 7 c, 8 c | c | 6 bit + wm |
| 1959 (TBD) |
IBM 1620 | n d | 2 d, … | — (4 d, … 102 d) |
12 d | d | 2 d |
| 1960 | LARC | 12 d | w, 2w | w, 2w | w | w | 2 d |
| 1960 | CDC 1604 | 48 bit | w | w | 1⁄2w | w | 6 bit |
| 1960 | IBM 1410 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 bit + wm |
| 1960 | IBM 7070 | 10 d[c] | w, 1-9 d | w | w | w, d | 2 d |
| 1960 | PDP-1 | 18 bit | w | — | w | w | 6 bit |
| 1960 | Elliott 803 | 39 bit | |||||
| 1961 | IBM 7030 (Stretch) |
64 bit | 1 bit, … 64 bit, 1 d, … 16 d |
w | 1⁄2w, w | bit (integer), 1⁄2w (branch), w (float) |
1 bit, … 8 bit |
| 1961 | IBM 7080 | n c | 0 c, … 255 c | — | 5 c | c | 6 bit |
| 1962 | GE-6xx | 36 bit | w, 2 w | w, 2 w, 80 bit | w | w | 6 bit, 9 bit |
| 1962 | UNIVAC III | 25 bit | w, 2w, 3w, 4w, 6 d, 12 d | — | w | w | 6 bit |
| 1962 | Autonetics D-17B Minuteman I Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | — |
| 1962 | UNIVAC 1107 | 36 bit | 1⁄6w, 1⁄3w, 1⁄2w, w | w | w | w | 6 bit |
| 1962 | IBM 7010 | n c | 1 c, … | — | 1 c, 2 c, 6 c, 7 c, 11 c, 12 c | c | 6 b + wm |
| 1962 | IBM 7094 | 36 bit | w | w, 2w | w | w | 6 bit |
| 1962 | SDS 9 Series | 24 bit | w | 2w | w | w | |
| 1963 (1966) |
Apollo Guidance Computer | 15 bit | w | — | w, 2w | w | — |
| 1963 | Saturn Launch Vehicle Digital Computer | 26 bit | w | — | 13 bit | w | — |
| 1964/1966 | PDP-6/PDP-10 | 36 bit | w | w, 2 w | w | w | 6 bit 7 bit (typical) 9 bit |
| 1964 | Titan | 48 bit | w | w | w | w | w |
| 1964 | CDC 6600 | 60 bit | w | w | 1⁄4w, 1⁄2w | w | 6 bit |
| 1964 | Autonetics D-37C Minuteman II Guidance Computer |
27 bit | 11 bit, 24 bit | — | 24 bit | w | 4 bit, 5 bit |
| 1965 | Gemini Guidance Computer | 39 bit | 26 bit | — | 13 bit | 13 bit, 26 | —bit |
| 1965 | IBM 1130 | 16 bit | w, 2w | 2w, 3w | w, 2w | w | 8 bit |
| 1965 | IBM System/360 | 32 bit | 1⁄2w, w, 1 d, … 16 d |
w, 2w | 1⁄2w, w, 11⁄2w | 8 bit | 8 bit |
| 1965 | UNIVAC 1108 | 36 bit | 1⁄6w, 1⁄4w, 1⁄3w, 1⁄2w, w, 2w | w, 2w | w | w | 6 bit, 9 bit |
| 1965 | PDP-8 | 12 bit | w | — | w | w | 8 bit |
| 1965 | Electrologica X8 | 27 bit | w | 2w | w | w | 6 bit, 7 bit |
| 1966 | SDS Sigma 7 | 32 bit | 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1969 | Four-Phase Systems AL1 | 8 bit | w | — | ? | ? | ? |
| 1970 | MP944 | 20 bit | w | — | ? | ? | ? |
| 1970 | PDP-11 | 16 bit | w | 2w, 4w | w, 2w, 3w | 8 bit | 8 bit |
| 1971 | CDC STAR-100 | 64 bit | 1⁄2w, w | 1⁄2w, w | 1⁄2w, w | bit | 8 bit |
| 1971 | TMS1802NC | 4 bit | w | — | ? | ? | — |
| 1971 | Intel 4004 | 4 bit | w, d | — | 2w, 4w | w | — |
| 1972 | Intel 8008 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1972 | Calcomp 900 | 9 bit | w | — | w, 2w | w | 8 bit |
| 1974 | Intel 8080 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | ILLIAC IV | 64 bit | w | w, 1⁄2w | w | w | — |
| 1975 | Motorola 6800 | 8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1975 | MOS Tech. 6501 MOS Tech. 6502 |
8 bit | w, 2 d | — | w, 2w, 3w | w | 8 bit |
| 1976 | Cray-1 | 64 bit | 24 bit, w | w | 1⁄4w, 1⁄2w | w | 8 bit |
| 1976 | Zilog Z80 | 8 bit | w, 2w, 2 d | — | w, 2w, 3w, 4w, 5w | w | 8 bit |
| 1978 (1980) |
16-bit x86 (Intel 8086) (w/floating point: Intel 8087) |
16 bit | 1⁄2w, w, 2 d | — (2w, 4w, 5w, 17 d) |
1⁄2w, w, … 7w | 8 bit | 8 bit |
| 1978 | VAX | 32 bit | 1⁄4w, 1⁄2w, w, 1 d, … 31 d, 1 bit, … 32 bit | w, 2w | 1⁄4w, … 141⁄4w | 8 bit | 8 bit |
| 1979 (1984) |
Motorola 68000 series (w/floating point) |
32 bit | 1⁄4w, 1⁄2w, w, 2 d | — (w, 2w, 21⁄2w) |
1⁄2w, w, … 71⁄2w | 8 bit | 8 bit |
| 1985 | IA-32 (Intel 80386) (w/floating point) | 32 bit | 1⁄4w, 1⁄2w, w | — (w, 2w, 80 bit) |
8 bit, … 120 bit 1⁄4w … 33⁄4w |
8 bit | 8 bit |
| 1985 | ARMv1 | 32 bit | 1⁄4w, w | — | w | 8 bit | 8 bit |
| 1985 | MIPS I | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1991 | Cray C90 | 64 bit | 32 bit, w | w | 1⁄4w, 1⁄2w, 48 bit | w | 8 bit |
| 1992 | Alpha | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| 1992 | PowerPC | 32 bit | 1⁄4w, 1⁄2w, w | w, 2w | w | 8 bit | 8 bit |
| 1996 | ARMv4 (w/Thumb) |
32 bit | 1⁄4w, 1⁄2w, w | — | w (1⁄2w, w) |
8 bit | 8 bit |
| 2000 | IBM z/Architecture (w/vector facility) |
64 bit | 1⁄4w, 1⁄2w, w 1 d, … 31 d |
1⁄2w, w, 2w | 1⁄4w, 1⁄2w, 3⁄4w | 8 bit | 8 bit, UTF-16, UTF-32 |
| 2001 | IA-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 41 bit (in 128-bit bundles)[7] | 8 bit | 8 bit |
| 2001 | ARMv6 (w/VFP) |
32 bit | 8 bit, 1⁄2w, w | — (w, 2w) |
1⁄2w, w | 8 bit | 8 bit |
| 2003 | x86-64 | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w, 80 bit | 8 bit, … 120 bit | 8 bit | 8 bit |
| 2013 | ARMv8-A and ARMv9-A | 64 bit | 8 bit, 1⁄4w, 1⁄2w, w | 1⁄2w, w | 1⁄2w | 8 bit | 8 bit |
| Year | Computer architecture |
Word size w | Integer sizes |
Floatingpoint sizes |
Instruction sizes |
Unit of address resolution |
Char size |
| key: bit: bits, d: decimal digits, w: word size of architecture, n: variable size |
[8][9]
See alsoEdit
- Integer (computer science)
NotesEdit
- ^ Many early computers were decimal, and a few were ternary
- ^ The bit equivalent is computed by taking the amount of information entropy provided by the trit, which is . This gives an equivalent of about 9.51 bits for 6 trits.
- ^ Three-state sign
ReferencesEdit
- ^ a b Beebe, Nelson H. F. (2017-08-22). «Chapter I. Integer arithmetic». The Mathematical-Function Computation Handbook — Programming Using the MathCW Portable Software Library (1 ed.). Salt Lake City, UT, USA: Springer International Publishing AG. p. 970. doi:10.1007/978-3-319-64110-2. ISBN 978-3-319-64109-6. LCCN 2017947446. S2CID 30244721.
- ^ Dreyfus, Phillippe (1958-05-08) [1958-05-06]. Written at Los Angeles, California, USA. System design of the Gamma 60 (PDF). Western Joint Computer Conference: Contrasts in Computers. ACM, New York, NY, USA. pp. 130–133. IRE-ACM-AIEE ’58 (Western). Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Internal data code is used: Quantitative (numerical) data are coded in a 4-bit decimal code; qualitative (alpha-numerical) data are coded in a 6-bit alphanumerical code. The internal instruction code means that the instructions are coded in straight binary code.
As to the internal information length, the information quantum is called a «catena,» and it is composed of 24 bits representing either 6 decimal digits, or 4 alphanumerical characters. This quantum must contain a multiple of 4 and 6 bits to represent a whole number of decimal or alphanumeric characters. Twenty-four bits was found to be a good compromise between the minimum 12 bits, which would lead to a too-low transfer flow from a parallel readout core memory, and 36 bits or more, which was judged as too large an information quantum. The catena is to be considered as the equivalent of a character in variable word length machines, but it cannot be called so, as it may contain several characters. It is transferred in series to and from the main memory.
Not wanting to call a «quantum» a word, or a set of characters a letter, (a word is a word, and a quantum is something else), a new word was made, and it was called a «catena.» It is an English word and exists in Webster’s although it does not in French. Webster’s definition of the word catena is, «a connected series;» therefore, a 24-bit information item. The word catena will be used hereafter.
The internal code, therefore, has been defined. Now what are the external data codes? These depend primarily upon the information handling device involved. The Gamma 60 [fr] is designed to handle information relevant to any binary coded structure. Thus an 80-column punched card is considered as a 960-bit information item; 12 rows multiplied by 80 columns equals 960 possible punches; is stored as an exact image in 960 magnetic cores of the main memory with 2 card columns occupying one catena. […] - ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips; Buchholz, Werner (1962). «4: Natural Data Units» (PDF). In Buchholz, Werner (ed.). Planning a Computer System – Project Stretch. McGraw-Hill Book Company, Inc. / The Maple Press Company, York, PA. pp. 39–40. LCCN 61-10466. Archived (PDF) from the original on 2017-04-03. Retrieved 2017-04-03.
[…] Terms used here to describe the structure imposed by the machine design, in addition to bit, are listed below.
Byte denotes a group of bits used to encode a character, or the number of bits transmitted in parallel to and from input-output units. A term other than character is used here because a given character may be represented in different applications by more than one code, and different codes may use different numbers of bits (i.e., different byte sizes). In input-output transmission the grouping of bits may be completely arbitrary and have no relation to actual characters. (The term is coined from bite, but respelled to avoid accidental mutation to bit.)
A word consists of the number of data bits transmitted in parallel from or to memory in one memory cycle. Word size is thus defined as a structural property of the memory. (The term catena was coined for this purpose by the designers of the Bull GAMMA 60 [fr] computer.)
Block refers to the number of words transmitted to or from an input-output unit in response to a single input-output instruction. Block size is a structural property of an input-output unit; it may have been fixed by the design or left to be varied by the program. […] - ^ «Format» (PDF). Reference Manual 7030 Data Processing System (PDF). IBM. August 1961. pp. 50–57. Retrieved 2021-12-15.
- ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC (Electronic Numerical Integrator and Computer)». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Report No. 673; Project No. TB3-0007 of the Research and Development Division, Ordnance Department. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ Clippinger, Richard F. [in German] (1948-09-29). «A Logical Coding System Applied to the ENIAC». Aberdeen Proving Ground, Maryland, US: Ballistic Research Laboratories. Section VIII: Modified ENIAC. Retrieved 2017-04-05.
{{cite web}}: CS1 maint: url-status (link) - ^ «4. Instruction Formats» (PDF). Intel Itanium Architecture Software Developer’s Manual. Vol. 3: Intel Itanium Instruction Set Reference. p. 3:293. Retrieved 2022-04-25.
Three instructions are grouped together into 128-bit sized and aligned containers called bundles. Each bundle contains three 41-bit instruction slots and a 5-bit template field.
- ^ Blaauw, Gerrit Anne; Brooks, Jr., Frederick Phillips (1997). Computer Architecture: Concepts and Evolution (1 ed.). Addison-Wesley. ISBN 0-201-10557-8. (1213 pages) (NB. This is a single-volume edition. This work was also available in a two-volume version.)
- ^ Ralston, Anthony; Reilly, Edwin D. (1993). Encyclopedia of Computer Science (3rd ed.). Van Nostrand Reinhold. ISBN 0-442-27679-6.
In computer architecture, word addressing means that addresses of memory on a computer uniquely identify words of memory. It is usually used in contrast with byte addressing, where addresses uniquely identify bytes. Almost all modern computer architectures use byte addressing, and word addressing is largely only of historical interest. A computer that uses word addressing is sometimes called a word machine.

Tables showing the same data organized under byte and word addressing
Basics[edit]
Consider a computer which provides 524,288 (219) bits of memory. If that memory is arranged in a byte-addressable flat address space using 8-bit bytes, then there are 65,536 (216) valid addresses, from 0 to 65,535, each denoting an independent 8 bits of memory. If instead it is arranged in a word-addressable flat address space using 32-bit words, then there are 16,384 (214) valid addresses, from 0 to 16,383, each denoting an independent 32 bits.
More generally, the minimum addressable unit (MAU) is a property of a specific memory abstraction. Different abstractions within a computer may use different MAUs, even when they are representing the same underlying memory. For example, a computer might use 32-bit addresses with byte addressing in its instruction set, but the CPU’s cache coherence system might work with memory only at a granularity of 64-byte cache lines, allowing any particular cache line to be identified with only a 26-bit address and decreasing the overhead of the cache.
The address translation done by virtual memory often affects the structure and width of the address space, but it does not change the MAU.
Trade-offs of different minimum addressable units[edit]
The size of the minimum addressable unit of memory can have complex trade-offs. Using a larger MAU allows the same amount of memory to be covered with a smaller address, which can substantially decrease the memory requirements of a program. However, using a smaller MAU makes it easier to work efficiently with small items of data.
Suppose a program wishes to store one of the 12 traditional signs of Western astrology. A single sign can be stored in 4 bits. If a sign is stored in its own MAU, then 4 bits will be wasted with byte addressing (50% efficiency), while 28 bits will be wasted with 32-bit word addressing (12.5% efficiency). If a sign is «packed» into a MAU with other data, then it may be relatively more expensive to read and write. For example, to write a new sign into a MAU that other data has been packed into, the computer must read the current value of the MAU, overwrite just the appropriate bits, and then store the new value back. This will be especially expensive if it is necessary for the program to allow other threads to concurrently modify the other data in the MAU.
A more common example is a string of text. Common string formats such as UTF-8 and ASCII store strings as a sequence of 8-bit code points. With byte addressing, each code point can be placed in its own independently-addressable MAU with no overhead. With 32-bit word addressing, placing each code point in a separate MAU would increase the memory usage by 300%, which is not viable for programs that work with large amounts of text. Packing adjacent code points into a single word avoids this cost. However, many algorithms for working with text prefer to be able to independently address code points; to do this with packed code points, the algorithm must use a «wide» address which also stores the offset of the character within the word. If this wide address needs to be stored elsewhere within the program’s memory, it may require more memory than an ordinary address.
To evaluate these effects on a complete program, consider a web browser displaying a large and complex page. Some of the browser’s memory will be used to store simple data such as images and text; the browser will likely choose to store this data as efficiently as possible, and it will occupy about the same amount of memory regardless of the size of the MAU. Other memory will represent the browser’s model of various objects on the page, and these objects will include many references: to each other, to the image and text data, and so on. The amount of memory needed to store these object will depend greatly on the address width of the computer.
Suppose that, if all the addresses in the program were 32-bit, this web page would occupy about 10 Gigabytes of memory.
- If the web browser is running on a computer with 32-bit addresses and byte-addressable memory, the address space will cover 4 Gigabytes of memory, which is insufficient. The browser will either be unable to display this page, or it will need to be able to opportunistically move some of the data to slower storage, which will substantially hurt its performance.
- If the web browser is running on a computer with 64-bit addresses and byte-addressable memory, it will require substantially more memory in order to store the larger addresses. The exact overhead will depend on how much of the 10 Gigabytes is simple data and how much is object-like and dense with references, but a figure of 40% is not implausible, for a total of 14 Gigabytes required. This is, of course, well within the capabilities of a 64-bit address space. However, the browser will generally exhibit worse locality and make worse use of the computer’s memory caches within the computer, assuming equal resources with the alternatives.
- If the web browser is running on a computer with 32-bit addresses and 32-bit-word-addressable memory, it will likely require extra memory because of suboptimal packing and the need for a few wide addresses. This impact is likely to be relatively small, as the browser will use packing and non-wide addresses for most important purposes, and the browser will fit comfortably within the maximum addressable range of 16 Gigabytes. However, there may be a significant runtime overhead due to the widespread use of packed data for images and text. More importantly, 16 Gigabytes is a relatively low limit, and if the web page grows significantly, this computer will exhaust its address space and begin to have some of the same difficulties as the byte-addressed computer.
- If the web browser is running on a computer with 64-bit addresses and 32-bit-word-addressable memory, it will suffer from both of the above runtime overheads: it require substantially more memory to accommodate the larger 64-bit addresses, hurting locality, while also incurring the runtime overhead of working with extensive packing of text and image data. Word addressing means that the program can theoretically address up to 64 Exabytes of memory instead of only 16 Exabytes, but since the program is nowhere near needing this much memory (and in practice no real computer is capable of providing it), this provides no benefit.
Thus, word addressing allows a computer to address substantially more memory without increasing its address width and incurring the corresponding large increase in memory usage. However, this is valuable only within a relatively narrow range of working set sizes, and it can introduce substantial runtime overheads depending on the application. Programs which do relatively little work with byte-oriented data like images, text, files, and network traffic may be able to benefit most.
Sub-word accesses and wide addresses[edit]
A program running on a computer that uses word addressing can still work with smaller units of memory by emulating an access to the smaller unit. For a load, this requires loading the enclosing word and then extracting the desired bits. For a store, this requires loading the enclosing word, shifting the new value into place, overwriting the desired bits, and then storing the enclosing word.
Suppose that four consecutive code points from a UTF-8 string need to be packed into a 32-bit word. The first code point might occupy bits 0–7, the second 8-15, the third 16–23, and the fourth 24–31. (If the memory were byte-addressable, this would be a little endian byte order.)
In order to clearly elucidate the code necessary for sub-word accesses without tying the example too closely to any particular word-addressed architecture, the following examples use MIPS assembly. In reality, MIPS is a byte-addressed architecture with direct support for loading and storing 8-bit and 16-bit values, but the example will pretend that it only provides 32-bit loads and stores and that offsets within a 32-bit word must be stored separately from an address. MIPS has been chosen because it is a simple assembly language with no specialized facilities that would make these operations more convenient.
Suppose that a program wishes to read the third code point into register r1 from the word at an address in register r2. In the absence of any other support from the instruction set, the program must load the full word, right-shift by 16 to drop the first two code points, and then mask off the fourth code point:
ldw $r1, 0($r2) # Load the full word srl $r1, $r1, 16 # Shift right by 16 andi $r1, $r1, 0xFF # Mask off other code points
If the offset is not known statically, but instead a bit-offset is stored in the register r3, a slightly more complex approach is required:
ldw $r1, 0($r2) # Load the full word srlv $r1, $r1, $r3 # Shift right by the bit offset andi $r1, $r1, 0xFF # Mask off other code points
Suppose instead that the program wishes to assign the code point in register r1 to the third code point in the word at the address in r2. In the absence of any other support from the instruction set, the program must load the full word, mask off the old value of that code point, shift the new value into place, merge the values, and store the full word back:
sll $r1, $r1, 16 # Shift the new value left by 16 lhi $r5, 0x00FF # Construct a constant mask to select the third byte nor $r5, $r5, $zero # Flip the mask so that it clears the third byte ldw $r4, 0($r2) # Load the full word and $r4, $r5, $r4 # Clear the third byte from the word or $r4, $r4, $r1 # Merge the new value into the word stw $r4, 0($r2) # Store the result as the full word
Again, if the offset is instead stored in r3, a more complex approach is required:
sllv $r1, $r1, $r3 # Shift the new value left by the bit offset llo $r5, 0x00FF # Construct a constant mask to select a byte sllv $r5, $r5, $r3 # Shift the mask left by the bit offset nor $r5, $r5, $zero # Flip the mask so that it clears the selected byte ldw $r4, 0($r2) # Load the full word and $r4, $r5, $r4 # Clear the selected byte from the word or $r4, $r4, $r1 # Merge the new value into the word stw $r4, 0($r2) # Store the result as the full word
This code sequence assumes that another thread cannot modify other bytes in the word concurrently. If concurrent modification is possible, then one of the modifications might be lost. To solve this problem, the last few instructions must be turned into an atomic compare-exchange loop so that a concurrent modification will simply cause it to repeat the operation with the new value. No memory barriers are required in this case.
A pair of a word address and an offset within the word is called a wide address (also known as a fat address or fat pointer). (This should not be confused with other uses of wide addresses for storing other kinds of supplemental data, such as the bounds of an array.) The stored offset may be either a bit offset or a byte offset. The code sequences above benefit from the offset being denominated in bits because they use it as a shift count; an architecture with direct support for selecting bytes might prefer to just store a byte offset.
In these code sequences, the additional offset would have to be stored alongside the base address, effectively doubling the overall storage requirements of an address. This is not always true on word machines, primarily because addresses themselves are often not packed with other data to make accesses more efficient. For example, the Cray X1 uses 64-bit words, but addresses are only 32 bits; when an address is stored in memory, it is stored in its own word, and so the byte offset can be placed in the upper 32 bits of the word. The inefficiency of using wide addresses on that system is just all the extra logic to manipulate this offset and extract and insert bytes within words; it has no memory-use impact.
[edit]
The minimum addressable unit of a computer isn’t necessarily the same as the minimum memory access size of the computer’s instruction set. For example, a computer might use byte addressing without providing any instructions to directly read or write a single byte. Programs would be expected to emulate those operations in software with bit-manipulations, just like the example code sequences above do. This is relatively common in 64-bit computer architectures designed as successors to 32-bit supercomputers or minicomputers, such the DEC Alpha and the Cray X1.
The C standard states that a pointer is expected to have the usual representation of an address. C also allows a pointer to be formed to any object except a bit-field; this includes each individual element of an array of bytes. C compilers for computers that use word addressing often use different representations for pointers to different types depending on their size. A pointer to a type that’s large enough to fill a word will be a simple address, while a pointer such as char* or void* will be a wide pointer: a pair of the address of a word and the offset of a byte within that word. Converting between pointer types is therefore not necessarily a trivial operation and can lose information if done incorrectly.
Because the size of a C struct is not always known when deciding the representation of a pointer to that struct, it is not possible to reliably apply the rule above. Compilers may need to align the start of a struct so that it can use a more efficient pointer representation.
Examples[edit]
- The ERA 1103 uses word addressing with 36-bit words. Only addresses 0-1023 refer to random-access memory; others are either unmapped or refer to drum memory.
- The PDP-10 uses word addressing with 36-bit words and 18-bit addresses.
- Most Cray supercomputers from the 1980s and 1990s use word addressing with 64-bit words. The Cray-1 and Cray X-MP use 24-bit addresses, while most others use 32-bit addresses.
- The Cray X1 uses byte addressing with 64-bit addresses. It does not directly support memory accesses smaller than 64 bits, and such accesses must be emulated in software. The C compiler for the X1 was the first Cray compiler to support emulating 16-bit accesses.[1]
- The DEC Alpha uses byte addressing with 64-bit addresses. Early Alpha processors do not provide any direct support for 8-bit and 16-bit memory accesses, and programs are required to e.g. load a byte by loading the containing 64-bit word and then separately extracting the byte. Because the Alpha uses byte addressing, this offset is still represented in the least significant bits of the address (rather than separately as a wide address), and the Alpha conveniently provides load and store unaligned instructions (
ldq_uandstq_u) which ignore those bits and simply load and store the containing aligned word.[2] The later byte-word extensions to the architecture (BWX) added 8-bit and 16-bit loads and stores, starting with the Alpha 21164a.[3] Again, this extension was possible without serious software incompatibilities because the Alpha had always used byte addressing.
See also[edit]
- Byte addressing
References[edit]
- ^ Terry Greyzck, Cray Inc. Cray X1 Compiler Challenges (And How We Solved Them)
- ^ «The Alpha AXP, part 8: Memory access, storing bytes and words and unaligned data». 16 August 2017.
- ^ «Alpha: The History in Facts and Comments — Alpha 21164 (EV5, EV56) and 21164PC (PCA56, PCA57)».
3.2.
Регистры процессора
Как
уже упоминалось, внутренние регистры
процессора представляют собой
сверхоперативную память небольшого
размера, которая предназначена для
временного хранения служебной
информации или данных. Количество
регистров в разных процессорах может
быть от 6—8 до нескольких десятков.
Регистры могут быть универсальными
и специализированными. Специализированные
регистры, которые присутствуют в
большинстве процессоров, — это регистр-
счетчик
команд,
регистр
состояния
( PSW
), регистр
указателя
стека. Остальные регистры процессора
могут быть как универсальными, так и
специализированными.
Например,
в 16-разрядном процессоре Т-11 фирмы DEC
было 8 регистров общего назначения
(РОН) и один регистр
состояния.
Все регистры имели по 16 разрядов. Из
регистров общего назначения один
отводился под счетчик
команд,
другой — под указатель стека. Все
остальные регистры общего назначения
полностью взаимозаменяемы, то есть
имеют универсальное назначение, могут
хранить как данные, так и адреса
(указатели), индексы и т.д. Максимально
допустимый объем памяти для данного
процессора составлял 64 Кбайт (адрес
памяти 16-разрядный).
В
16-разрядном процессоре MC68000 фирмы
Motorola было 19 регистров: 16-разрядный
регистр
состояния,
32-разрядный регистр счетчика
команд,
9 регистров адреса (32-разрядных) и 8
регистров данных (32-разрядных). Два
регистра адреса отведены под указатели
стека. Максимально допустимый объем
адресуемой памяти — 16 Мбайт (внешняя
шина адреса 24-разрядная). Все 8 регистров
данных взаимозаменяемы. 7 регистров
адреса – тоже взаимозаменяемы.
В
16-разрядном процессоре Intel 8086, который
стал базовым в линии процессоров,
используемых в персональных компьютерах,
реализован принципиально другой
подход. Каждый регистр этого процессора
имеет свое особое назначение, и заменять
друг друга регистры могут только
частично или же не могут вообще.
Остановимся на особенностях этого
процессора подробнее.
Процессор
8086 имеет 14 регистров разрядностью по
16 бит. Из них четыре регистра ( AX,
BX,
CX,
DX
) — это регистры данных, каждый из
которых помимо хранения операндов
и результатов операций имеет еще и
свое специфическое назначение:
-
регистр
AX
— умножение, деление, обмен с
устройствами ввода/вывода (команды
ввода и вывода); -
регистр
BX
— базовый регистр в вычислениях
адреса; -
регистр
CX
— счетчик циклов; -
регистр
DX
— определение адреса ввода/вывода.
Для
регистров данных существует возможность
раздельного использования обоих
байтов (например, для регистра AX
они имеют обозначения AL
– младший байт и AH
— старший байт).
Следующие
четыре внутренних регистра процессора
— это сегментные регистры, каждый из
которых определяет положение одного
из рабочих сегментов (рис.
3.10):
-
регистр
CS
(Code Segment) соответствует сегменту
команд, исполняемых в данный момент; -
регистр
DS
(Data Segment) соответствует сегменту
данных, с которыми работает процессор; -
регистр
ES
(Extra Segment) соответствует дополнительному
сегменту данных; -
регистр
SS
(Stack Segment) соответствует сегменту
стека.

Рис.
3.10.
Сегменты команд, данных и стека в
памяти.
В
принципе, все эти сегменты могут и
перекрываться для оптимального
использования пространства памяти.
Например, если программа занимает
только часть сегмента, то сегмент
данных может начинаться сразу после
завершения работы программы (с точностью
16 байт), а не после окончания всего
сегмента программы.
Следующие
пять регистров процессора ( SP
— Stack Pointer, BP
— Base Pointer, SI
— Source Index, DI
— Destination Index, IP
—Instruction Pointer) служат указателями (то
есть определяют смещение в пределах
сегмента). Например, счетчик
команд
процессора образуется парой регистров
CS
и IP,
а указатель стека — парой регистров
SP
и SS.
Регистры SI,
DI
используются в строковых операциях,
то есть при последовательной обработке
нескольких ячеек памяти одной командой.
Последний
регистр FLAGS
— это регистр
состояния
процессора ( PSW
). Из его 16 разрядов используются только
девять (рис.
3.11):
CF
(Carry Flag) — флаг переноса при арифметических
операциях, PF
(Parity Flag) — флаг четности результата,
AF
(Auxiliary Flag) — флаг дополнительного
переноса, ZF
(Zero Flag) — флаг нулевого результата, SF
(Sign Flag) — флаг знака (совпадает со
старшим битом результата), TF
(Trap Flag) — флаг пошагового режима
(используется при отладке), IF
(Interrupt-enable Flag) — флаг разрешения
аппаратных прерываний, DF
(Direction Flag) — флаг направления при
строковых операциях, OF
(Overflow Flag) — флаг переполнения.

Рис.
3.11.
Регистр состояния процессора 8086.
Биты
регистра состояния устанавливаются
или очищаются в зависимости от
результата исполнения предыдущей
команды и используются некоторыми
командами процессора. Биты регистра
состояния могут также устанавливаться
и очищаться специальными командами
процессора (о системе команд процессора
будет рассказано в следующем разделе).
Во
многих процессорах выделяется
специальный регистр, называемый
аккумулятором
(то есть накопителем). При этом, как
правило, только этот регистр-аккумулятор
может участвовать во всех операциях,
только через него может производиться
взаимодействие с устройствами
ввода/вывода. Иногда в него же помещается
результат любой выполненной команды
(в этом случае говорят даже об
«аккумуляторной» архитектуре
процессора). Например, в процессоре
8086 регистр данных АХ можно считать
своеобразным аккумулятором, так как
именно он обязательно участвует в
командах умножения и деления, а также
только через него можно пересылать
данные в устройство ввода/вывода и из
устройства ввода/вывода. Выделение
специального регистра-аккумулятора
упрощает структуру процессора и
ускоряет пересылки кодов внутри
процессора, но в некоторых случаях
замедляет работу системы в целом, так
как весь поток информации должен
пройти через один регистр-аккумулятор.
В случае, когда несколько регистров
процессора полностью взаимозаменяемы,
таких проблем не возникает.
Memory locations and addresses determine how the computer’s memory is organized so that the user can efficiently store or retrieve information from the computer. The computer’s memory is made of a silicon chip which has millions of storage cell, where each storage cell is capable to store a bit of information which value is either 0 or 1.
But the fact is, computer memory holds instructions and data. And a single bit is very small to hold this information so bits are rarely used individually. As a solution to this, the bits are grouped in fixed sizes of n bits. The memory of the computer is organized in such a way that the group of these n bits can be stored and retrieved easily by the computer in a single operation.
The group of n bit is termed as word where n is termed as the word length. The word length of the computer has evolved from 8, 16, 24, 32 to 64 bits. General-purpose computers nowadays have 32 to 64 bits. The group of 8 bit is called a byte.
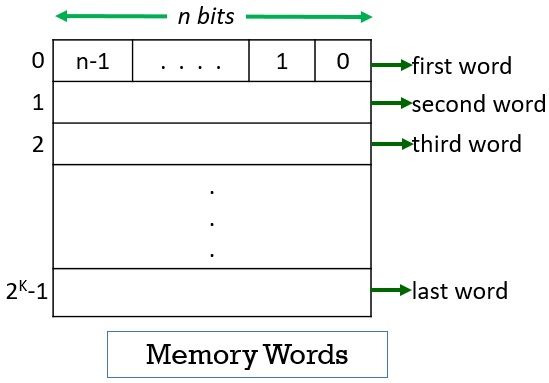
Now, whenever you want to store any instruction or data may it be of a byte or a word you have to access a memory location. To access the memory location either you must know the memory location by its unique name or it is required to provide a unique address to each memory location.
The memory locations are addressed from 0 to 2K-1 i.e. a memory has 2K addressable locations. And thus the address space of the computer has 2K addresses. Let us try some suitable values for K.
210 = 1024 = 1K (Kilobyte)
220 = 1,048,576 = 1M (Megabyte)
230 = 1073741824 = 1G (Gigabyte)
240 = 1.0995116e+12 = 1T (Terabyte)
Byte Addressability
Till now we have gone through three information storing quantities bit, byte and word. We have seen above that 8 bits together form a byte and this is the fix for every memory. But the word length varies from memory to memory and it ranges from 16 to 64 bit.
Well, it is impossible to allot a unique address to each bit in memory. As a solution, most modern computers assign successive addresses to successive byte locations in memory. This assignment of addresses to individual byte locations is termed byte addressability and memory is referred to as byte-addressable memory.
If we assign an address to individual byte locations in the memory like 0, 1, 2, 3…. .Now if the word length of the machine is 16 bit then the successive words are located at addresses 0, 2, 4, 6… where each word would have 2 bytes of information. Similarly, if we have a machine with a word length of 32 bit then the successive words are located at the addresses 0, 4, 8, 12… where each word would have 4 bytes of information and it could store or retrieve 4 bytes of instruction or data in a single and basic operation.
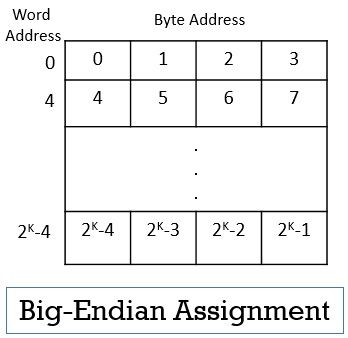
Big-Endian and Little-Endian Assignments in Byte Addresses
The big-endian and little-endian are two methods of assigning byte addresses across the words in the memory. In the big-endian assignment, the lower byte addresses are used for the leftmost bytes of the word. Observe the word 0 in the image below, the leftmost bytes of the word have lower byte addresses.
In the little-endian assignment, the lower byte addresses are used for the rightmost bytes of the word. Observe the word 0 in the image below the rightmost bytes of word 0 has lower byte addresses.
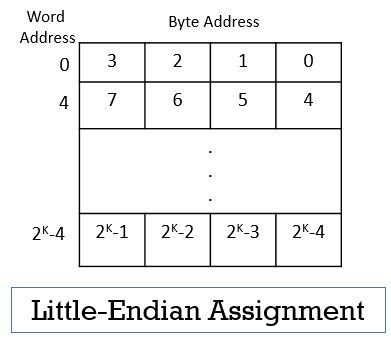
The leftmost bytes of the word are termed as most significant bytes and the rightmost bytes of the words are termed as least significant bytes.
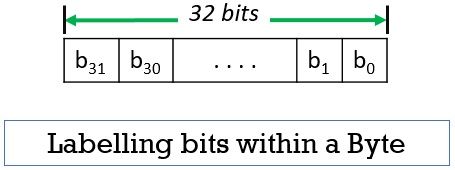
Thus the big-endian and little-endian specify the ordering of bytes inside a word. Similarly, the bits must be labelled inside the byte or a word and the most common way of labelling bits in a byte or word is as shown in the figure below i.e. labelling the bits as b7, b6,…….,b1, b0 from left to write as we do in little-endian assignment.
Word Alignment
In a machine with word length 32-bit, the word boundaries occur at the bytes addresses 0, 4, 8… It is said that the word has aligned addresses if they begin with the byte address that is multiple of the number of bytes present in that word. For example, the word address 4 has four bytes in it with byte address 4, 5 and 6. The word address 4 starts with the byte address 4 which is multiple of the number of bytes in word 4.
In case if the word address begins with the arbitrary byte address the word is said to have unaligned addresses. But conventionally the words have aligned addresses as this lets the access of memory operand more efficiently.
So, this is all about the memory locations and how they are addressed to store and retrieve the instructions or data more efficiently. With memory addresses, it becomes easy to identify a specific memory location.
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
Memory is a storage component in the Computer used to store application programs. The Memory Chip is divided into equal parts called as “CELLS”. Each Cell is uniquely identified by a binary number called as “ADDRESS”. For example, the Memory Chip configuration is represented as ’64 K x 8′ as shown in the figure below.

The following information can be obtained from the memory chip representation shown above:
1. Data Space in the Chip = 64K X 8
2. Data Space in the Cell = 8 bits
3. Address Space in the Chip = log_{2} (64 K) =16 bits
Now we can clearly state the difference between Byte Addressable Memory & Word Addressable Memory.
| S. No. | Byte Addressable Memory | Word Addressable Memory |
|---|---|---|
| 1. | When the data space in the cell = 8 bits then the corresponding address space is called as Byte Address. | When the data space in the cell = word length of CPU then the corresponding address space is called as Word Address. |
| 2. | Based on this data storage i.e. Bytewise storage, the memory chip configuration is named as Byte Addressable Memory. | Based on this data storage i.e. Wordwise storage, the memory chip configuration is named as Word Addressable Memory. |
| 3. | For eg. : 64K X 8 chip has 16 bit Address and cell size = 8 bits (1 Byte) which means that in this chip, data is stored byte by byte. | For eg. : For a 16-bit CPU, 64K X 16 chip has 16 bit Address & cell size = 16 bits (Word Length of CPU) which means that in this chip, data is stored word by word. |
| 4. | It is suitable for the processes that require data comprising single byte at a time. A single address is issued for accessing a single byte in byte addressable memory. | In case of word addressable memory, the necessary condition involves computing the address of word that contains required byte, fetch that word and then extraction of needed byte from the two byte word takes place. So, it is indirectly accessible. Hence, modern machines are byte addressable. |
NOTE :
i) The most important point to be noted is that in case of either of Byte Address or Word Address, the address size can be any number of bits (depends on the number of cells in the chip) but the cell size differs in each case.
ii)The default memory configuration in the Computer design is Byte Addressable .
Like Article
Save Article